一种基于边界选择的人流统计的装置和方法与流程
本发明涉及一种基于边界选择的人流统计的装置和方法,属于深度学习和图像处理领域。
背景技术:
在视频监控画面中,行人是非常重要的检测目标,行人检测、人群密度估计和人流统计等工作均是智慧安防、智能楼宇的关键组成部分。视频中多变复杂的背景给如何在监控画面中区分检测行人和其它类别物体以及有效分别行人和其背景提出的难题。这项工作在具体的场景中往往出现检测不准确,计数不准确,检测和计数结果延时较长,深度模型占用存储空间较大,不利于传输和下载等问题。
近年来深度学习技术掀起了人工智能的浪潮,在图像分类和目标检测领域,深度卷积神经网络更是取得了一系列重大的突破,准确率有很大提升。但是,机器人控制、自动驾驶技术这类相关的工作不仅要追求准确率,更重要的是速度,必须依赖低延时的系统。近几年r-cnn、fastr-cnn和fasterr-cnn这几种方法代表了目标检测最先进的水平,而yolo(youonlylookonce)是其中实时性性能最好的一种方法。
yolo是一种先进的实时目标检测算法,其准确率比较高,但在实际的应用环境中还是遇到许多问题,例如占用较大存储空间,在实际应用中不利于进行传输和下载、检测,严重的限制了其实际应用,2017年之后更新的yolov2以及之后的yolov3版本借鉴了fasterr-cnn的思想,引入anchor的检测机制,致使新的yolo神经网络无法使用边界选择的方法进行行人计数。
因此,需要寻找一种存储空间小、且实时性较高的人流统计的方法。
squeezenet是在利用现有的基于卷积神经网络(convolutionalneuralnetworks,cnn)模型并以有损的方式压缩的一种小型模型的网络结构。利用少量的参数训练网络模型,实现模型的压缩。它采用firemodle模型结构,分为压缩部分和扩展部分,利用压缩部分和扩展部分相连接形成一种fire模块中组织卷积过滤器。通常的squeezenet开始于一个独立的卷积层(conv1),然后是8个fire模块,最后是一个最终的转换层(conv10)。
技术实现要素:
为了解决上述问题,本发明提供了一种基于边界选择的人流统计的方法,本发明在yolov1神经网络的基础上进行改进,使得其存储空间明显减小,在不影响其准确度的情况下实现较高实时性的人流统计。
本发明的技术方案为:一种基于边界选择的人流统计的方法,所述方法包括以下步骤:
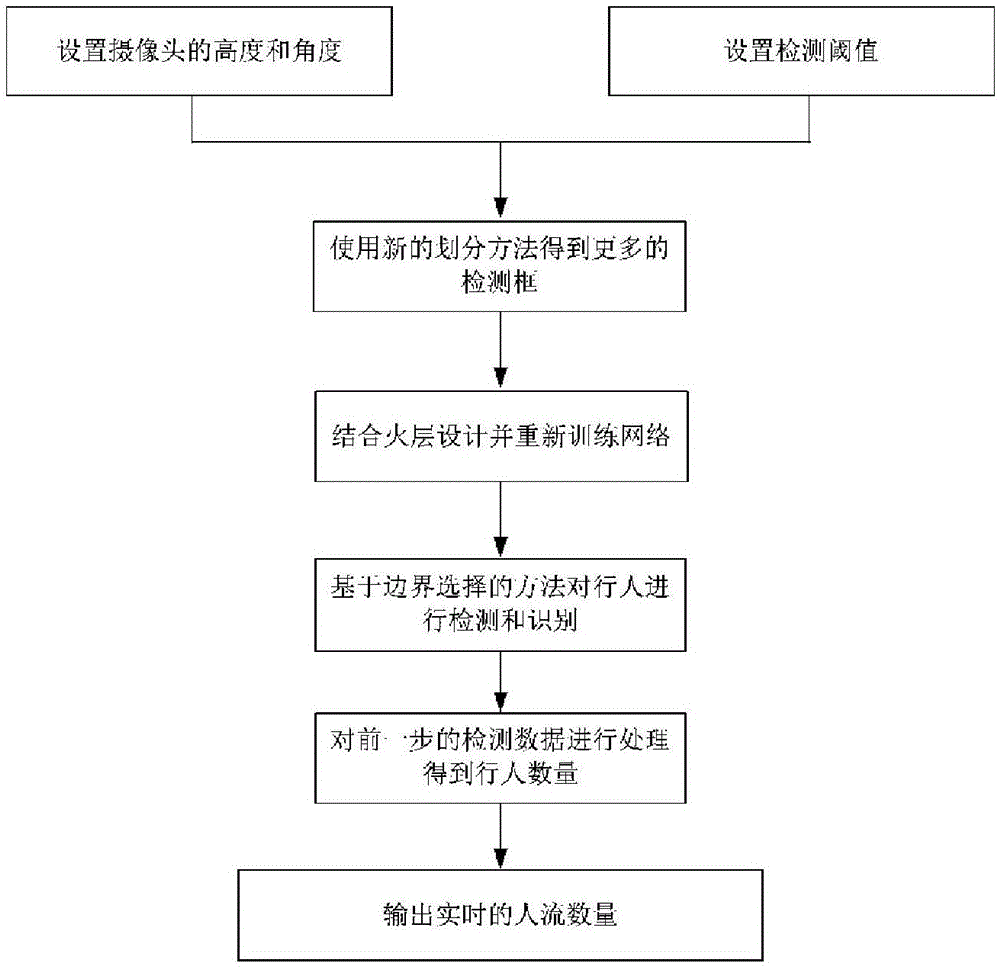
步骤1:设定摄像头的高度和角度使得采集的画面可以覆盖待测定人流的区域,通过摄像头采集人流画面;
步骤2:通过含有gpu的设备设定s-yolo-pc神经网络的检测置信度;
步骤3:s-yolo-pc神经网络读取摄像头采集到的图像;
步骤4:通过含有gpu的设备设定s-yolo-pc神经网络的边界并且检测行人行为;
步骤5:s-yolo-pc神经网络统计人流信息;
步骤6:通过含有gpu的设备将人流统计的结果信息实时输出到电脑屏幕或摄像头自带的屏幕;
所述s-yolo-pc神经网络为改进的yolo神经网络:将yolo单元的划分从7×7增加到9×9,每个单元的检测数量增加到3,得到yolo-pc神经网络,再用squeezenet中的fire模块分别替代yolo-pc神经网络中的第16个、第18个和第24个3×3的卷积层,并将fire模块中的压缩部分的卷积核数量由128减少为96,重新训练网络,即可得到s-yolo-pc神经网络。
在本发明的一种实施方式中,步骤2中所述检测置信度为0.2-0.4。
在本发明的一种实施方式中,所述训练网络仅训练“人”这一类目标。
在本发明的一种实施方式中,所述边界为从243个yolo单元中选择一个或多个网格单元作为区域边界,并根据人们的实际情况选择不同的边界,当人们从某个地方向左转,选择视频左边区域的边界,边界的值为81-89,108-116或135-143中的数值;当人们从某个地方向右转,边界的值为99-107,126-134或153-161中的数值;当人们直行时,边界的值为90-98,117-125或144-152中的数值。
