一种基于图像处理的实时人脸活体检测方法与流程
本发明涉及图像处理领域,具体涉及一种基于图像处理的实时人脸活体检测方法。
背景技术:
随着人脸识别技术及系统在各行各业的蓬勃发展(包括银行、手机支付、机场等),人脸识别系统的安全漏洞越来越受到重视,人们迫切地希望增加对个人身份的反欺骗手段,也就是对人脸进行活体检测,从而识别出伪造他人身份的不法行为。
目前,人脸活体检测技术按照活体检测流程可分为以下两类:(1)交互式人脸活体检测:现有的交互式人脸活体检测技术通过人机交互完成,比如人脸活体检测系统要求用户朗读一串文字或者数字,利用语音识别或者唇语识别技术完成活体检测,或者要求用户完成几个相应的动作,比如张嘴、睁闭眼、左右转头等,用以区分真实人脸和2d打印图片、视频回放等欺骗行为。此类人脸活体检测技术用户配合时间长,体验差,而随着近来人脸合成技术的巨大发展,利用图片合成任意动作,并在高清设备下播放,给此类人脸活体检测技术提出了更大的挑战。
(2)非交互式人脸活体检测:在活体检测过程中,不需要人机之间的交互,更加的便捷与友好,用户体验更好。但此类技术通常基于两个及以上的摄像头获取人脸的图像,硬件成本较高。
技术实现要素:
本发明针对现有技术的不足,提出一种基于图像处理的实时人脸活体检测方法,具体技术方案如下:一种基于图像处理的实时人脸活体检测方法,其特征在于:
采用以下步骤,
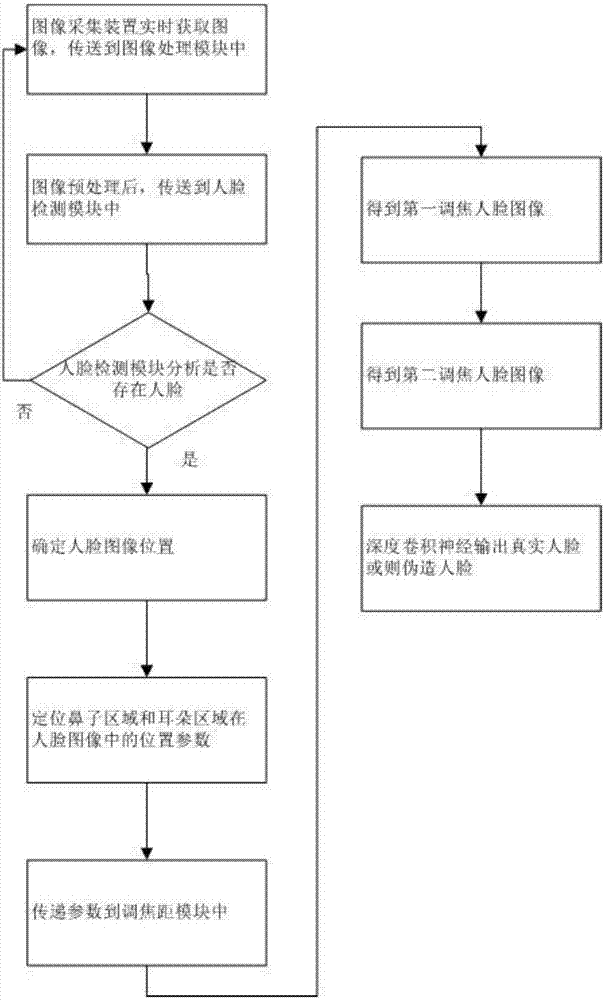
步骤1:图像采集装置实时获取图像,将获取的图像传送到图像处理模块中;
步骤2:图像处理模块对图像进行去噪预处理,将预处理完成的图像输送到人脸检测模块中;
步骤3:人脸检测模块对预处理完成的图像进行检测,分析预处理完成的图像中是否存在人脸图像,如果存在人脸图像,则进入下一步骤,否则,回到步骤1;
步骤4:人脸检测模块确定人脸图像在预处理完成的图像中的位置;
步骤5:人脸检测模块定位人脸图像中的鼻子区域和耳朵区域,得到鼻子区域和耳朵区域在人脸图像中的位置参数;
步骤6:人脸检测模块将所述位置参数传递到调焦距模块中;
步骤7:所述调焦距模块根据鼻子区域的位置参数对图像采集装置进行第一次焦距调节,图像采集装置聚焦在步骤4中人脸图像的鼻子区域,得到第一调焦人脸图像;
步骤8:所述调焦距模块根据耳朵区域的位置参数对图像采集装置进行第二次焦距调节,图像采集装置聚焦在步骤4中人脸图像的耳朵区域,得到第二调焦人脸图像;
步骤9:图像处理模块提取第一调焦人脸图像和第二调焦人脸图像中的深度特征信息;
建立深度卷积神经网络,将第一调焦人脸图像和第二调焦人脸图像中的深度特征信息作为输入参数,输入到深度卷积神经网络中,深度卷积神经网络输出的分类结果对应为真实人脸和伪造人脸。
进一步地:所述深度卷积神经网络为fasnet,该深度卷积神经网络fasnet包括两个组成模块,第一个模块是特征提取模块,由五个dp-block组成,每个dp-block包含一个深度卷积层、一个点卷积层、两个批归一化bn层和两个修正线性单元relu激活层;
第二个部分是分类模块,由一个普通卷积层替代的全连接层和一个softmax层组成。
本发明的有益效果为:为了解决上述人脸活体检测方法的缺点,本发明提供了一种基于非交互式的人脸活体检测方法与系统,且只需要一个摄像头,降低了硬件的成本。该方法在无需用户配合的情况下,通过连续两次调整摄像头的焦距,实时捕捉到连续两帧人脸图像,并通过深度学习的技术,基于本发明所提出的快速卷积神经网络进行特征的提取与活体的检测。相对于其他活体检测方法,本发明的优点是:
