一种基于微博用户自身和行为价值二阶的影响力评估方法与流程
本发明属于计算机数据挖掘技术领域,具体涉及一种基于微博用户自身和行为价值二阶的影响力评估方法。
背景技术:
随着web2.0技术的发展和成熟加速了社交网络媒体平台的普及和多样化,微博以其极快的内容获取和更新速度获取了大量用户,跃身成为国内最大的社交媒体平台。因此对微博中高影响力节点的挖掘算法研究有助于发现微博平台中内容信息的传播规律,可以为相应的企业用户、管理者用户进行广告投放、病毒式营销和舆情管控等提供可靠实时的理论数据依据。
目前,常见方法都是从以下3个角度对社会网络高影响力节点进行挖掘:第一基于拓扑结构的特征度量,局部属性如节点的度中心性,全局属性如节点的紧密中心性、介数中心性等,基于随机游走的度量pagerank、hits等算法通过对网络结构中的用户节点打分来区分用户影响力的大小;第二基于行为的特征度量,如传播范围分析、用户活跃度分析;第三基于内容的特征度量,如话题分析、相似性分析等。然而上述方法大多是从单方面去评价用户影响力,即使结合多个角度去计算也与现实结果存在差异,方法的时间复杂度和准确性有待优化。
技术实现要素:
本发明的目的在于提供一种基于微博用户自身和行为价值二阶的影响力评估方法,最大可能性的避免了僵尸粉、推销商造成的虚假影响力又突出了推送较少但质量极高的用户的隐藏影响力。相较于其他方法花费时间更少,准确度更高。从而为相应的企业用户、管理者、学术研究者更加准确快速的挑选更具影响力的微博用户。
本发明的目的是这样实现的:
一种基于微博用户自身和行为价值二阶的影响力评估方法,包括如下步骤:
步骤一:利用爬虫技术和微博官方api接口采集微博数据;
步骤二:对步骤一中采集的数据进行处理,包括用户静态属性的清理,用户动态行为信息的筛选,得到方法所需用户的特征向量;
步骤三:通过用户所有粉丝的自身价值来计算该用户的自身价值;
步骤四:通过用户所有推送转发者的行为价值来计算用户的行为价值;
步骤五:综合用户的自身与行为价值计算用户最终的影响力。
所述步骤一中,利用爬虫技术采集微博数据后,按照话题分类采集用户和用户关注者、粉丝的全部信息。
所述步骤二中,用户静态属性的清理具体指清理出采集到数据中用户粉丝id、数量、推送微博id、数量、转发者id;用户动态行为信息的筛选具体指将用户的粉丝、转发者做为用户进行二次迭代分析。
所述步骤三中,用户的自身价值计算公式为:
其中ki表示用户i的粉丝数,kj1表示用户i的第j1个粉丝的粉丝量。
所述步骤四中,用户的行为价值计算公式为:
其中hbi表示用户i的一阶行为价值,tj1表示用户i发送的第j1篇微博的转发量,ki表示用户i转发微博的数量;hbi(2)表示用户i的二阶行为价值。
所述步骤五中,用户最终的影响力计算公式为:
其中h-mining(i)表示用户i的综合影响力,取值为用户的自身价值影响力和用户行为价值影响力归一化处理的加权和,α的最佳取值为0.8。
本发明有益效果在于:
(1)本发明通过二次迭代,既保证了用户的质量又保证了用户的粉丝数量和粉丝的行为质量,克服了僵尸粉、水军、推销商对计算用户影响力时造成的虚假影响力,有避免忽略推送较少但质量极高的用户隐藏的真实影响力;
