一种基于大数据的用水量预测方法及装置与流程
本发明涉及用水量预测技术领域,具体涉及一种基于大数据的用水量预测方法及装置。
背景技术:
由于人口过多,用水的速度远远快于环境的自净速度,从而导致淡水资源匮缺,被列入不可再生资源。随着经济的快速发展,城乡居民的生产用水和居民用水的需求越来越大,使得水量预测工作成为水资源管理中掌握未来发展趋势的关键。而合理的预测城乡规划期限内的用水量,使其与城乡发展实际相接近,对城乡今后的建设和发展具有极其重要的意义。通过预测未来的用水量,一方面,我们可以大致估计城市和农村的缺水量,着手寻求解决方案,实现水资源的合理调度,减少经济损失。另一方面,用水量预测是水资源管理规划的重要内容。如不做好用水量预测,我国就难以制定中长期水资源开发利用的总体规划和供水规划,就会影响国民经济计划的实现。
现有的技术中只单一地采用主成分分析法对特征进行选取,选取贡献值达到一定程度的影响因素来进行预测,这样的做法虽然比起原始的做法方便快捷许多,但是当影响因素绝大部分与因变量关系比较密切时,通过主成分分析法筛选出来的特征仍然很多,这样的话,就不能达到想要通过该方法使得运算量减少的效果。
对一个事件结果的预测具有高贡献值的影响因素往往有很多,若只依靠主成分分析法来缩小影响因素选取范围,这无疑对减少计算负担起不了多大的作用。
1996年roberttibshirani首次提出lasso算法,全称leastabsoluteshrinkageandselectionoperator,译为最小绝对值收敛和选择算子、套索算法,该方法是一种压缩估计,它通过构造一个惩罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零,因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
在运用主成分分析法的基础上,再套用lasso算法,可以显著提高预测精度;主成分跟lasso相结合本质上就是原本因子的线性组合,如果原本因子取值幅度差不多,产生的主成分哪怕幅度不同,也可以进行一定的压缩,使之幅度差不多,但方向不变,所以还是垂直的;然后就可以用这些主成分进行回归,再套用lasso把系数取值小的删掉,这样效果会更好,因为这进一步降低了对因子质量的要求。
而如何结合现有技术更加精准高效地预测用水量成为值得深入研究的问题。
技术实现要素:
本发明提供一种基于大数据的用水量预测方法及装置,能够大幅度提高用水量的预测精度的同时在更短的时间内预测出用水量。
本发明提供的一种基于大数据的用水量预测方法,其特征在于,所述用水量预测方法包括以下步骤:
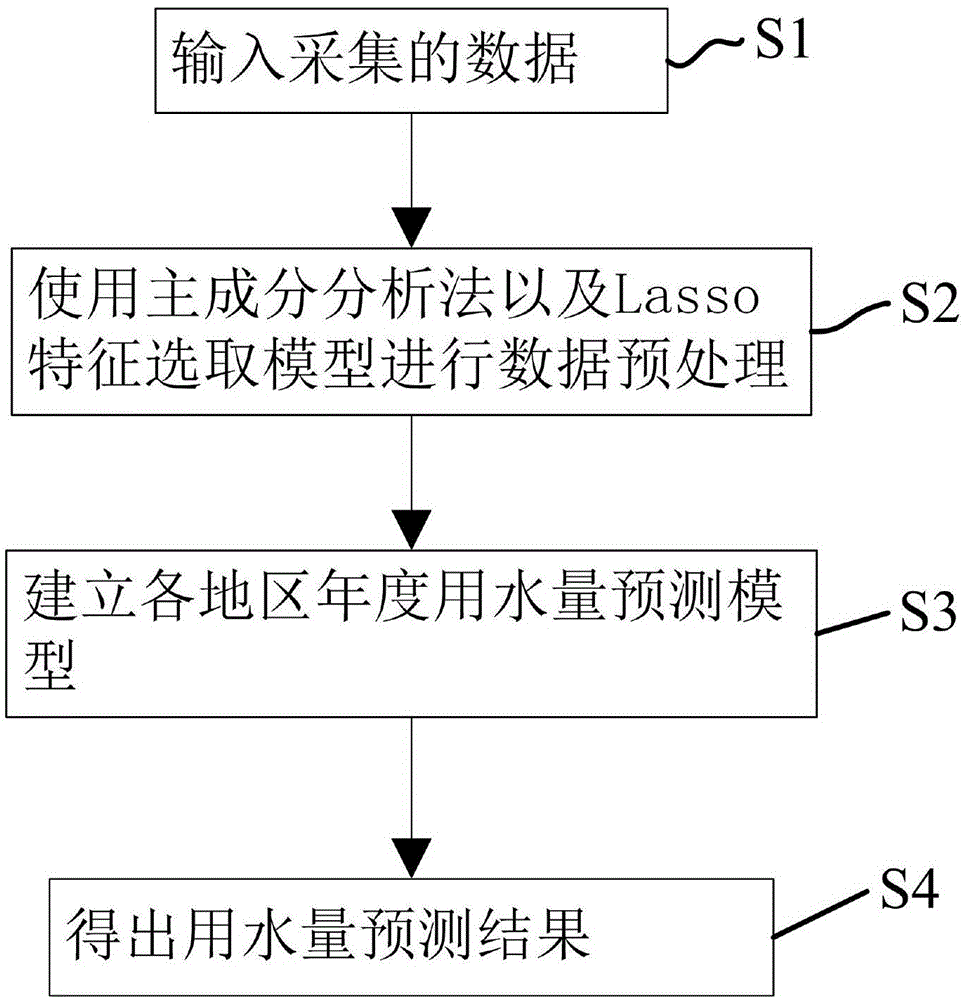
步骤s1、输入采集的数据;
步骤s2、使用主成分分析法以及lasso特征选取模型进行数据预处理;
步骤s3、建立各地区年度用水量预测模型;
步骤s4、得出用水量预测结果。
进一步,所述步骤s1具体通过选取具有代表性的因素xj作为采集的数据,令j=14,则包括:
每年各地区的家庭人均可支配收入x1、水价x2、1-14岁人口数x3、15-64岁人口数x4、65岁及以上人口数x5、没上过学的人数x6、小学程度文化的人数x7、中学程度文化的人数x8、大学程度文化的人数x9、使用浴缸人数x10、使用淋浴人数x11、水龙头节水器使用数量x12、节水型便器使用数量x13、节水型洗衣机使用数量x14,把每年各地区的用水量记为y,采集并输入每年各地区的用水量y、影响用水量的因素x1~x14。
进一步,所述步骤s2的处理过程如下:
步骤s21、将每年各地区的用水量y、影响用水量的因素x1~x14标准化得到y*i,xii*,xi2*,…,x*i14;
步骤s22、求相关系数矩阵r的特征值和特征向量;
步骤s23、确定主成分的个数m;
步骤s24、对选取的主成分再套用lasso特征选取模型;
步骤s25、剔除系数为0的主成分。
进一步,所述步骤s21中标准化方式如下:
