基于对抗生成网络的SAR图像和可见光图像的模式转换方法与流程
本发明属于深度学习中的图像翻译领域,涉及一种基于对抗生成网络的sar图像和可见光图像的模式转换方法。
背景技术:
自1978年以来,合成孔径雷达(sar)的出现已经掀起了波澜壮阔的雷达技术革命。其具有的无可比拟的全天时、全天候等诸多优点以及由此产生的广泛应用前景,吸引了雷达科学界的无数目光。继之而来的sar相关研究构成了这次技术革命浪潮的主旋律,不同波段、不同极化乃至不同分辨率的sar系统不断涌现。毋庸置疑,这场伟大的变革已经影响到了军用和民用的各个领域。
由于分辨率的提高,sar的数据量呈级数增长,基于人工的信息处理及应用研究(如目标识别)面临很多困难:首先要在大范围区域中,人工判读实现基于sar图像的地物检测、识别的任务,其任务量之大远远超过人工迅速做出判断的极限,由此带来的主观错误和理解错误不可避免。其次,sar图像特殊的成像机理,使得目标对方位角十分敏感,较大的方位角差异将会导致完全不同的sar图像,使得sar图像在视觉效果上与光学图像的差异进一步加大,增加了图像解释判断的难度;再次,随着sar传感器分辨率的不断提高,传感器模式、波段和极化方式的多元化,sar图像中的目标信息也呈现爆炸性的增长,目标由原来单通道单极化中低分辨率图像上的点目标,变为了具有丰富细节特征和散射特征的面目标,这一方面使得对地物信息进行更细致的解释和识别工作成为了可能,同时也使得地物特征的种类和不稳定性大为增加,因而传统的信息处理和应用方法已经不能满足实际应用的需要,必须对相关的关键技术进行攻关,加速数据处理速度,提高信息提取的精度。
基于此,本发明提出一种基于对抗生成网络的方法,将sar图像转换为具有可见光图像特征的图像模式,主要优点包括以下几个方面:第一,使用对抗生成网络中的cyclegan网络生成图片时,我们不仅将源图像域中的sar图像作为输入,同时提取同一位置的卫星图像的语义特征作为sar图像的先验信息,将该先验信息作为条件同时输入到生成器中,使生成的图像不仅具有可见光的风格,而且同时具有sar图像中看不到的目标信息;第二,为了防止对抗生成网络在训练的过程中出现模型折叠(modecollapse)的情况,我们训练了两个生成器,第一个生成器是通过sar图像生成目标所需要的可见光图像,第二个生成器将生成的可见光图像重翻译为sar图像。我们在训练的过程中,计算原始的sar图像和生成的sar图像之间的生成损失,通过不断减小该生成损失,避免出现训练对抗生成网络中常见的网络模型记忆错误。
技术实现要素:
要解决的技术问题
对sar图像进行图像处理时,一方面由于传统方法对模型比较敏感,对图像要求较高,而sar图像分辨率相对较低,图像质量模糊,在图像与模型不相符时,可能会得不到满意的结果;另一方面,由于我们对目标的反射、散射、透射、吸收和辐射等特性了解不够,很难建立sar图像的特征信号与目标之间的半经验公式或数学模型。为此,我们提出了一种基于对抗生成网络的方法,将sar图像转换为具有可见光图像特征的图像模式,从而实现对目标的识别、检测。
技术方案
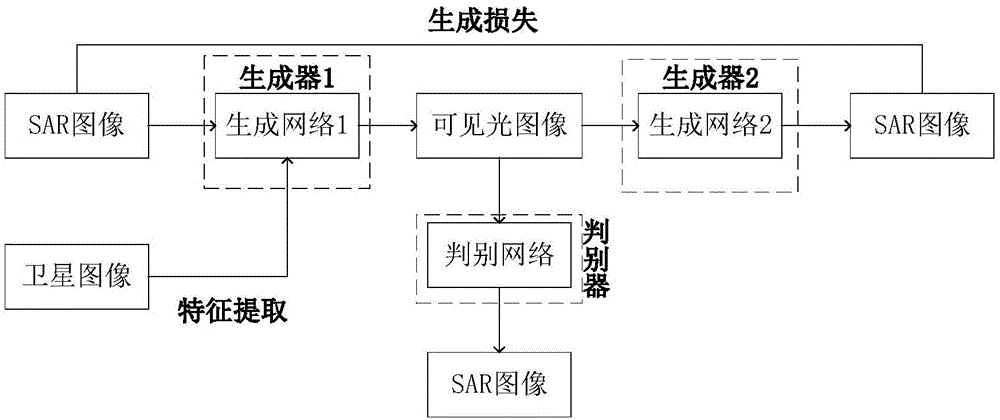
本发明的基本思路是:采用生成对抗网络(generativeadversarialnetwork,gan)的深度学习方法,训练一个无监督学习网络——cyclegan,实现低分辨率的sar图像到可见光图像模式的转换。cyclegan以可见光图像作为目标图像域,以sar图像作为源图像域,学习一个从源图像域到目标图像域的映射,实现源图像到目标图像的转换。cyclegan包括两个生成器g和一个判别器d。生成器g1是实现从源图像域到目标图像域的转换(即把sar图像转换成可见光模式图像),生成器g2是实现从目标域到源图像域的转换(即把可见光模式图像转换成sar图像),判别器d用来判断输入的图片是否是真实的可见光图像。
