基于分割候选区提取的多方向文本检测算法的制作方法
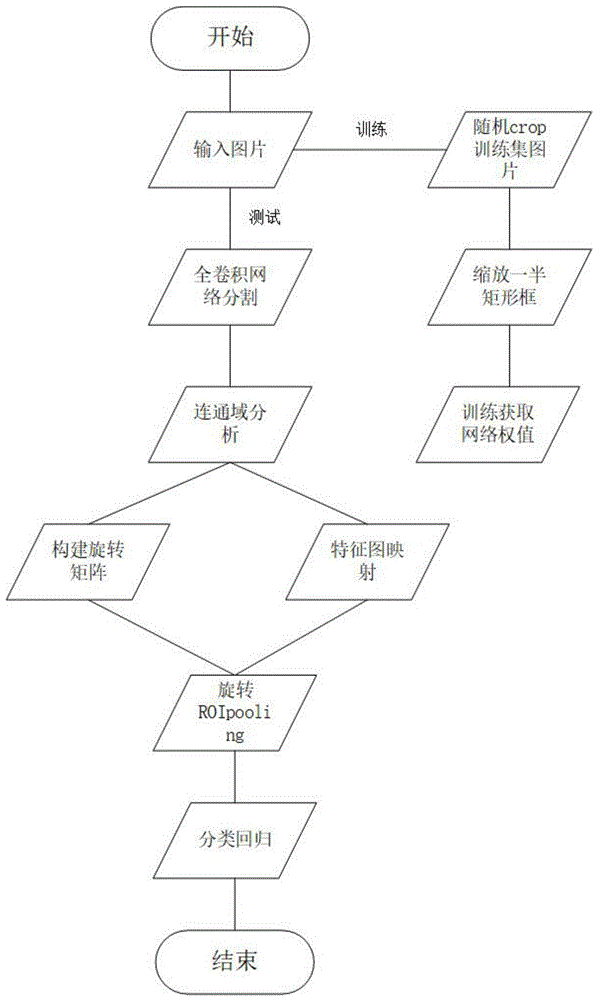
本发明属于计算机视觉、图形处理
技术领域:
,具体涉及一种基于分割的多方向文本检测方法。
背景技术:
:文献“shaoqingren,kaiminghe,rossgirshick,andjiansun.fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetworks.advancesinneuralinformationprocessingsystems.pp.91-99,2015.中采用anchor生成机制生成对应的目标物体候选区域。这种生成机制对于通用物体检测任务是十分有效的。然而,对于自然场景下的文本检测任务,这种候选区生成方式无法有效的生成多方向的文本候选区域。自然场景下文本排列方式不像通用的物体比如人,车等那么规则和有序。因此,仅通过水平方向的外接矩形框生成候选区域,无法满足多方向的文本检测需求。技术实现要素:要解决的技术问题为了解决了现有的算法对多方向的文本定位不够精准的问题,本发明提出一种基于分割候选区提取的多方向文本检测算法。技术方案一种基于分割候选区提取的多方向文本检测算法,其特征在于步骤如下:步骤1:对训练数据集进行随机截取采样,将groundtruth矩形框包含的区域向内缩放一半;步骤2:利用步骤1中生成的训练数据训练层级的全卷积网络,得到分割模型;步骤3:利用步骤2中训练的分割模型对输入图片进行分割,通过连通域分析的方法,获取连通域的外接矩形框作为候选区域;步骤4:通过分析连通区域的主轴方向,获取旋转角度;将获取的候选区域映射到原图四分之一大小的特征图上;步骤5:根据步骤4中获取的旋转角度,构建旋转矩阵,引入到roipooling层中,得到可处理多方向候选区域的旋转roipooling层;利用旋转roipooling层获取候选区域的特征向量;旋转后的特征图宽高可由下式求得:hr=w*sinβ+h*cosβ(13)wr=w*cosβ+h*sinβ(14)w、h为旋转前的宽和高,β为旋转角度;旋转变换矩阵如下式所示:其中,步骤6:将特征向量输入到两层全连接层中,进行回归和分类,实现对多方向文本的检测。步骤1中的训练数据训练神经网络采用的损失函数如下式所示:loss=lseg+lgeo+lcls+lreg(1)其中,lseg为分割的损失函数,lgeo为几何分割损失函数,lcls为分类损失函数,lreg为回归损失函数;表达式如下所示:lseg=balancedxent(ypred,ygt)(2)=-β*ygtlogypred-(1-β)(1-ygt)log(1-ypred)(3)lgeo=-logiou(rgt,rpred)+λ(1-cos(θgt-θpred))(4)lcls=-log(pgtppred+(1-pgt)(1-ppred))(6)其中,smoothl1的函数表达式为其中,ygt,rgt分别为对应的真实标签和真实区域,ypred,rpred分别为对应预测的标签和区域;x*,y*,w*,h*分别为对应真实矩形框的坐标和宽高;x,y,w,h分别对应预测矩形框的坐标和宽高。有益效果本发明提出的一种基于分割候选区提取的多方向文本检测算法,首先,对于倾斜的文本,能够显著提高定位准确度。本发明在国际文档识别竞赛icdar2015数据集上取得了78.4%的召回率,80.4%的准确率和79.4%的f指标。在icdar2013数据集上取得了80%的召回率,90%的准确率和85%的f指标。在多语言数据集msra-td500上取得了63%的召回率,84%的准确率和72%的f指标。附图说明图1为本发明中多方向文本的检测系统的流程图;图2旋转示意图;图3icdar2015数据集上的部分检测结果图;图4msra-td500数据集上的部分检测结果图。