一种全文本差异比对方法及设备与流程
本发明涉及一种全文本差异比对方法,属于智能识别比对领域。
背景技术:
现有技术中,为审核文件的真实性,需要将文件与其对应的原件进行比对,例如合同审核,合同文本量大,有全文核对需求,比对方式一般大都是通过人工肉眼审核比对,当需要比对的文件量较大时,不仅耗费时间长、人力成本高且出错风险大。
公开号为:cn106372040a,名称为《智能变电站配置文件差异性比较系统》的发明专利公开了智能变电站配置文件差异性比较方法:步骤一、文档数据对比模块先将每个文件以行的方式转为对应的结构数据序列;步骤二、文档数据对比模块将转换后的原件自定义结构数据序列以及对比件自定义结构数据序列进行求最大的lcs序列;步骤三、文档数据对比模块将最大的lcs序列以及结果集序列分别与原件自定义结构数据序列和对比件自定义结构数据序列分别进行对比,得到比对结果。该技术方案是将整个文件转换为结构数据序列进而进行比对,其计算处理量大,尤其在处理大篇幅文件时,容易定位出错,影响差异比对准确率。
技术实现要素:
为了解决上述技术问题,本发明提供一种全文本差异比对方法,利用ocr智能识别,结合文本比较算法,实现自动比对出差异,并进一步自动标注差异,解决文件与其对应原件比对中耗时耗力,人力成本高、准确率低等问题。
本发明技术方案一如下:
一种全文本差异比对方法,包括如下步骤:对比件和原件通过ocr识别引擎识别文字并生成识别文本,该识别文中包含识别出文本中的文字、各文字在对应的ocr识别影像中的坐标信息;识别文本采用文本比较算法比对出差异文字,获取该差异文字的坐标;定位差异文字,然后在对比件中标记出差异文字;
所述文本比对算法采用队列比对方式,把需要比对的原件识别文本和对比件识别文本分别建立一队列,然后逐字比较,根据两个队列找出相同的文字和不同文字,然后形成一个相同文字的队列和一个差异文字的队列。
更优地,在客户端提交所述对比文件和原件,后台服务器判断所述对比件和原件的格式是否为image影像,若是,则不进行格式转换,若否,将所述对比件和原件通过格式转换转为image格式的影像,所述文本比较算法对所述识别文本采用逐页逐字比对方式,并逐页统计差异文字总数量。
更优地,所述对比件和原件先进行版面分析,再提交至所述ocr识别引擎,所述版面分析包括去除干扰的印章、墨点、下划线、标记页头页尾和或标记表格位置。
更优地,所述对比件和原件在等待队列中按照优先级顺序依次送入ocr识别引擎,根据先进先出原则,先进入等待队列的,优先级别最高;当服务器接收到客户对其中一对比件和原件发出立即识别指令时,将该对比件和原件设置为最高优先级,立即送入ocr识别引擎。
更优地,在客户端展示比对结果,其中,差异文字显示方式包括高亮提示、放大镜提示、以不同底色突出显示文字和或变更字体颜色,浮标展示页码及该页的差异总数量。
本发明还提供一种全文本差异比对设备,包括一后台服务器,所述后台服务器设有存储器和处理器,所述存储器存储有指令,所述指令适于由处理器加载并执行以下步骤:
对比件和原件通过ocr识别引擎识别文字并生成识别文本,该识别文中包含识别出文本中的文字、各文字在对应的ocr识别影像中的坐标信息;识别文本采用文本比较算法比对出差异文字,获取该差异文字的坐标;定位差异文字,然后在对比件中标记出差异文字;
所述文本比对算法采用队列比对方式,把需要比对的原件识别文本和对比件识别文本分别建立一队列,然后逐字比较,根据两个队列找出相同的文字和不同文字,然后形成一个相同文字的队列和一个差异文字的队列。
更优地,所述对比文件和原件通过客户端提交,后台服务器判断所述对比件和原件的格式是否为image影像,若是,则不进行格式转换,若否,将所述对比件和原件通过格式转换转为image格式的影像,所述文本比较算法对所述识别文本采用逐页逐字比对方式,并逐页统计差异文字总数量。
更优地,所述后台服务器先对原件和对比件进行版面分析,再提交至所述ocr识别引擎,所述版面分析包括去除干扰的印章、墨点、下划线、标记页头页尾和或标记表格位置。