在本发明的一种实施方式中,所述统计人流信息具体为:人流统计值为s/n,其中,所述s表示在时刻t检测到的检测框的数目,n为在设定的置信度和选定的边界区域内,行人被重复检测到的次数。
在本发明的一种实施方式中,当检测置信度为0.2时,行人被重复检测到的次数为18,人流统计值为s/18;当检测置信度为0.3时,行人被重复检测到的次数为16,人流统计值为s/16;当检测置信度为0.4时,行人被重复检测到的次数为13,人流统计值为s/13。
在本发明的一种实施方式中,所述步骤6的信号输出为直接将实时人流数量显示在采集图像的摄像头或者含有gpu的设备上,或将实时信息保存并且不断积累更新,再通过其他接口显示。
本发明还提供了一种基于边界选择的人流统计的装置,
所述装置包括图像采集装置、计算模块和输出模块,其中,计算模块包括计算网络和硬件设备,所述图像采集模块用于采集数据,计算网络在硬件设备上运行以读取采集得到的图像并对行人行为进行识别和计数,之后将人流统计信息通过硬件设备或图像采集装置输出;
其中,所述硬件设备为含有gpu的设备,所述计算网络为s-yolo-pc神经网络,所述s-yolo-pc神经网络为改进的yolo神经网络:将yolo单元的划分从7×7增加到9×9,每个单元的检测数量增加到3,得到yolo-pc神经网络,再用squeezenet中的fire模块分别替代yolo-pc神经网络中的第16个、第18个和第24个3×3的卷积层,并将fire模块中的压缩部分的卷积核数量由128减少为96,重新训练网络,即可得到s-yolo-pc神经网络。
本发明的有益技术效果:
(1)本发明的s-yolo-pc神经网络将原yolo单元的划分从7×7增加到9×9,并将每个单元的检测数量增加到3,能够明显的提高行人检测的平均精度,平均精度较原yolo神经网络提高了14.5%;
(2)本发明通过引入squeezenet中的fire模块来替代原yolo神经网络中特定的3×3卷积层,并将fire模块中的压缩部分的卷积核数量由128减少为96,能够在保证准确率的情况下,明显的压缩神经网络的存储大小,比原yolo神经网络的大小减少了36.5%,大大降低了网络机构对gpu性能的要求,使得其具有更宽的适用场景。
(3)本发明采用限定边界的方法,使得s-yolo-pc能够忽略一些无意义的干扰,如广告牌中的人和不相关的背面,因此s-yolo-pc可以更精确地检测行人的流动。
附图说明
图1:基于边界选择的人流统计的方法的流程示意图。
图2:测定左边界时的实验结果图。
具体实施方式
ap:即averageprecision,平均精度,其计算公式如下:
其中,p(i)是指给定阈值i的时的精度,δr(i)是指k和k-1之间的recall变化值。
训练和测试的数据集来源于pascalvoc(thepatternanalysis,statisticalmodellingandcomputationallearningvisualobjectclassesproject),分为voc2007和voc2012两部分,本发明只训练人这一类别,使用voc2007数据集的5011张图片和voc2012数据集的11540张图片做训练数据,训练数据共16551张,测试集为voc2007测试集,共4952张测试图片。
实施例1
本发明的技术方案为:一种基于边界选择的人流统计的方法,所述方法包括以下步骤:
步骤1:设定摄像头的高度和角度使得采集的画面可以覆盖待测定人流的区域,通过摄像头采集人流画面;
步骤2:通过电脑设定s-yolo-pc神经网络的检测置信度;
步骤3:将yolo单元的划分从7×7增加到9×9,每个单元的检测数量增加到3,得到yolo-pc神经网络,再用squeezenet中的fire模块分别替代yolo-pc神经网络中的第16个、第18个和第24个3×3的卷积层,并将fire模块中的压缩部分的卷积核数量由128减少为96,针对2007+2012数据集重新进行训练网络,仅训练“人”这一类目标,得到s-yolo-pc神经网络,读取摄像头采集到的图像;