本发明方法的特征在于步骤如下:
步骤1:获取sar图像的先验信息:基于神经网络的方法,提取同一位置的卫星图像的特征向量,作为sar图像的先验信息,从而使生成对抗网络产生的可见光图像中的目标更清晰。
(1)卫星图像的特征提取:通过卷积层来提取特征,通过池化层对特征进行压缩。
(a)卷积操作提取特征:假定卷积层的输入特征图fin的参数为win×hin×cin,win表示输入特征图的宽度,hin表示输入特征图的高度,cin表示输入特征图的通道数。卷积层的卷积参数为k,s,p,stride,k表示卷积核的数目,s表示卷积核的宽度和高度,p表示对输入特征图进行补零操作,例如p=1表示对输入特征图的周围补一圈0,stride表示卷积核在输入特征图上的滑动步长。则卷积层的输出特征图fout的参数为wout×hout×cout,wout表示输出特征图的宽度,hout表示输出特征图的高度,cout表示输出特征图的通道数,其参数计算如下:
现在的卷积核的大小一般为3×3,p=1,stride=1,这样可以保证输入特征图和输出特征图的大小保持一致。
(b)池化层压缩特征:一般采用最大池化层,即在对特征图进行下采样时,选取2×2格子中值最大的数传递至输出特征图中。池化操作中,输入、输出特征层的通道数不变,输出特征图的大小是输入特征图大小的一半。
通过上述提出的卷积池化操作,即可完成对卫星图像的特征提取。
步骤2:生成器生成可见光图像:设计的生成器有两个输入接口,第一个接口接收sar图像,第二个接口接收步骤一提取到的卫星图像的特征向量,然后经过编码器、转换器和解码器的作用,生成一幅可见光图像。
(1)编码器
将sar图像输入到编码器中,编码器提取sar图像的特征信息,以特征向量表示。其中,编码器有三个卷积层组成,分别为一个具有32个滤波器和步幅1的7*7的卷积层,一个具有64个滤波器和步幅2的3*3的卷积层和一个具有128个滤波器和步幅2的3*3的卷积层。我们将一个尺寸为[256,256,3]的sar图像,输入到设计好的编码器中,编码器中不同大小的卷积核在输入图像上移动并提取特征,得到尺寸为[64,64,256]的特征向量。
(2)转换器
转换器的作用是组合sar图像的不同相近特征,然后基于这些特征,确定如何转换为目标域中的图像(可见光图像)的特征向量。由于步骤1得到了卫星图像的特征向量作为sar图像的先验信息,编码器得到了sar图像的特征向量。因此,首先要将两个不同的特征向量进行融合,才能作为解码器的特征输入。解码器由若干个残差块组成,残差块的目的是为了确保先前网络层的输入数据信息直接作用于后面的网络层,使得相应输出(可见光图像的特征向量)与原始输入的偏差缩小。
(3)解码器
将转换器得到的目标域中的图像(可见光图像)的特征向量作为输入,解码器接受该输入,从特征向量中还原出低级特征,解码过程和编码过程完全相反,整个解码过程都是采用了转置卷积层。最后,将这些低级特征转换,得到一张在目标图像域中的图像,即可见光图像。
步骤3:判别器判别可见光图像:将生成器输出的图片输入到训练好的判别器d中,判别器d会产生一个分值d。输出越接近目标域中的图像(即可见光图像),d的值越接近1;否则d的值越接近0。通过判别器d,来判断生成的图像是不是可见光图像。d的判断是通过计算判别损失来完成的。
