一种基于CUDA的目标RCS计算方法与流程
本发明涉及电磁计算技术领域,尤其涉及一种基于通用并行计算架构(英文全称:computeunifieddevicearchitecture,英文缩写:cuda)的目标雷达散射截面积(英文全称:radarcrosssection,英文缩写:rcs)计算方法。
背景技术:
当空间中物体受到电磁波照射时,其能量将朝各个方向散射,我们将散射场与入射场叠加,称作空间总电磁场,由于实际场景中都是通过雷达发射电磁波来探测目标,空间总电磁场可以表示成雷达波的功率密度乘以一个有效面积,该有效面积即为目标rcs。物理光学(英文全称:physicaloptics,英文缩写:po)法是一种计算目标的rcs的高频近似法,它用散射体表面的感应电流的积分表示散射场。
po法的思想在于将目标对应的三维模型的表面离散成许多面元,计算各个面元的rcs并叠加,得到整个目标的rcs。po法假设目标未被雷达波照射的部分,即阴影部分对整个目标的rcs是没有贡献的。因此,po法只需计算目标对应的三维模型亮区的rcs,故需要先将三维模型剖分成若干面元,然后通过三维模型面元间的遮挡判断来获得亮区面元。在进行遮挡判断时,现有方法需要将每个面元与其余所有面元进行比较,计算复杂度为面元数量的平方。在计算电大尺寸的复杂目标的rcs时,需要对面元做更精细的划分,面元数大量增加,导致计算复杂,计算时间大幅增加。针对上述问题,有学者提出将目标对应的三维模型每个面元赋予不同颜色再使用开放型图形库(opengraphicslibiaiy,opengl)渲染结果获取亮区面元信息,但是这种方法当视线与面元夹角较小时会出现两区面元漏判情况。
综上,发明人发现现有技术在用po法计算高频率目标对应的三维模型的rcs的过程中,存在面元间的遮挡判断计算复杂、计算时间长,并且可能出现亮区面元误判等不足。
技术实现要素:
有鉴于此,本发明的实施例提供一种cuda的目标rcs计算方法,可以在获取亮区面元时采用无锁的栅格数据结构将面元放入对应的栅格,能够避免将每个面元与其余所有面元进行比较以及将面元放入栅格时使用有锁结构,进而能够降低计算的复杂度,减少计算时间。
为达到上述目的,本发明的实施例采用如下技术方案:
提供一种基于通用并行计算架构cuda的目标rcs计算方法,包括以下步骤:
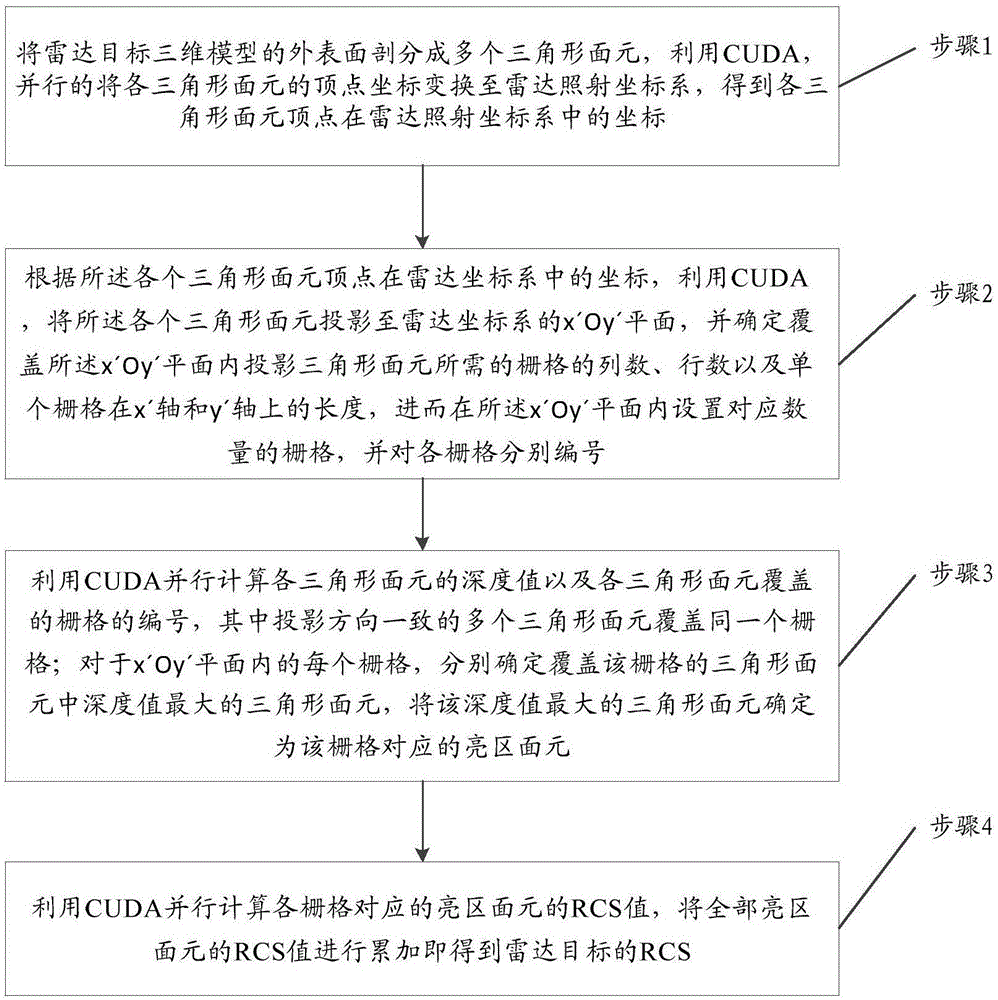
步骤1,将雷达目标三维模型的外表面剖分成多个三角形面元,利用cuda,并行的将各三角形面元的顶点坐标变换至雷达照射坐标系,得到各三角形面元顶点在雷达照射坐标系中的坐标。
步骤2,根据各个三角形面元顶点在雷达坐标系中的坐标,利用cuda,将各个三角形面元投影至雷达坐标系的x′oy′平面,并确定覆盖x′oy′平面内投影三角形面元所需的栅格的列数、行数以及单个栅格在x′轴和y′轴上的长度,进而在x′oy′平面内设置对应数量的栅格,并对各栅格分别编号。
步骤3,利用cuda并行计算各三角形面元的深度值以及各三角形面元覆盖的栅格的编号,其中投影方向一致的多个三角形面元覆盖同一个栅格。
对于x′oy′平面内的每个栅格,分别确定覆盖该栅格的三角形面元中深度值最大的三角形面元,将该深度值最大的三角形面元确定为该栅格对应的亮区面元。