(2)本发明对于发现微博平台中内容信息的传播规律、相应的企业用户、管理者用户进行广告投放、病毒式营销和舆情管控等工作具有重要意义。
附图说明
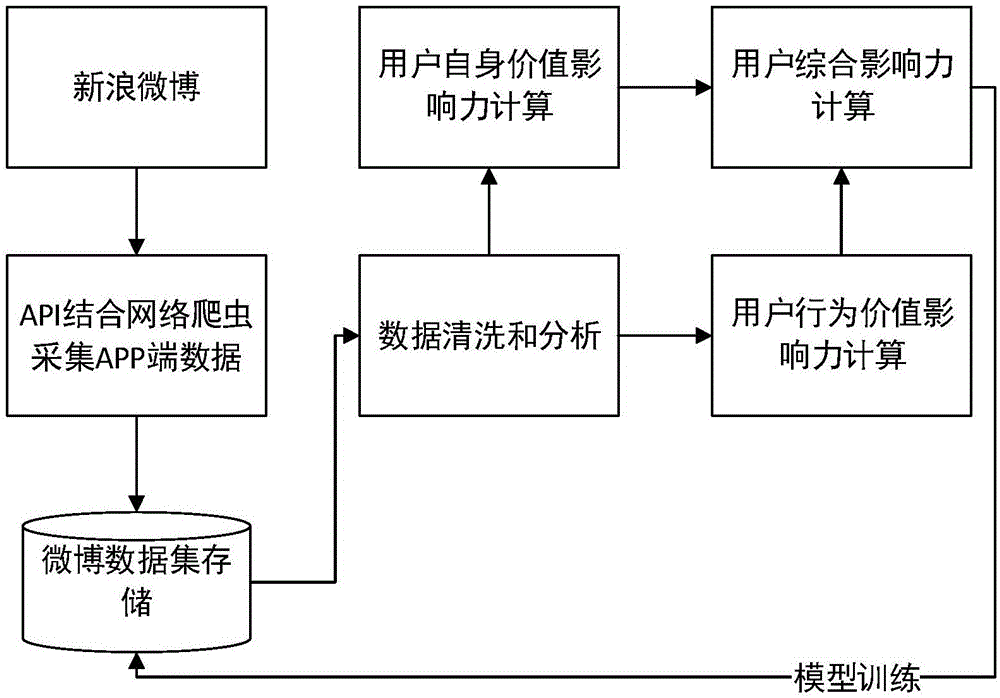
图1为基于微博用户自身和行为价值二阶的影响力评估模型的基本流程图;
图2为本发明与其他方法的实验对比图。
具体实施方式
下面结合附图对本发明做更进一步描述。
本发明涉及社交网络数据挖掘领域,具体涉及一种基于微博用户自身与行为价值的影响力评估方法。此方法包括如下步骤:步骤一:利用爬虫技术和微博官方api接口进行微博的数据采集;步骤二:对采集后的数据处理,包括用户静态属性的清理,用户动态行为信息的筛选,得出方法所需用户的特征向量;步骤三:通过用户所有粉丝的自身价值来计算该用户的自身价值;步骤四:通过用户所有推送转发者的行为价值来计算用户的行为价值;步骤五:综合用户的自身与行为价值计算用户最终的影响力。本发提出一种基于微博用户的自身与行为价值的综合影响力评估方法,该技术通过对用户粉丝数量、质量的计算和用户推送微博的转发者行为质量的计算,即避免了僵尸粉、推销商造成的虚假影响力又突出了推送较少但质量极高的用户的隐藏影响力。
一种基于微博用户自身和行为价值二阶的影响力评估方法的基本步骤如下:
步骤1、利用爬虫技术和微博官方api接口进行微博的数据采集,通过python编写爬虫利用新浪微博的开放接口api获取所需数据,按照话题分类采集用户和用户关注者、粉丝的全部信息。例如:选择某一话题,针对已有的大v,爬取大v的粉丝数量、粉丝id、推送微博数量、微博转发量和微博转发者id等信息。
步骤2、对采集后的数据处理,包括用户静态属性的清理,用户动态行为信息的筛选,不仅要清洗出采集到数据中用户粉丝id、数量、推送微博id、数量、转发者id,还要将用户的粉丝、转发者做为用户进行二次迭代分析,得出方法所需用户的特征向量如表1所示;
表1微博用户特征向量
步骤3、通过用户所有粉丝的自身价值来计算该用户的自身价值,通过步骤二中得到的用户粉丝数量和粉丝的粉丝数量计算出用户自身价值,用户自身价值计算公式如下所示:
步骤4、通过用户所有推送转发者的行为价值来计算用户的行为价值,通过步骤二中得到的用户推送微博的转发数量和转发者的推送微博转发数量计算出用户行为价值,用户行为价值影响力计算公式:
步骤5、综合用户的自身与行为价值计算用户最终的影响力,综合影响力计算公式如下所示:
为证明该评估方法的准确性,分别用已有的pagerank算法、h-index算法和用户粉丝数量与本评估方法做对比实验,top10数据对比表如表2所示:
通过斯皮尔曼等级相关系来评价h-mining、h-index、pagerank和粉丝数与新浪官方排名的相关性,进而判断各模型排名的准确性。斯皮尔曼等级相关系数计算公式为:
本方法基于微博用户自身和行为价值二阶的用户影响力评估模型,通过二次迭代,既保证了用户的质量又保证了用户的粉丝数量和粉丝的行为质量,克服了僵尸粉、水军、推销商对计算用户影响力时造成的虚假影响力,有避免忽略推送较少但质量极高的用户隐藏的真实影响力。对于发现微博平台中内容信息的传播规律、相应的企业用户、管理者用户进行广告投放、病毒式营销和舆情管控等工作具有重要意义。
- 还没有人留言评论。精彩留言会获得点赞!