假设收集数据总数为n条,n>1,其中第i条数据为xi,则标准化公式为:
其中,
进一步,所述步骤s22具体包括以下步骤:
步骤s221、令相关系数矩阵
其中,
步骤s222、由特征方程|λι-r|=0,求出对应特征值λi(i=1,2,……,14),其中i为对角线元素为1,其他元素为0的矩阵;
步骤s223、将特征值λi按由大到小的顺序排序,即λ1≥λ2≥…≥λ14≥0;
步骤s224、分别求出对应于特征值λi的特征向量e,其中,e为对特征值λj求齐次方程组(r-λie)e=0的非零解。
进一步,所述步骤s23具体包括以下步骤:
取累计贡献率达85%以上的特征值λ1,λ,2,…λm所对应的前m个主成分c1,c2,…,cm,其中,m<p,p为主成分的总数量,主成分ci的贡献率为:
累计贡献率为:
主成分回归(principal-components-regression,pcr)是在主成分的基础上进行的,作标准化因变量y*对m个主成分c1,c2,…,cm的多元线性回归;
设y*=i1c1+i2c2+…+imcm,由于c1,c2,…,cm都是标准化数据x1*,x2*,…,x*14的线性组合,所以也有
进一步,所述步骤s24具体包括:
通过lasso方法对经由主成分分析法筛选出来的影响用水量的因素再进一步筛选,提高因子质量,将lasso参数估计定义为:
其中,β为回归系数向量,λ为非负正则参数,控制着模型的复杂程度,λ越大,对特征较多的线性模型的惩罚力度就越大,从而最终获得一个特征较少的模型;
其中,
通过确定参数λ,选取交叉验证误差最小的λ值,按照得到的λ值重新拟合模型。
进一步,所述步骤s3具体包括以下步骤:
步骤s31、将t={(c1,y1),(c2,y2),...,(cn,yn)}作为训练集,
其中,
步骤s32、对预测模型进行训练,且在进行下一时刻预测前实时更新训练样本,即添加上一时刻的实际用水量和选取的主成分数据并去除最原始的数据;
步骤s33、对于样本(ci,yi),根据模型输出f(ci)与真实值yi之间的差别来计算损失,当且仅当f(ci)=yi时,损失才为零;
步骤s34、将f(xi)与yi之间的偏差最大为ε。仅当|f(xi)-yi|>ε时才计算损失,当|f(xi)-yi|≤ε时,则预测准确。
进一步,所述步骤s4具体包括:
将由步骤s2最终得到的主成分的值输入到用水量预测模型中,输出在各影响因素下各年度地区用水量的预测值。
本发明提供一种基于大数据的用水量预测装置,所述装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当所述计算机程序指令被所述处理器执行时,触发所述装置执行上述任一项所述的方法。
本发明的有益效果是:本发明公开一种基于大数据的用水量预测方法及装置,采用主成分回归模型、lasso回归模型和支持向量机回归预测模型三种模型相结合,在使用了主成分分析之后再套用lasso算法进一步对主成分进行筛选,降低了对因子质量的要求,相比于现有的技术,本发明只需要收集较少的影响因素数据集就可以求出精确度高的用水量,大幅度提高用水量的预测精度的同时在更短的时间内预测出用水量。
附图说明
下面结合附图和实例对本发明作进一步说明。
图1是本发明实施例一种基于大数据的用水量预测方法的流程图。
具体实施方式
参考图1,本发明实施例提供的一种基于大数据的用水量预测方法,包括以下步骤:
步骤s1、输入采集的数据;
影响用水量的因素有许多,例如每年各地区的收入水平、人口年龄段分布、受教育程度、洗澡方式、水价、节水器具使用情况等。
本实施例中选取其中比较具有代表性的因素,包括:
每年各地区的家庭人均可支配收入x1、水价x2、1-14岁人口数x3、15-64岁人口数x4、65岁及以上人口数x5、没上过学的人数x6、小学程度文化的人数x7、中学程度文化的人数x8、大学程度文化的人数x9、使用浴缸人数x10、使用淋浴人数x11、水龙头节水器使用数量x12、节水型便器使用数量x13、节水型洗衣机使用数量x14,把每年各地区的用水量记为y,采集并输入以上数据。