步骤4,利用cuda并行计算各栅格对应的亮区面元的rcs值,将全部亮区面元的rcs值进行累加即得到雷达目标的rcs。基于本发明提供的一种基于cuda的目标rcs计算方法,首先将雷达目标三维模型表面剖分成多个三角形面元,再利用cuda并行的计算各个三角形面元在雷达照射坐标系中的坐标,然后将各个三角形面元投影至雷达坐标系中x′oy′平面中的矩形区域,在矩形区域内设置栅格矩阵;接着利用cuda并行计算各三角形面元的深度值以及各三角形面元覆盖的栅格的编号,对于每个栅格,分别确定覆盖该栅格的三角形面元中深度值最大的三角形面元,将该深度值最大的三角形面元确定为该栅格对应的亮区面元;最后利用cuda并行计算各栅格对应的亮区面元的rcs值,将全部亮区面元的rcs值进行累加即得到雷达目标的rcs。
本发明方法在获取亮区面元时,先将三角形面元放入对应的栅格,从而在进行面元遮挡判断时只需要比较同一个栅格对应的不同三角形面元,而无需将每个面元与其余所有面元进行比较,降低了计算的复杂度,减少计算时间。并且本方法在将三角形面元放入对应栅格时,采用的是无锁的栅格数据结构,从而克服了使用有锁的栅格数据结构导致等待时间变长的不足。因此,本发明方法具有计算复杂度低,计算时间短的优点。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种基于cuda的目标rcs计算方法的流程示意图;
图2为采用专业电磁计算软件feko软件和本发明提供的方法对光滑椎体模型的rcs进行计算的效果对比图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明实施例提供的一种基于cuda的目标rcs计算方法的流程示意图。
参加图1,本发明提供的一种基于cuda的目标rcs计算方法包括以下步骤:
步骤1,将雷达目标三维模型的外表面剖分成多个三角形面元,利用cuda,并行的将各三角形面元的顶点坐标变换至雷达照射坐标系,得到各三角形面元顶点在雷达照射坐标系中的坐标。
需要说明的是,cuda作为一种图形处理器(英文全称:graphicsprocessingunit,英文缩写:gpu)通用计算架构,它包含了cuda指令集架构以及并行计算引擎,较中央处理器(英文全称:centralprocessingunit,英文缩写:cpu)在大量同质数据处理中拥有更强的计算能力,由于gpu具有大量晶体管计算单元的硬件结构特点,使得其在面对大数据量的同质化计算任务时具有超强的运算能力,而本发明方法在对不同的三角形面元进行处理、进行遮挡判断以及计算rcs时具有同质化的特点,因此,利用cuda进行处理以上数据可以大大提高运算效率,节省运算时间。
进一步的,步骤1包括以下步骤:
步骤1.1,将目标的三维模型的表面剖分成个k个三角形面元,并依次编号为1、2、……k,同时为每个面元分配一个对应的线程。
全部k个线程并行执行以下步骤1.2至步骤1.4:
步骤1.2,全部k个线程中的第k个线程获取编号为k的三角形面元三个顶点在三维世界坐标系中的坐标(x1k,y1k,z1k),(x2k,y2k,z2k),(x3k,y3k,z3k);其中,k∈{1,2,...,k}。
步骤1.3,计算旋转轴向量
其中,
步骤1.4,利用所述旋转轴向量,根据罗德里格旋转公式计算变换矩阵m:
其中,i是3×3阶单位矩阵,β是
需要说明的是,本领域技术人员容易理解,轴向量
步骤1.5,全部k个线程中的第k个线程将编号为k的三角形面元三个顶点在三维世界坐标系中的坐标乘以所述投影矩阵m,得到编号为k的三角形面元三个顶点在雷达照射坐标系中的坐标
步骤2,根据各个三角形面元顶点在雷达坐标系中的坐标,利用cuda,将各个三角形面元投影至雷达坐标系中x′oy′平面,确定覆盖x′oy′平面内的全部三角形面元的投影的矩形区域,在矩形区域内设置栅格矩阵。
进一步的,步骤2包括以下步骤:
全部k个线程并行执行以下步骤2.1至步骤2.4:
