一种基于字典深度学习的半监督图像分类方法与流程
本发明涉及计算机视觉和模式识别领域,更具体的,涉及一种基于字典深度学习的半监督图像分类方法。
背景技术:
在计算机视觉和模式识别领域,图片分类是视觉技术中的基础。深度神经网络凭借其强大的特征表示能力和与人类视觉系统的相似架构,在图片分类任务中取得巨大的成功,引起研究者的广泛关注。为了提高图片分类精度,需要不断研发更强大更复杂的深度神经网络。但是,深度神经网络的成功严重依赖于大量有标签数据,而且越复杂的神经网络架构对标签数据的需求越大。但是,有标签数据的获取,需要通过大量人力去进行标注,非常地耗时耗力。当缺乏大量数据时,深度神经网络会出现称为“过拟合”的严重机器学习问题。与此同时,由于传感器与网络媒体技术的发展,无标签数据非常丰富而且更易于获取。因此,如何利用少量的有标签数据和丰富的无标签数据来训练出具有良好性能的深度神经网络非常关键。
因此半监督机器学习方法开始被引入深度学习领域中。传统的半监督方法致力于同时而有效地利用有标签数据和无标签数据,通常分为4类:协同训练方法,基于图的半监督学习,半监督支持向量机,半监督字典学习,尽管这些传统的半监督方法在一定的假设条件下,确实可以提升模型性能,但是传统的半监督方法通常都是在给定的特征下进行,其特征抽取过程独立于分类器的学习过程。在给定特征不满足分类器的假设情况下,半监督方法没有提升模型性能,甚至会出现损害。尽管半监督字典方法可以把无标签数据吸收到判别性字典学习中,但是却无法抽取有效的特征,因此无法很好地估计无标签数据的类别。而现存的半监督深度学习方法,如lee等在2013年提出的pseudo-label,虽然可以高层抽象特征,但却无法探索无标签数据内在的判别性信息。
技术实现要素:
本发明为了解决深度神经网络能获取有标签数据的有效特征,却无法获取无标签数据和半监督字典方法能把无标签数据吸收到判别性字典学习中,却无法抽取无标签数据的有效特征的问题,提供了一种基于字典深度学习的半监督图像分类方法,其使用字典学习与传统深度神经网络的softmax分类器进行互补,能对无标签数据同时进行特征学习和分类器学习,极大地提升网络性能。
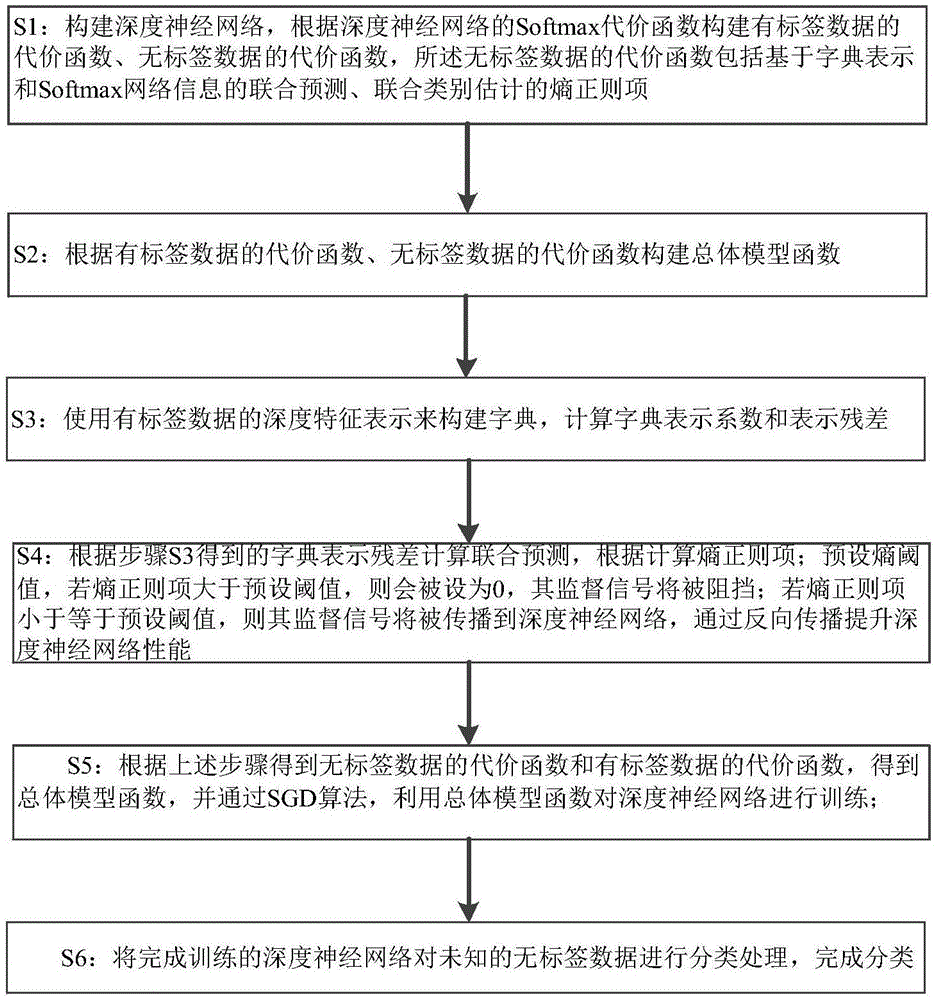
为实现上述本发明目的,采用的技术方案如下:一种基于字典深度学习的半监督图像分类方法,该方法步骤如下:
s1:构建深度神经网络,根据深度神经网络的softmax代价函数构建有标签数据的代价函数ll(zl,yl)、无标签数据的代价函数lu(zu,p),所述无标签数据的代价函数lu(zu,p)包括基于字典表示和softmax网络信息的联合预测
s2:根据有标签数据的代价函数ll(zl,yl)、无标签数据的代价函数lu(zu,p)构建总体模型函数;
s3:使用有标签数据的深度特征表示来构建字典,计算字典表示系数和表示残差;
s4:softmax网络信息
s5:根据上述步骤得到无标签数据的代价函数和有标签数据的代价函数,得到总体模型函数,并通过sgd算法,利用总体模型函数对深度神经网络进行训练;
s6:将完成训练的深度神经网络对未知的无标签数据进行分类处理,完成分类;
其中:(zl,yl)={(z1:n,y1:n)}表示有标签数据
优选地,步骤s1,根据深度神经网络的softmax代价函数构建有标签数据的代价函数ll(zl,yl)的过程如下:
a1:softmax代价函数的softmax归一化输出表示一个样本在c个可能类别上的概率分布,其公式表示如下:
a2:令
a3:当xj属于第k类的时候,即yji=1且k=i,并有yji=0且k≠i时,有标签数据的代价函数,即softmax代价函数,如下:
其中:
优选地,步骤s1,根据深度神经网络的softmax代价函数构建无标签数据的代价函数lu(zu,p)的过程如下:
