一种基于加权主成分分析法及M估计的三维点云配准方法与流程
本发明属于三维重建技术领域,具体涉及一种基于加权主成分分析法及m估计的三维点云配准方法。
背景技术:
随着深度传感设备的快速发展,计算机视觉技术的研究对象已经逐渐从二维图像、lidar扫描数据转换为三维点云数据。由于场地或测量仪器的测量范围的限制,一个三维物体的呈现方式常为若干来自不同视角的点云数据片段。为了得到物体完整的点云数据,需要通过配准方法将其转换到同一个坐标系下。点云配准方法可分为粗配准和精配准。粗配准主要目的是为精配准方法获取一个初始的对准关系,使得精配准结果更加准确。现阶段点云配准方法主要应用于计算机视觉、模式识别、三维重建、计算机图形学及医学图像等领域。
主成分分析法(pca)是常用的基于特征的点云粗配准方法,该方法利用点云数据体积的主轴方向实现配准。因pca注重整体的结构特征,在实现时使用的距离差是点云数据与点云重心的差值,忽略了三维物体本身形状存在的不规则性,无法顾及点云中各点的局部结构特征。因此,为获得兼顾点云局部特性的配准结果,需对该算法进行改进。
迭代最近点(icp)算法需要通过不断的迭代计算对应点对,对于海量的三维点云数据的配准需要耗费大量时间进行计算,并对计算机的计算能力要求也非常高,因此需要对点云数据进行精简后再进行精配准。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于加权主成分分析法及m估计的三维点云配准方法,降低配准算法的时间、空间复杂性及算法复杂度,获得精确的转换关系。
本发明采用以下技术方案:
一种基于加权主成分分析法及m估计的三维点云配准方法,使用加权pca算法获取粗糙及初始的转换关系,实现原点云及目标点云的粗配准;利用bp神经网络及二维移动窗口对其点云数量进行精简,获得精确的旋转平移矩阵;采用柯西函数作为目标函数,根据icp算法计算出精确的对准关系,将原点云和目标点云进行精配准,配准后的点云数据用于逆向工程中的曲面重构,获得三维物体模型。
具体的,原点云及目标点云的粗配准具体为:
采用三维激光扫描仪获取原点云p与目标点云o的点云数据,并分别利用加权pca算法计算主轴方向,根据邻点与该数据点的距离大小对邻近点进行排序;距离小的邻近点对数据点的影响较大,距离较远的邻近点对数据点的影响较小,根据邻近点与数据点距离的大小赋予邻近点不同的权值,保留三维点云数据的局部特性。
进一步的,具体步骤如下:
s101、采用k最近邻算法计算每个数据点pi的邻近k个数据点qi=[qi1,qi2,...,qik]t,将qi按照其与pi的距离由小到大的顺序进行排序,得到每个邻近点的权值wij为:
其中,i=1,2,...,n,j=1,2,...,k,σ是点云中每个点pi到第k个邻近点的平均距离,pi为邻近点坐标的平均值;
s102、对每个数据点pi求得一个3×3的矩阵mi,分解
s103、根据步骤s102的结果得到粗配准方法的旋转平移矩阵,根据旋转平移矩阵计算出配准后的数据集p′。
更进一步的,步骤s103中,粗配准方法的旋转矩阵rc和平移矩阵tc为:
配准后的数据集p′为:
p′=rc×p+tc
具体的,利用bp神经网络及二维移动窗口对其点云数量进行精简具体为:
利用二维移动窗口法检测出点云边缘信息中蕴含的特征有效信息并予以保留;利用梯度下降法减少输入模型和输出模型间的均方差的和对bp神经网络进行训练,采用bp神经网络对点云数据进行精简,若输入值和输出值的差值越大,二者之间的梯度差异越大,即为想要保留的特征点。
进一步的,具体步骤如下:
s201、采用包含两个隐层的bp神经网络对点云数据进行简化,采用元数据集p进行简述,利用实际输出和理想输出的平均差值函数e以及输出函数的平均梯度变化g作为评价函数,具体为:
若
s202、采用二维的移动窗口对数据进行扫描,检测出具有特征信息的局部极值点。
更进一步的,步骤s202具体为:
s2021、按照x坐标从小到大的顺序对点云p进行重新排序,对前sw个点进行检测;
s2022、找到sw点中y和z坐标的最大值和最小值所对应的点,将窗口一到下一个sw个点中,以同理找到对应的点,并将点遍历结束;