判别损失为:
lgan(gab,d,a,b)=eb~b[logd(b)]+ea~a[log(1-d(gab(a)))](2)
其中,a为源图像域(sar图像),b为目标图像域(可见光图像),a为源图像域中的sar图像,b为目标图像域中的可见光图像,gab为从源图像域a到目标图像域b的生成器,d为判别器。训练过程是使判别损失lgan(gab,d,a,b)尽量小。
步骤4:验证生成图片的特征相似性:由于判别器d只能判断生成器生成的图片是不是可见光图像风格的,对图片中的目标特征并不能很好的判别。为了防止产生modecollapse(模型折叠),即生成器具有记忆性。同时训练另一个生成器,将步骤二中生成器生成的可见光图像转为sar图像,两个生成器的网络架构完全相同。通过计算生成损失来验证生成图片的特征相似性。
生成损失为:
lgan(gab,gba,a,b)=ea~a[||gba(gab(a))-a||1](3)
生成损失是计算两张sar图像的欧式距离(欧式距离是指m维空间中两个点之间的真实距离),其中,a为源图像域(sar图像),b为目标图像域(可见光图像),gab为从源图像域a到目标图像域b的生成器,gba为从目标图像域b到源图像域a的生成器。a是源图像域中的sar图像,gab(gba(a))是生成的sar图像。训练过程中,要使lgan(gab,gba,a,b)尽量小。
有益效果
本发明提出一种基于对抗生成网络的sar图像转换为可见光图像的模式方法。该方法有效地解决了由于sar图像分辨率相对较低、图像质量模糊,导致传统的基于模型的方法不能有效地对sar图像中的目标进行检测识别的问题。既保留了sar图像的优点,又能有效地利用现有的图像处理方法,减少了sar图像质量问题带来的局限性,研究成本低,具有相当的研究价值,在国民经济和军事领域有着十分重要的作用。
附图说明
图1:本发明方法的总体框架图。
图2(a):生成对抗网络中生成器的网络结构图。
图2(b):生成对抗网络中判别器的网络结构图。
具体实施方式
现结合实施例、附图1及图2(a)和图2(b)对本发明作进一步描述:
本文实验的硬件环境为:gpu:intel至强系列,内存:8g,硬盘:500g机械硬盘,独立显卡:nvidiageforcegtx1080ti,11g;系统环境为ubuntu16.0.4;软件环境为python3.6,tensorflow-gpu。本文针对sar图像和可见光图像的模式转换方法做了实测数据的实验。我们首先得到军事飞机飞行过程中航拍的sar图像(大约5000幅图像,图像大小为256*256),然后结合卫星得到同一位置的卫星图像(5000幅,图像大小为256*256),输入到我们搭建的网络中,网络迭代训练200000次,基础学习率为0.0002,每100000次改变学习率,训练过程中采用adam优化器,训练中每过10000次保存模型。通过实际测试,我们发现生成的图像不仅具有可见光图像的性质,也能很好的显现出原sar图像中看不清的目标特性。
本发明具体实施如下:
步骤1:获取sar图像的先验信息:基于神经网络的方法,提取同一位置的卫星图像的特征向量,作为航拍的sar图像的先验信息,从而使生成对抗网络产生的可见光图像中的目标更清晰。
(1)卫星图像的特征提取:通过卷积层来提取特征,通过池化层对特征进行压缩。