步骤2.1,全部k个线程中的第k个线程将编号为k的三角形面元投影至x′oy′平面,计算编号为k的三角形面元在x′轴上的面元长度dxk和在y′轴的面元长度dyk。
其中,max(·)表示取最大值,
步骤2.2,全部k个线程中的第k个线程计算编号为k的三角形面元在x′轴上的最大值maxxk和在x′轴上的最小值minxk,在y′轴上的最大值maxyk和在y′轴上的最小值minyk。
其中,
步骤2.3,计算栅格在x′轴上的长度
步骤2.4,根据栅格在x′轴上的长度rx和所述栅格在y′轴上的长度ry,确定覆盖所述x′oy′平面内投影三角形面元所需的栅格的列数
步骤2.5,根据栅格的列数和行数以及单个栅格在x′轴和y′轴上的长度ry,在所述x′oy′平面内四个坐标点(minx,miny)、(minx,maxy)、(maxx,miny)、(maxx,maxy)构成的矩形区域内设置m×n个栅格,并从坐标点(minx,miny)开始沿x′轴正方向对各栅格依次编号为1、2……m×n。
步骤3.1,利用cuda并行计算各三角形面元的深度值以及各三角形面元覆盖的栅格的编号,其中投影方向一致的多个三角形面元覆盖同一个栅格。对于x′oy′平面内的每个栅格,分别确定覆盖该栅格的三角形面元中深度值最大的三角形面元,将该深度值最大的三角形面元确定为该栅格对应的亮区面元。
进一步的,步骤3包括以下步骤:
全部k个线程并行执行以下步骤3.1至步骤3.5:
步骤3.1,全部k个线程中的第k个线程计算编号为k的三角形面元覆盖的栅格编号idrask和深度值depthtrik:
其中,
需要说明的是,投影方向一致是指,在雷达照射坐标系中,会存在亮区面元和暗区面元投影在同一个栅格上的情况,具体来说,计算投影在同一个栅格上的所有面元的深度值,在所有面元中只有深度值最大的面元被雷达波照射到,其余的面元均被该面元遮挡,在计算目标rcs时,只有被雷达波照射到的面元,即亮区面元才对目标rcs有贡献,被遮挡的面元不参与计算。
步骤3.2,在显存中申请一指针集合pb以及用于存放指针集合pb的连续存储空间b,指针集合pb包含m×n+k个指针,指针值分别为p+1、p+2、p+2……p+m×n+k。
其中,指针集合pb中指针值为p+1到p+m×n的指针指向栅格数据结构指针p1,p2,...,pm×n,每个栅格数据结构指针对应一个栅格,指向所对应栅格的栅格数据结构,栅格数据结构包括一三角形面元的面元编号和深度值,初值分别为0和1.7×10-308。指针集合pb中指针值为p+m×n+1到p+m×n+k的k个指针分别与k个三角形面元一一对应,每个指针指向一个对应的栅格数据结构,该栅格数据结构中的数据为与该指针对应的三角形面元的数据。其中,指针值为p+m×n+k的指针与编号为k的三角形面元相对应,其指向的栅格数据结构中包含的三角形面元编号为k,深度值depthtrik为编号为k的三角形面元的深度值。
需要说明的是,栅格数据结构包含三角形面元的面元编号和对应的深度值,三角形面元的面元编号的数据类型为32位无符号整型,对应的深度值的数据类型为双精度浮点型,其中,栅格对应的栅格数据结构赋初值,三角形面元编号为32位无符号整型数值的最小值0和对应的深度值为双精度浮点型数值的最小值1.7×10-308。
步骤3.3,判断指针值为
步骤3.4,第k个线程判断指针值为p+m×n+k的指针对应的栅格数据结构中的深度值depthtrik是否大于指针值为
步骤3.5,记录指针值为p+1至p+m×n的指针对应的栅格数据中所有的面元编号,确定各栅格对应的亮区面元。