步骤4:通过电脑设定s-yolo-pc神经网络的边界:当人们从某个地方向左转,选择视频左边区域的边界,边界的值113;当人们从某个地方向右转,边界的值为129;当人们直行时,边界的值为121,并且检测行人行为;
步骤5:s-yolo-pc神经网络统计人流信息,当置信度为0.2时,行人被重复检测到的次数为18,对应的人流统计值为s/18,其中s值表示在时刻t时检测到的检测框的数目;
步骤6:将人流统计的结果信息包括当前人数、置信度值,实时输出显示在电脑上。
按照同样的方法利用yolo-pc和原yolo神经网络进行同样的人流检测和统计,并对三种不同神经网络以及用于人流检测和统计的数据进行比较。
(1)神经网络的存储大小
对三种神经网络模型的内存进行对比,结果如表1所示,可见s-yolo-pc神经网络的存储大小较原yolo减少了36.5%,较yolo-pc减少9.1%。
表1不同神经网络模型的存储大小
s-yolo-pc神经网络将fire模块替换yolo-pc中的卷积层,针对输入通道数为512或1024时,结果如表2所示,替换后,其得到的参数与原卷积层相比大大减少,例如当输入通道数为512时,相比原卷积层的参数个数减少了约84.7%,进而将fire模块中的卷积核数目由128减少为96,其参数会继续减少25%,参数进一步减小,可见利用fire模块替换yolo中的卷积层,其相应的参数会大大减少。但是参数大量减少会导致其准确率大大降低,因此需要寻找特定的卷积层进行fire模块替换,才有可能保持准确率不变。
表2不同s1不同ci带来的参数变化
其中s1为fire模块的卷积核数目,ci为输入通道数。
(2)平均精度ap
针对三种不同的神经网络yolo、yolo-pc和s-yolo-pc按照同样的方法进行人流检测,平均精度见表3,可见s-yolo-pc的精度较原yolo得到了明显的提高,提高了约14.5%,yolo-pc和s-yolo-pc的精度几乎无变化,可见本发明通过将yolo-pc中的第16、18、24个卷积层进行fire模型替换,并调整其卷积核数目从128减少到96,使得其模型存储大小明显减小(减少了约9%),但是同时能够保证精度几乎一致。
表3不同方法进行行人检测的平均精度
(3)置信值
使用不同的置信度(即0.2、0.3和0.4)设置了三组4分钟实时视频的实验,进行测试,结果如表4所示,s-yolo-pc相较yolo检测得到更多的检测框,且平均置信值为50%以上,明显高于原yolo模型,但是相对于yolo-pc,其平均置信值有所降低,这是由于fire模块对数据进行了压缩导致的,但是整体上对其准确率的影响不大。
表4不同方法在不同阈值下检测框数量和平均置信度对比
对比例1
用squeezenet中的fire模块分别替代yolo神经网络中的输入为1024的第15、17、24层,神经网络模型的存储大小变大,为738.1m,且其准确率变小,为71%。
由对比例可以看出,本发明用fire模块替换第16层、第18层,替换的是输入卷积核数量为512的层,相比替换为全部的输入为1024的层,模型更小,准确率更高,可见,fire模块的替换位置必须是特定的才能达到本发明的效果。
对比例2
用squeezenet中的fire模块分别替代yolo神经网络中的第16、18、19层,第19层同样为输入卷积核数量为1024的卷积层,但是替换后得到的神经网络模型的存储大小不变,但其准确率有所降低。
对比例3
fire模块中的压缩部分的卷积核数量保持128不变时,由上表2可知,当fire模块中的压缩部分的卷积核数量为128时,其参数的个数较压缩部分的卷积核数量为96时明显增加,会明显增大神经网络模型的存储大小,且其准确率无明显改进。
虽然本发明已以较佳实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明的精神和范围内,都可做各种的改动与修饰,因此本发明的保护范围应该以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!