更优地,所述后台服务器将对比件和原件送入等待队列,再按照优先级顺序依次送入ocr识别引擎,根据先进先出原则,先进入等待队列的,优先级别最高;当服务器接收到客户对其中一对比件和原件发出立即识别指令时,将该对比件和原件设置为最高优先级,立即送入ocr识别引擎。
更优地,在客户端展示比对结果,其中,差异文字显示方式包括高亮提示、放大镜提示、以不同底色突出显示文字和或变更字体颜色,以浮标方式展示页码及该页的差异总数量。
本发明具有如下有益效果:
1、本发明将ocr智能识别与文本比较算法相结合,快速比对出差异文字并根据坐标定位、标记差异文字,大大提升效率且比对准确率;
2、本发明能够识别文件格式并能够将文本格式其转换为image格式的影像,因此,适用于多种文件格式的差异比对,适用范围广;
3、本发明还对对比件和原件进行版面分析,消除干扰,提高比对准确率;
4、本发明采用优先级原则管理待比对的文件,防止拥堵,同时,人性化设置立即识别功能,满足客户需求;
5、本发明在客户端提供各种差异展示方式,辅助人员轻松审核。
附图说明
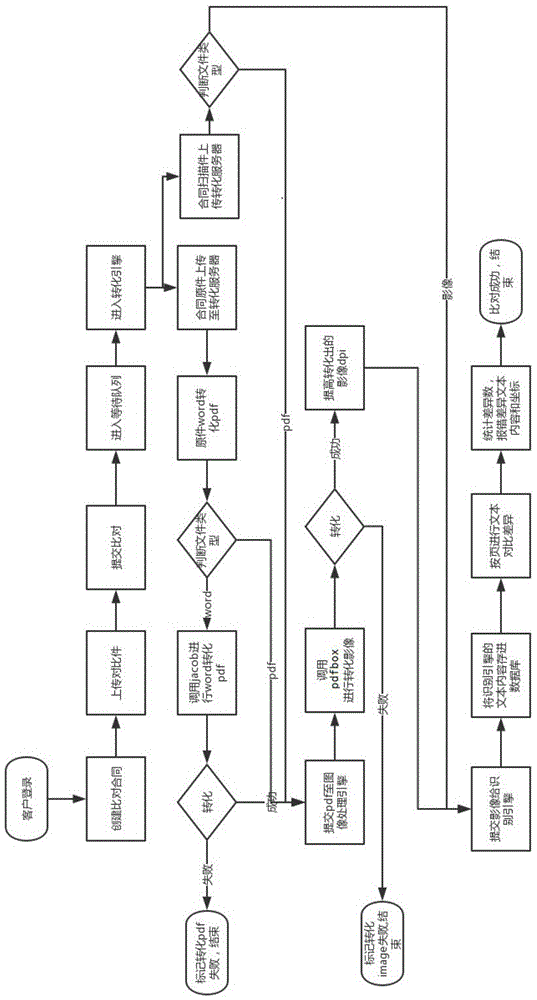
图1为本发明全文本差异比对方法的流程示意图;
图2为本发明全文本差异比对方法中文件优先级流程示意图;
图3为本发明全文本差异比对的比对结果示意图;
图4为本发明全文本差异比对结果以放大镜提示的示意图;
图5为本发明全文本差异比对设备的示意图。
具体实施方式
下面结合附图和具体实施例来对本发明进行详细的说明。
实施例一
一种全文本差异比对方法,包括如下步骤:
请参阅图1,在本实施例中,以比对合同文件,上传word格式的原件和pdf格式的对比件为例。一种全文本差异比对方法,包括如下步骤:对比件和原件通过ocr识别引擎识别文字并生成识别文本,该识别文中包含识别出文本中的文字、各文字在对应的ocr识别影像中的坐标信息;识别文本通过文本比较算法比对出差异文字,获取该差异文字的坐标;根据差异文字的坐标,定位差异文字,然后在对比件中标记出差异文字,如图3所示。比对结果一般都还通过数据库进行保存。所述文字包括汉字、英文字母、数字、符号但不局限于此。
所述文本比对算法采用队列比对方式,把需要比对的原件识别文本和对比件识别文本分别建立一队列,然后逐字比较,根据两个队列找出相同的文字和不同文字,然后形成一个相同文字的队列和一个差异文字的队列。
在客户端提交所述对比文件和原件,例如,通过web端应用程序提交文件,后台服务器判断所述对比件和原件的格式是否为image影像,若是,则不进行格式转换,若否,将所述对比件和原件通过格式转换转为image格式的影像。image格式的影像是将文件根据页进行分割,一页对应一个image影像,所述文本比较算法对所述识别文本采用逐页逐字比对方式,提高比对准确率,且方便统计每页的差异文字总数量。对于如word、excel、pdf等其他格式的文本文件可以通过jacob开源组件将word格式的文件转换成pdf格式,通过pdfbox开源组件将pdf转换成image格式。所述比对结果包括差异文字、差异文字的坐标、差异文字所在的页面以及每一页差异总数量。
所述对比件和原件还可以先进行版面分析,再提交至所述ocr识别引擎。所述版面分析包括去除干扰的印章、墨点、下划线、标记页头页尾和或标记表格位置。版面分析处理包含对影像增强锐化、灰度化、二值化、降噪、倾斜矫正等处理,从而分检出干扰字符的印章、墨点、下划线,在文字识别前剔除这些干扰,然后再标记页头页尾或标记表格位置。通过版面分析处理,可以提高ocr识别引擎的识别准确率。
请参阅图2,所述对比件和原件在等待队列中按照优先级顺序依次送入ocr识别引擎,根据先进先出原则,先进入等待队列的,优先级别最高。为解决特殊需要,当客户对其中一对比件和原件发出立即识别指令时,该对比件和原件被设置为最高优先级,立即送入ocr识别引擎。
在客户端展示比对结果,其中,差异文字显示方式包括高亮提示、放大镜提示(如图4所示)、以不同底色突出显示文字和或变更字体颜色,浮标展示页码及该页的差异总数量。