s2023、按照y坐标值的升序对数据集进行排序,并找到sw点中x和z坐标的最大值和最小值所对应的点,遍历结束后获得8×n/sw个具有局部极值点的数据点,作为恢复的边缘特征点。
具体的,采用icp算法得到精确的配准关系具体为:
采用m估计中的柯西函数作为最小二乘法的目标函数;原点云集p及目标点云o经过粗配准和简化操作后的结果u和v作为精配准方法的输入,并将精配准算法的初始旋转矩阵设为单位矩阵,平移向量设为零向量,以最小二乘法迭代计算出最终的旋转平移矩阵。
进一步的,旋转平移矩阵为:
其中,r和t为初始旋转和平移矩阵,vc和uc是对应点对,迭代终止的条件为迭代次数到达预设值或最小距离差小于阈值。
更进一步的,目标函数为:
柯西函数:
其中,r为冗余指数,c=2.385为常量,柯西函数的导数为:
精配准法中的权值函数w为:
与现有技术相比,本发明至少具有以下有益效果:
本发明一种基于加权主成分分析法及m估计的三维点云配准方法,算法中的粗配准可以花费极少量的时间为精配准提供较为精确的初始位置,以便降低精配准算法的时间复杂度及算法复杂度,本发明采用加权pca算法,权值函数充分考虑点云的局部特征,可获得比传统pca算法更加精确的粗配准结果。简化操作可以进一步地降低精配准算法的时间复杂度,并减少空间复杂度,其原理是利用简化的思想删除次要信息,仅保留表达物体的主要信息。精配准方法采用m估计中的柯西函数作为目标函数,该函数对噪声点及异常点具有很强的抗性,可以在省略滤波步骤的同时获得精确的配准关系。
进一步的,为获得点云初始对应关系,采用一种改进的加权pca方法。该算法采用一种新的加权函数来计算各个邻近点的权值,权值函数涉及邻近点与邻近点中心的距离差,点云每个数据点pi到第k个邻近点的平均距离;该种权值函数同时兼顾每个邻近点与其中心点的局部距离差和整个点云与邻近点的距离差,可以有效估计各个邻近点对点云数据点的影响力。
进一步的,为降低时间复杂性,采用一种新的简化方法对粗配准结果进行简化。该简化算法利用bp神经网络及其特征点提取算法对点云进行简化,bp神经网络利用梯度的下降法筛选出梯度变化显著的数据点,将具有显著特征的点予以保留。
进一步的,由于在bp神经网络简化过程中,有把边缘特征点删除的可能,故采用二维移动窗口计算窗口内点云局部极值,将带有局部极端特性的点予以恢复。由于梯度变化较大的点与局部极值点会有重叠,删除重复数据后即为简化后的点云数据。
进一步的,为有效抵抗噪声干扰,采用一种改进的icp算法对简化点云进行精配准。由于点云在获取过程中受到外界及传感器的影响,不可避免地存在噪声及异常点。为了消除噪声的影响同时省略滤波步骤,本发明采用一种对噪声具有鲁棒性的精配准方法,即基于m估计的加权icp算法,其权值函数由m估计中的柯西函数推导而来,利用点云数据的冗余指数抵抗噪声的干扰。
综上所述,本发明可以有效地降低配准算法的时间、空间复杂性及算法复杂度,对含有噪声和异常点的原始点云也可以获得精确的转换关系。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
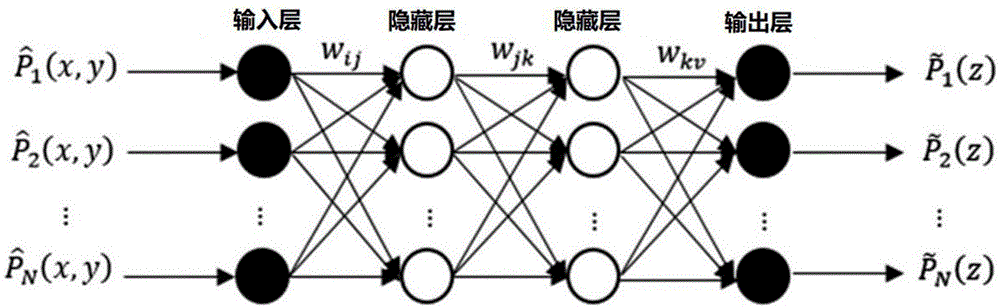
图1为bp神经网络工作原理;
图2为bunny模型的实验结果,其中,(a)为初始点云,(b)为粗对准结果,(c)为目标点云简化结果,(d)为原点云简化结果,(e)为去除重复点后的简化结果,(f)为精对准结果;
图3为dragon模型配准结果,其中,(a)为初始点云-视角1,(b)为初始点云-视角2,(c)为粗配准结果,(d)为目标点云简化结果,(e)为原点云简化结果,(f)为去除重复点的简化结果,(g)为精确配准结果-视角1,(h)为精确配准结果-视角2;
图4为bust配准结果,其中,(a)为初始点云,(b)为粗配准结果,(c)为目标点云简化结果,(d)为原点云简化结果,(e)为去除重复点后的简化结果,(f)为精配准结果;