需要说明的是,本技术领域人员容易理解,如果在栅格中直接存储一个栅格数据结构,在该栅格数据结构中包含了一个三角形面元编号和对应的深度值。由于每个栅格对应cuda中的一个线程,线程在访问显存中的栅格数据结构时要以独占性的形式访问,保证不受其他线程的打扰,所以要对每个栅格数据结构加锁,但由于加锁带来加锁,解锁,等待等时间开销,所以基于有锁的栅格面元数据结构效率不高。本发明中创新地使用了基于无锁的栅格数据结构,栅格中存储的是栅格数据结构中的指针,长度要比整个栅格数据结构小,因此可以用atomiccas函数来完成操作,从而节省了运算时间,提高了整体的运算效率。
步骤4,利用cuda并行计算各栅格对应的亮区面元的rcs值,将全部亮区面元的rcs值进行累加即得到雷达目标的rcs。
进一步的,步骤4包括以下步骤:
所述全部亮区面元对应的全部线程并行执行以下步骤4.1至步骤4.2:
步骤4.1,计算各栅格对应的亮区面元的rcs值:
其中,
步骤4.2,获取所述各栅格对应的亮区面元对应的线程编号,并行的将所述线程编号取32的模,获得线程束编号i;利用atomicadd函数将线程束编号一致的线程计算出的rcs值相加,得到相加后的数据rcsi,将所述rcsi从gpu拷贝到cpu中,其中i∈{1,2,…,32}。
步骤4.3,在cpu中将所述相加后的数据rcsi相加得到计算雷达目标的rcs值:
优选的,当照射目标的雷达照射角度和雷达照射频率同时发生变化时,可以先利用步骤4.1里的公式计算同一角度下对应的所有待计算频率对应的rcs值,即所有面元对应的所有频率的rcs值,再依次计算每个待计算频率在当前雷达照射角度下对应的rcs值,然后改变雷达照射角度,重复执行上述程序,即可得到目标在不同的雷达照射角度和不同的雷达照射频率的所有rcs值。由于相同角度不同频率下的遮挡关系是一致的,也就是说相同角度下的被照亮的面元是相同的,所以这样可以避免重复获取亮区面元,减少计算时间。
本发明方法在获取亮区面元时,先将三角形面元放入对应的栅格,从而在进行面元遮挡判断时只需要比较同一个栅格对应的不同三角形面元,而无需将每个面元与其余所有面元进行比较,降低了计算的复杂度,减少计算时间。并且本方法在将三角形面元放入对应栅格时,采用的是无锁的栅格数据结构,从而克服了使用有锁的栅格数据结构导致等待时间变长的不足。因此,本发明方法具有计算复杂度低,计算时间短的优点。
进一步的,以下通过仿真实验对本发明实施例方法上述有益效果进行验证:
配置cpu为志强e5-2863v3,gpu为gtx1080的服务器分别使用本发明方法的软件与feko软件模型进行计算。
实验一、
仿真条件:s波段雷达照射频率f=ghz频率,方位角取0°,俯仰角取0°到180°间隔1°,水平极化。
仿真内容及结果分析:使用本发明方法的软件与专业电磁计算软件feko对光滑锥体模型进行计算,采用本发明方法的软件的计算时间为300毫秒,专业电磁计算软件feko的计算时间为3600毫秒,计算结果如图2所示,可见本发明在保证计算精度的前提下,显著减少了计算时间。
实验二、
仿真条件:l波段雷达波照射频率为1.1ghz至1.2ghz频率等间隔取64个频率,方位角取0°,俯仰角取0°到180°间隔1°,水平极化,面元数量12800个。
仿真内容及结果分析:使用本发明方法的软件与专业电磁计算软件feko对光滑锥体模型进行计算,采用本发明方法的软件的计算时间为399毫秒,专业电磁计算软件feko的计算时间为57分钟,可见本发明可以显著减少计算时间。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!