具体实施方式现结合实施例、附图对本发明作进一步描述:本发明解决其技术问题所采用的技术方案包括以下步骤:1.首先对训练集进行随机采样,采样比例从原图的0.5倍到2倍不等。同时在生成分割训练集的过程中,考虑到文本之间的距离太近,生成的分割结果会融合到一起。因此,每个分割结果根据标注数据向内缩放一半,以避免相邻连通区域的融合。2.利用步骤1中生成的训练数据训练层级的全卷积网络,得到分割模型。3.对于步骤2中分割得到的结果,通过连通域分析的方法,获取连通域的外接矩形框作为候选区域。4.通过分析连通区域的主轴方向,获取旋转角度。将获取的候选区域映射到原图四分之一大小的特征图上。5.根据步骤4中获取的旋转角度,构建旋转矩阵,引入到roipooling层中,得到可处理多方向候选区域的旋转roipooling层。利用旋转roipooling层获取候选区域的特征向量。6.将特征向量输入到两层全连接层中,进行回归和分类,实现对多方向文本的检测。参照图1,本发明的实现步骤如下:步骤1,首先,对训练数据集进行随机截取采样,将groundtruth矩形框包含的区域向内缩放一半。步骤2,用步骤1中的训练数据训练神经网络。采用的损失函数如下式所示:loss=lseg+lgeo+lcls+lreg(1)其中,lseg为分割的损失函数,lgeo为几何分割损失函数,lcls为分类损失函数,lreg为回归损失函数。他们的表达式如下所示:lseg=balancedxent(ypred,ygt)(2)=-β*ygtlogypred-(1-β)(1-ygt)log(1-ypred)(3)lgeo=-logiou(rgt,rpred)+λ(1-cos(θgt-θpred))(4)lcls=-log(pgtppred+(1-pgt)(1-ppred))(6)其中,smoothl1的函数表达式为其中,ygt,rgt分别为对应的真实标签和真实区域,ypred,rpred分别为对应预测的标签和区域。x*,y*,w*,h*分别为对应真实矩形框的坐标和宽高。x,y,w,h分别对应预测矩形框的坐标和宽高。步骤3,利用步骤2中训练的模型对输入图片进行分割。步骤4,通过连通域分析得到分割所得到的区域的外接矩形框并将矩形区域映射到卷积特征图上。步骤5,通过旋转矩阵将矩形区域进行旋转并进行roipooling操作来提取旋转的区域特征。具体过程如图2所示。旋转后的特征图宽高可由下式求得:hr=w*sinβ+h*cosβ(13)wr=w*cosβ+h*sinβ(14)旋转变换矩阵如下式所示:其中,步骤6,步骤5中提取的特征通过两层全连接层输出预测的文本区域坐标。本发明的效果可以通过以下仿真实验做进一步的说明。1.仿真条件本发明是在gpugtx1080的linux操作系统上,运用tensorflow进行的仿真。仿真中使用的数据均为公开数据集。2.仿真内容首先,在icdar2015公开数据集上做测试。icdar2015共有1000张训练图片和500张测试图片。考虑到icdar2015数据集里有许多倾斜的文本,而检测倾斜的文本区域是本发明的优势。在icdar2015数据集上各项指标如下表所示表1准确率召回率f指标80.478.479.4本发明在icdar2015数据集上取得了很好的效果,这证明了本发明在检测倾斜文本区域方面具有一定的优势。icdar2015数据集上的部分检测结果如图3所示。其次,为了验证本发明也适用于多语言文本区域的检测,在msra-td500数据集上也做了测试。msra-td500数据集包含中文和英文两种语言。测试结果图如图4所示。表2准确率召回率f指标846372当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1