图5为blade配准结果,其中,(a)为初始点云,(b)为粗配准结果,(c)为目标点云简化结果,(d)为原点云简化结果,(e)为去除重复点后的点云数据,(f)为配准结果;
图6为算法收敛结果,其中,(a)为dragon模型,(b)为blade模型。
具体实施方式
本发明提供了一种基于加权主成分分析法及m估计的三维点云配准方法,
首先采用加权pca算法进行粗配准,权值的计算采用k最近邻算法计算每个数据点的k个最近邻点,并根据邻点与该数据点的距离大小对邻近点进行排序。距离小的邻近点对数据点的影响较大,而距离较远的邻近点对数据点的影响较小。因此根据邻近点与数据点距离的大小赋予邻近点不同的权值,以此来保留三维点云数据的局部特性;
其次,由于三维点云数据量相当庞大,若直接对数据进行精配准,将耗费大量的时间,所以在精配准前使用简化方法对点云数量进行精简;点云的边缘信息中蕴含大量特征有效信息,利用二维移动窗口法检测出此类信息并予以保留,即每个窗口中的极大极小值。后采用bp神经网络对点云数据进行精简,由于bp神经网络的训练原理是利用梯度下降法减少输入模型和输出模型间的均方差的和,因此若输入值和输出值的差值越大说明二者之间的梯度差异越大,即为想要保留的特征点;
最后,采用精配准方法计算精确的转换关系。因前期过程只对点云数据进行简化而并未有滤波去噪声的操作,在剩余点云中依然存在噪声及异常点,故采用的精配准方法需可抵抗噪声的干扰,在此发明中采用m估计中的柯西函数作为目标函数实现迭代最近点算法。
本发明一种基于加权主成分分析法及m估计的三维点云配准方法,包括以下步骤:
s1、采用三维激光扫描仪获取原点云p与目标点云o的点云数据,并分别利用加权pca算法计算主轴方向;
以原点云p=[p1,p2,...,pn]t进行说明:
采用k最近邻算法计算每个数据点pi的邻近k个数据点qi=[qi1,qi2,...,qik]t,将qi按照其与pi的距离由小到大的顺序进行排序,每个邻近点的权值为:
其中,i=1,2,...,n,j=1,2,...,k,σ是点云中每个点pi到第k个邻近点的平均距离,pi为邻近点坐标的平均值,对每个数据点pi求得一个3×3的矩阵mi为:
分解
同理,可获得目标点云集的主轴方向eo,由此可获得粗配准方法的旋转矩阵rc和平移矩阵tc为:
根据旋转平移矩阵可计算出配准后的数据集为:
p′=rc×p+tc
s2、由于数据集中存在冗余数据点,致使配准算法耗费的时间复杂性和空间复杂性显著提高,需要在实现精配准前对点云数据进行简化,具体步骤如下:
s201、采用包含两个隐层的bp神经网络对点云数据进行简化,具体的工作流程如图1所示,依旧采用元数据集p进行简述。图中包括输入层
其中,输入层设为点云p的x和y,理想的输出层设为p的z坐标,h1和h2分别包含h1和h2个神经元,wijj为第i层属于与隐层h1中第j个神经元之间的权值参数参数,wjk为h1中第j个神经元与h2中第k个神经元之间的权值参数。
同理,wkv是h2中第k个神经元与输出层第v个输出之间的权值参数。
利用实际输出和理想输出的差值函数
其中,z为点云z坐标,若
s202、在上一步的简化过程中,点云的数据量经过bp神经网络的筛选,其数量已经急剧减小。
由于上述过程梯度变化较小的点已经被移除,而边缘信息对配准算法具有重要的作用,故应恢复已删除数据中梯度变化小的边缘数据点,我们采用二维的移动窗口对数据进行扫描,检测出具有特征信息的局部极值点,具体过程可描述为:
s2021、按照x坐标从小到大的顺序对点云p进行重新排序,对前sw个点进行检测。
s2022、找到sw点中y和z坐标的最大值和最小值所对应的点,将窗口一到下一个sw个点中,以同理找到对应的点,并将点遍历结束。
s2023、按照y坐标值的升序对数据集进行排序,并找到sw点中x和z坐标的最大值和最小值所对应的点,遍历结束后获得8×n/sw个具有局部极值点的数据点,作为恢复的边缘特征点。
s3、经过粗配准及简化操作后,使用一种改进的icp算法得到精确的配准关系。
采用m估计中的柯西函数作为最小二乘法的目标函数,有效抵抗噪声和异常点的干扰;原点云集p及目标点云o经过粗配准和简化操作后的结果u和v作为精配准方法的输入,并将精配准算法的初始旋转矩阵设为单位矩阵,平移向量设为零向量。