步骤s2、使用主成分分析法以及lasso特征选取模型进行数据预处理;
主成分分析法是将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法,并且通过该方法可以计算出综合得分,从而筛选出贡献值相对较高的因素来进行预测工作以达到减少计算量效果的方法。
其中主成分分析法以及lasso特征选取模型主要是用于特征选取的,处理过程如下:
步骤s21、将每年各地区的用水量y、影响用水量的因素x1~x14标准化得到y*i,xii*,xi2*,…,x*i14;
标准化方式如下:
假设收集数据总数为n条,n>1,其中第i条数据为xi,则标准化公式为:
其中,
步骤s22、求相关系数矩阵r的特征值和特征向量:
求解方式如下:
步骤s221、令相关系数矩阵
其中,
步骤s222、由特征方程|λι-r|=0,求出对应特征值λi(i=1,2,……,14),其中i为对角线元素为1,其他元素为0的矩阵;
步骤s223、将特征值λi按由大到小的顺序排序,即λ1≥λ2≥…≥λ14≥0;
步骤s224、分别求出对应于特征值λi的特征向量e,其中,e为对特征值λj求齐次方程组(r-λie)e=0的非零解。
步骤s23、通过如下方式确定主成分的个数m;
取累计贡献率达85%以上的特征值λ1,λ,2,…λm所对应的前m(m<p)个主成分c1,c2,…,cm,其中,p为主成分的总数量,主成分ci的贡献率为:
累计贡献率为:
主成分回归(principal-components-regression,pcr)是在主成分的基础上进行的,作标准化因变量y*对m个主成分c1,c2,…,cm的多元线性回归;
设y*=i1c1+i2c2+…+imcm,由于c1,c2,…,cm都是标准化数据x1*,x2*,…,x*14的线性组合,所以也有
步骤s24、对选取的主成分再套用lasso特征选取模型;
lasso方法将特征的系数进行压缩并使某些回归系数变为0,进而达到特征选择的目的,模型选择本质上是寻求模型稀疏表达的过程,而这种过程可以通过优化成一个“损失和惩罚”的函数问题来完成。
lasso方法对经由主成分分析法筛选出来的影响用水量的因素再进一步筛选,提高因子质量。lasso参数估计定义为:
其中,β为回归系数向量,p为变量的总数量,λ为非负正则参数,控制着模型的复杂程度,λ越大,对特征较多的线性模型的惩罚力度就越大,从而最终获得一个特征较少的模型;
其中,
步骤s25、剔除系数为0的主成分。
步骤s3、采用svr(support-vector-regression,支持向量回归)模型预测各地区年度用水量;
svr在做拟合时采用了支持向量机的思想来对数据进行回归分析,通过以下方式进行处理:
步骤s31、将t={(c1,y1),(c2,y2),...,(cn,yn)}作为训练集,
其中,
步骤s32、对预测模型进行训练,且在进行下一时刻预测前实时更新训练样本,即添加上一时刻的实际用水量和选取的主成分数据并去除最原始的数据;
步骤s33、对于样本(ci,yi),通常根据模型输出f(ci)与真实值yi之间的差别来计算损失,当且仅当f(ci)=yi时,损失才为零;
步骤s34、将f(xi)与yi之间的偏差最大为ε,仅当|f(xi)-yi|>ε时才计算损失,当|f(xi)-yi|≤ε时,认为预测准确。
步骤s4:得出用水量预测结果;
通过步骤s3,可以得到一个用水量预测模型,我们只需将由步骤s2最终得到的主成分的值输入到用水量预测模型中,即可较为准确且快速地输出在各影响因素下各年度地区用水量的预测值。
本实施例还提供一种基于大数据的用水量预测装置,所述装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当所述计算机程序指令被所述处理器执行时,触发所述装置执行上述任一项所述的方法。
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!