c1:softmax代价函数的softmax归一化输出表示一个样本在c个可能类别上的概率分布,其公式表示如下:
c2:令
c3:假设存在一个类别特定的字典d=[d1,d2,…,dc],则无标签数据的代价函数lu(zu,p)的表达式如下:
所述无标签数据的代价函数lu(zu,p)包括基于字典表示和softmax网络信息的联合预测、熵正则项h(pr);
其中:
进一步地,基于字典表示和softmax网络信息的联合预测
其中:
进一步地,所述联合类别估计p的熵正则项h(pr),其表达式如下:
为了能挑选高可信的无标签数据的类别估计,以正确地训练网络,提出如下正则:
熵h(pr)的值越大,则联合类别估计pr越不确定;若h(pr)大于预设阈值λ,则pr会被设为0,其监督信号pr将被阻挡;若h(pr)小于等于预设阈值,则其监督信号pr将被传播到网络,通过反向传播提升网络性能;
优选地,所述总体模型的表达式如下:
其中:函数ψ表示在损失代价层前面的特征抽取;p={p1:m}是无标签数据的类别估计,
优选地,步骤s3,使用有标签数据的深度特征表示来构建字典,计算字典表示系数和表示残差的过程如下:
d1:使用有标签数据的深度特征表示来构建字典,构建公式如下:
其中:
d2:通过系数编码算法计算表示系数和表示残差,其公式如下:
求得编码表示系数αr后,通过l2范数计算表示残差
其中:κ是l1正则项的权重系数,用以控制系数的稀疏程度。
优选地,步骤s4,为了防止网络训练更新缓慢,对类别估计进行指数移动平均值,
p't+1=γpt+1+(1-γ)p't
其中:p't+1是第t+1次迭代的类别估计pt+1的指数移动平均值;指数移动平均值保持过去的信息,若当前的类别估计与上一次的类别估计不一致时,p'将会趋于均匀分布,而熵h(p')将增加而不挑选该数据;若估计一致,指数移动平均值则会增强预测;
其中:γ是移动平均的衰减率。
优选地,步骤s5,对总体模型函数进行sgd算法,对无标签数据的深度神经网络的估计
f1:无标签数据的代价函数对
f2:根据有标签数据的代价函数,求得对
根据上述的无标签数据的代价函数梯度公式及有标签数据的代价函数梯度公式,通过sgd算法,深度神经网络利用联合类别估计p来提升网络对无标签数据的预测,并学习更好的深度特征。
本发明的有益效果如下:
1.本发明有效地结合了字典学习方法和深度神经网络到一个统一的框架中,解决了传统半监督学习中没有特征学习的问题,用字典学习与传统深度神经网络的softmax分类器进行了互补,强化了网络对无标签数据的探索能力,相对于有监督网络,可以极大地提升网络性能。
2.本发明通过一种熵正则,可以联合地捕捉网络预测信息和字典学习信息来对无标签数据进行预测,并通过挑选高可信的无标签数据进行网络的反向传播训练,可以很好地减少错误估计的风险。
3.本发明通过一种交替优化方法来训练模型,可以有效地计算对无标签数据的联合类别估计,并为模型设计了相应反向传播算法,使得提出的联合类别估计可以有效地帮助网络进行训练学习,提升网络的预测能力和特征学习能力。
附图说明
图1是本发明基于字典深度学习的半监督图像分类方法的流程图。
图2是本发明的总体框架。
图3是本发明与baseline方法在手写数字数据集mnist上的对比图。
图4是本发明与baseline方法在svhn数据集上的对比图。
具体实施方式
下面结合附图和具体实施方式对本发明做详细描述。
实施例1
如图1所示,一种基于字典深度学习的半监督图像分类方法,该方法步骤如下:
s1:构建深度神经网络,根据深度神经网络的softmax代价函数构建有标签数据的代价函数ll(zl,yl)、无标签数据的代价函数lu(zu,p),所述无标签数据的代价函数lu(zu,p)包括基于字典表示和softmax网络信息的联合预测