(a)卷积操作提取特征:实例中我们设计的卷积层的输入特征图(即卫星图像)fin的参数为256*256*3,256表示输入特征图的宽度,256表示输入特征图的高度,3表示输入特征图的通道数。卷积层的卷积参数为k,s,p,stride,k表示卷积核的数目,s表示卷积核的宽度和高度,p表示对输入特征图进行补零操作,例如p=1表示对输入特征图的周围补一圈0,stride表示卷积核在输入特征图上的滑动步长。实例中,我们所使用的卷积层的卷积参数分别为64,3,1,1。则卷积层的输出特征图fout的参数为256*256*64,256表示输出特征图的宽度,256表示输出特征图的高度,64表示输出特征图的通道数,其参数计算如下:
其中,win,hin和cin代表输入特征图的参数,wout,hout和cout代表每一层卷积层卷积之后得到的输出特征图的参数。
(b)池化层压缩特征:我们采用最大池化层对卷积层卷积后得到的输出特征图进行池化,即在对特征图进行下采样时,选取2×2格子中值最大的数传递至输出特征图中。池化操作中,输入、输出特征层的通道数不变,输出特征图的大小是输入特征图大小的一半。我们在实验中只对第一、第三、第四这三个卷积层进行池化。
通过上述提出的卷积池化操作,即可完成对图像的特征提取,得到同一位置的卫星图像的特征向量,向量的尺寸为[256,256,64]。
步骤2:训练第一个生成器,生成可见光图像:我们设计的生成器有两个输入接口,第一个接口接收sar图像,实验中sar图像的大小为256*256*3;第二个接口接收步骤一提取到的卫星图像的特征向量,然后经过编码器、转换器和解码器的作用,生成一幅可见光图像。
(1)编码器
将sar图像输入到编码器中,编码器提取sar图像的特征信息,以特征向量表示。其中,编码器有三个卷积层组成,分别为一个具有32个滤波器和步幅1的7*7的卷积层,一个具有64个滤波器和步幅2的3*3的卷积层和一个具有128个滤波器和步幅2的3*3的卷积层。实验中,第一个卷积模块的输出尺度为256*256*64,第二个卷积模块的输出尺度为256*256*128,第三个卷积模块的输出尺度为64*64*256。即我们将一个尺寸为[256,256,3]的sar图像,输入到设计好的编码器中,编码器中不同大小的卷积核在输入图像上移动并提取特征,最后得到尺寸为[64,64,256]的特征向量。
(2)转换器
转换器的作用是组合sar图像的不同相近特征,然后基于这些特征,确定如何转换为目标域中的图像(可见光图像)的特征向量。由于步骤1得到了sar图像的先验信息,即卫星图像的特征向量,编码器得到了sar图像的特征向量。因此,首先要将两个不同的特征向量进行融合,然后作为解码器的特征输入。解码器由若干个残差块组成,残差块的目的是为了确保先前网络层的输入数据信息直接作用于后面的网络层,使得相应输出(可见光图像的特征向量)与原始输入的偏差缩小。我们在实验中采用了9个残差块,每个残差块由两个具有256个滤波器和步幅2的3*3的卷积层组成,第9个残差块的输出尺度为64*64*256。
(3)解码器
将转换器得到的目标域中的图像(可见光图像)的特征向量作为输入,解码器接受该输入,从特征向量中还原出低级特征,解码过程和编码过程完全相反,整个解码过程都是采用了转置卷积层。最后,将这些低级特征转换,得到一张在目标图像域中的图像,即可见光图像。实验中,我们定义了三个反卷积模块,每一个反卷积模块接收上一个模块的输出作为输入,第一个反卷积模块接收转换器中第9个残差块的输出作为输入。其中,第一个反卷积模块由一个具有128个滤波器和步幅2的3*3的卷积层组成,输出的尺度为128*128*128;第二个反卷积模块由一个具有64个滤波器和步幅2的3*3的卷积层组成,输出的尺度为256*256*64;第三个反卷积模块由一个具有3个滤波器和步幅1的7*7的卷积层组成,输出的尺度为256*256*3。最后,经过tanh函数激活得到生成的输出。