本发明全文本差异比对方法,将ai智能识别和自动标注技术相结合,实现自动比对并自动标识差异之处,不仅提高自动比对效率,而且通过逐字坐标定位比对差异,大幅提升差异比对结果的准确率,现有应用中,可达到100%的错误(即差异点)识别率,且10分钟即可完成一份100页的合同。在获得对比结果后,对于差异点再辅助人工审核,进一步确保比对零出错率,降低企业风险,避免重大损失。通过本发明全文本差异比对方法,提升人工价值,减少简单重复劳动,从事高附加值工作。本发明尤其适用企业,用于合同、票据等文本量大,有全文核对需求,风控要求高的企事业单位,如信托、基金、证券等。
实施例二
请参阅图1和图5,一种全文本差异比对设备,包括一后台服务器,所述后台服务器设有存储器和处理器,所述存储器存储有指令,所述指令适于由处理器加载并执行以下步骤:
对比件和原件通过ocr识别引擎识别文字并生成识别文本,该识别文中包含识别出文本中的文字、各文字在对应的ocr识别影像中的坐标信息;识别文本采用文本比较算法比对出差异文字,获取该差异文字的坐标;定位差异文字,然后在对比件中标记出差异文字,如图3所示。所述文字包括汉字、英文字母、数字、符号但不局限于此。一般地,所述后台服务器还在数据库中保存比对结果。
所述文本比对算法采用队列比对方式,把需要比对的原件识别文本和对比件识别文本分别建立一队列,然后逐字比较,根据两个队列找出相同的文字和不同文字,然后形成一个相同文字的队列和一个差异文字的队列。
所述对比件和原件在客户端提交,一般地,客户端提交给平台(例如图中的web平台),由平台转发文件至服务器,在本实施例中,平台用于收发文件,其为本领域的惯用手段。后台服务器判断所述对比件和原件的格式是否为image影像,若是,则不进行格式转换,若否,将所述对比件和原件通过格式转换转为image格式的影像。image格式的影像是将文件根据页进行分割,一页对应一个image影像,所述文本比较算法对所述识别文本采用逐页逐字比对方式,提高比对准确率,且方便统计每页的差异文字总数量。对于如word、excel、pdf等其他格式的文本文件可以通过jacob开源组件将word格式的文件转换成pdf格式,通过pdfbox开源组件将pdf转换成image格式。所述比对结果包括差异文字、差异文字的坐标、差异文字所在的页面以及每一页差异总数量。
所述后台服务器还执行版面分析:先对原件和对比件进行版面分析,再提交至所述ocr识别引擎,所述版面分析包括去除干扰的印章、墨点、下划线、标记页头页尾和或标记表格位置。通过版面分析处理,可以提高ocr识别引擎的识别准确率。
请参阅图2,所述后台服务器还包括一等待队列,所述后台服务器将对比件和原件送入等待队列,再按照优先级顺序依次送入ocr识别引擎,根据先进先出原则,先进入等待队列的,优先级别最高。为解决特殊需要,当服务器接收到客户对其中一对比件和原件发出立即识别指令时,将该对比件和原件设置为最高优先级,立即送入ocr识别引擎。
后台服务器将对比结果发送至客户端,在客户端展示对比结果。其中,差异文字显示方式包括高亮提示、放大镜提示(如图4所示)、以不同底色突出显示文字和或变更字体颜色,以浮标方式展示页码及该页的差异总数量。
本发明全文本差异比对设备,将ai智能识别和自动标注技术相结合,实现自动比对并自动标识差异之处,不仅提高自动比对效率,而且通过逐字坐标定位比对差异,大幅提升差异比对结果的准确率,现有应用中,可达到100%的错误(即差异点)识别率,且10分钟即可完成一份100页的合同。在获得对比结果后,对于差异点再辅助人工审核,进一步确保比对零出错率,降低企业风险,避免重大损失。通过本发明全文本差异比对方法,提升人工价值,减少简单重复劳动,从事高附加值工作。本发明尤其适用企业,用于合同、票据等文本量大,有全文核对需求,风控要求高的企事业单位,如信托、基金、证券等。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!