第一,无需用户配合,用户体验佳;
第二,安全性高,可准确识别各种材质的打印纸张、视频回放,不受打印纸张与电子屏幕高清程度的影响。
第三,基于快速的卷积神经网络,速度快,鲁棒性强,准确度高。
附图说明
图1为本发明的工作流程图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
如图1所示:一种基于图像处理的实时人脸活体检测方法,
采用以下步骤,
步骤1:图像采集装置实时获取图像,将获取的图像传送到图像处理模块中;
步骤2:图像处理模块对图像进行去噪预处理,将预处理完成的图像输送到人脸检测模块中;
步骤3:人脸检测模块对预处理完成的图像进行检测,分析预处理完成的图像中是否存在人脸图像,如果存在人脸图像,则进入下一步骤,否则,回到步骤1;
步骤4:人脸检测模块确定人脸图像在预处理完成的图像中的位置;
步骤5:人脸检测模块定位人脸图像中的鼻子区域和耳朵区域,得到鼻子区域和耳朵区域在人脸图像中的位置参数;
步骤6:人脸检测模块将位置参数传递到调焦距模块中;
步骤7:调焦距模块根据鼻子区域的位置参数对图像采集装置进行第一次焦距调节,图像采集装置聚焦在步骤4中人脸图像的鼻子区域,得到第一调焦人脸图像;
步骤8:调焦距模块根据耳朵区域的位置参数对图像采集装置进行第二次焦距调节,图像采集装置聚焦在步骤4中人脸图像的耳朵区域,得到第二调焦人脸图像;
步骤9:图像处理模块提取第一调焦人脸图像和第二调焦人脸图像中的深度特征信息;
建立深度卷积神经网络,将第一调焦人脸图像和第二调焦人脸图像中的深度特征信息作为输入参数,输入到深度卷积神经网络中,深度卷积神经网络输出的分类结果对应为真实人脸和伪造人脸。
深度卷积神经网络为fasnet,该深度卷积神经网络fasnet包括两个组成模块,第一个模块是特征提取模块,由五个dp-block组成,每个dp-block包含一个深度卷积层、一个点卷积层、两个批归一化bn层和两个修正线性单元relu激活层;
第二个部分是分类模块,由一个普通卷积层替代的全连接层和一个softmax层组成。
其中,深度卷积层和点卷积层的结构与mobilenet中的深度可分离卷积结构一致,此类结构能够大幅减少模型的参数个数与计算量,达到加速计算的目的。最终,分类网络输出一个范围为[0,1]的概率值,判断是否是真实人脸。本发明提出的fasnet网络模型大小只有168kb,在intel(r)core(tm)i5-4590cpu@3.30ghz处理下测试时间为10ms以内,且精度高,快速实时部署的能力强。
技术特征:
技术总结
一种基于图像处理的实时人脸活体检测方法,采用以下步骤,步骤1:图像采集装置实时获取图像,将获取的图像传送到图像处理模块中;步骤2:图像处理模块对图像进行去噪预处理,将预处理完成的图像输送到人脸检测模块中;步骤3:人脸检测模块对预处理完成的图像进行检测,分析预处理完成的图像中是否存在人脸图像,如果存在人脸图像,则进入下一步骤,否则,回到步骤1;步骤4:人脸检测模块确定人脸图像在预处理完成的图像中的位置;步骤5:人脸检测模块定位人脸图像中的鼻子区域和耳朵区域,得到鼻子区域和耳朵区域在人脸图像中的位置参数。
技术研发人员:周曦;焦宾
受保护的技术使用者:重庆中科云丛科技有限公司
技术研发日:2018.11.23
技术公布日:2019.02.22
- 还没有人留言评论。精彩留言会获得点赞!