步骤3:训练判别器,判别可见光图像:将生成器输出的图片输入到训练好的判别器d中,d会产生一个分值d。输出越接近目标域图像(即可见光图像),d的值越接近1;否则d的值越接近0。通过判别器d,来判断生成的图像是不是可见光图像。d的判断是通过计算判别损失来完成的。
判别损失为:
lgan(gab,d,a,b)=eb~b[logd(b)]+ea~a[log(1-d(gab(a)))](5)
其中,a为源图像域(sar图像),b为目标图像域(可见光图像),a为源图像域中的sar图像,b为目标图像域中的可见光图像,gab为从源图像域a到目标图像域b的生成器,d为判别器。训练过程是使判别损失lgan(gab,d,a,b)尽量小。
实验中,我们为生成器设计了5个卷积模块,最后一个卷积模块后面跟着一个sigmoid层将输出控制在0到1区间内。第一个卷积模块由一个具有64个滤波器和步幅2的4*4的卷积层组成,输出的尺度为128*128*64;第二个卷积模块由一个具有128个滤波器和步幅2的4*4的卷积层组成,输出的尺度为64*64*128;第三个卷积模块由一个具有256个滤波器和步幅2的4*4的卷积层组成,输出的尺度为32*32*256;第四个卷积模块由一个具有512个滤波器和步幅1的4*4的卷积层组成,输出的尺度为32*32*512;第五个卷积模块由一个具有1个滤波器和步幅1的4*4的卷积层组成,输出的尺度为32*32*1。我们将第五个卷积模块的输出输入到sigmoid层,经过sigmoid函数的激活,得到最终的输出。
步骤4训练第二个生成器,验证生成图片的特征相似性:由于判别器d只能判断生成器生成的图片是不是可见光风格的,对图片中的目标特征并不能很好的判别。为了防止产生modecollapse(模型折叠),即生成器具有记忆性。同时训练另一个生成器,将步骤二中生成器生成的可见光图像转为sar图像。通过计算生成损失来验证生成图片的特征相似性。
生成损失为:
lgan(gab,gba,a,b)=ea~a[||gba(gab(a))-a||1](6)
生成损失是计算两张sar图像的欧式距离(欧式距离是指m维空间中两个点之间的真实距离),其中,a为源图像域(sar图像),b为目标图像域(可见光图像),gab为从源图像域a到目标图像域b的生成器,gba为从目标图像域b到源图像域a的生成器。a是原有的sar图像,gba(gab(a))是生成的sar图像。训练过程中,要使lgan(gab,gba,a,b)尽量小。
实验中,我们所设计两个生成器的网络架构完全相同(详见步骤二)。在实验的过程中,我们记录了三个生成损失的日志。第一个是计算由sar图像生成可见光图像的生成损失,由lgan(gab,a,b)=ea~a[||gab(a)-a||1]表示;第二个是计算由可见光图像重建为sar图像的生成损失,由lgan(gab,gba,a,b)=ea~a[||gba(gab(a))-gab(a)||1]表示;第三个是整个生成器的生成损失,由lgan(gab,gba,a,b)=ea~a[||gba(gab(a))-a||1]表示。其中,a为源图像域(sar图像),b为目标图像域(可见光图像),gab为从源图像域a到目标图像域b的生成器,gba为从目标图像域b到源图像域a的生成器。a是原有的sar图像,gab(a)是生成的可见光图像,gba(gab(a))是生成的sar图像。
- 还没有人留言评论。精彩留言会获得点赞!