目标函数为:
其中,φ为最小二乘法目标函数,d(vi,u)为原点云与目标点云最近点对的距离,m为目标点云v中的点云个数,u为变化后的点云u中的点;
柯西函数:
其中,r为冗余指数,c=2.385为常量,柯西函数的导数为:
精配准法中的权值函数w表达为:
最终的旋转平移矩阵表达为:
其中,r和t是初始旋转和平移矩阵,vc和uc是对应点对,迭代终止的条件设为迭代次数到达预设值或最小距离差小于阈值。
s4、根据获得的精确转换关系,将原点云和目标点云进行配准,配准后的点云数据可应用于逆向工程中的曲面重构,获得三维物体模型。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中的描述和所示的本发明实施例的组件可以通过各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为了验证算法的有效性和准确性,采用matlab对四组点云模型对其进行仿真实验,并对实现结果进行对比分析。
所有程序的运行环境为intelcorei7-7700hq,主频2.81hz,16g内存,64位操作系统。
第一组实验数据采用bunny点云模型,第二组采用dragon点云模型。这两组模型都额外添加了高斯噪声,bunny模型中目标点云和原点云噪声的信噪比各为65db和70db,dragon模型中的信噪比分别为60db和55db。第三组采用三维激光扫描仪得到bust点云模型,第四组实验采用三维激光扫描仪得到的叶片的点云模型,实验结果按照实验步骤进行呈现。
图2a为配准前的初始点云,灰色为目标点云,黑色为原点云,图2b为基于加权pca的配准算法获得的初始位置关系。图2c为目标点云的简化结果,其中,黑色数据点为bp神经网络简化结果,灰色数据点为二维移动窗口检测到的局部特征点,图2d为原点云的简化结果,图2e为去除bp神经网络及局部特征点重合点后的简化结果,图2f为最终的精配准结果。
图3为dragon模型的配准结果,由于该模型单一视角无法直观的看出配准效果,分别在初始点云和最终配准结果处用两个视角进行演示,其中,图3a和图3b分别为初始点云的视角1和视角2,图3c为粗配准结果,图3d~f分别为两片点云的简化结果及删除重复点后的点云,图3g和图3h是最终的配准结果。
图4为bust模型的实验结果,图4a表示目标点云和原点云的初始位置关系,图4b为粗配准结果,图4c~e为简化结果,图4f为最终的配准结果。
图5为blade的初始点云,粗配准结果,简化结果及精配准结果。
由实验结果可以看出经由粗配准算法后,目标点云和变换后的原点云的相对位置已比初始位置要靠近很多,这时的相对位置作为精配准算法的输入会有效减少算法的时间和空间复杂性。由于迭代最近点算法每次迭代的计算量与点云数量息息相关,表1对算法中各个过程的点云数目进行了描述,其中sw为移动窗口大小,最终点数是为计算精确转换关系时,精配准算法的输入点数。
表1算法各阶段点云数目
从表1中可以看出在点云数目较小时(如bunny和dragon模型),点云数量减少比例较小。而在点云数据量巨大时(如bust和blade模型),简化算法可以削减大量数据点,同时结合表2和图6的结果可以看出,算法在保证原有配准精度的基础上有效缩短运行时间。
表2运行时间对比表(单位:秒)
以dragon模型和blade模型为例,将本发明与仅采用pca和icp算法的配准方法进行对比,以此验证本发明的有效性和优越性。
对比试验从运行时间和运行精度两方面进行验证。表2为dragon模型和blade模型采用本算法及pca和icp算法的运行时间,图6为两种模型的收敛速度对比曲线图。从图2的运行结果可以看出本算法在点云数目巨大的数据模型中运行时间占有绝对的优势,从图6的结果又可看出即使在减少配准点云数目及缩短运行时间的情况下,仍然可以保持其精确度及收敛效率。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!