s2:根据有标签数据的代价函数ll(zl,yl)、无标签数据的代价函数lu(zu,p)构建总体模型函数;
s3:使用有标签数据的深度特征表示来构建字典,计算字典表示系数和表示残差;
s4:softmax网络信息
s5:根据上述步骤得到无标签数据的代价函数和有标签数据的代价函数,得到总体模型函数,并通过sgd算法,同时利用总体模型函数对深度神经网络进行训练,不但提高对无标签数据的网络的估计
s6:将完成训练的深度神经网络对未知的无标签数据进行分类处理,完成分类;
其中:(zl,yl)={(z1:n,y1:n)}表示有标签数据
本实施例步骤s1,根据深度神经网络的softmax代价函数构建有标签数据的代价函数ll(zl,yl)的过程如下:
a1:softmax代价函数的softmax归一化输出表示一个样本在c个可能类别上的概率分布,其公式表示如下:
a2:令
如下:
a3:当xj属于第k类的时候,即yji=1且k=i,并有yji=0且k≠i时,有标签数据的代价函数,即softmax代价函数,如下:
其中:
本实施例步骤s1,根据深度神经网络的softmax代价函数构建无标签数据的代价函数lu(zu,p)的过程如下:
c1:softmax代价函数的softmax归一化输出表示一个样本在c个可能类别上的概率分布,其公式表示如下:
c2:令
c3:假设存在一个类别特定的字典d=[d1,d2,…,dc],则无标签数据的代价函数lu(zu,p)的表达式如下:
所述无标签数据的代价函数lu(zu,p)包括基于字典学习和softmax网络信息的联合预测、熵正则项h(pr);
其中:
本实施例中来自softmax分类器的网络预测信息
但是,softmax分类器仅仅独立地探索在网络深度特征空间中每个数据点的信息,却没有利用无标签数据和有标签数据之间的联系。因此,仅有softmax分类器缺乏足够的能力去探索具有复杂结构的深度特征空间。而字典学习强大的信息探索能力可以与softmax分类器形成互补。
来自字典学习的类别信息是基于类别特定表示残差
所述基于字典学习和softmax网络信息的联合预测
其中:
超参数η∈(0,1]用于平衡来自softmax分类器的信息和来自字典学习的信息
本实施例所述联合类别估计p的熵正则h(pr),其表达式如下:
由于有标签数据是有限的,难以准确估计所有无标签数据的类别,因此引入熵正则来降低错误估计的风险。为了能挑选高可信的无标签数据的类别估计,以正确地训练网络,提出如下正则:
熵h(pr)的值越大,则联合类别估计pr越不确定;若h(pr)大于预设阈值λ,则pr会被设为0,其监督信号pr将被阻挡;若h(pr)小于等于预设阈值,则其监督信号pr将被传播到网络,通过反向传播提升网络性能;
如图2所示,本实施例根据有标签数据的代价函数ll(zl,yl)、无标签数据的代价函数lu(zu,p)构建总体模型函数;给定一个类别个数为c的数据集,令(zl,yl)={(z1:n,y1:n)}表示有标签数据
函数ψ表示在损失代价层前面的特征抽取,如卷积池化层、全连接层等。ll(zl,yl)是有标签数据的代价函数,lu(zu,p)是无标签数据的代价函数。p={p1:m}是无标签数据的类别估计,
本实施例步骤s3,使用有标签数据的深度特征表示来构建字典,计算字典表示系数和表示残差的过程如下:
d1:使用有标签数据的深度特征表示来构建字典,构建公式如下:
其中:
d2:通过系数编码算法计算表示系数和表示残差,其公式如下:
求得编码表示系数αr后,通过l2范数计算表示残差
其中:κ是l1正则项的权重系数,用以控制系数的稀疏程度。
d3:softmax网络信息
步骤d1~d2也是采用交替优化算法训练模型的一个优化过程:基于字典学习和softmax网络信息的联合类别估计。
但是,此时会出现前面挑选的无标签样本估计,下次更新时又被移除,这会使得网络更新缓慢。为了防止网络训练更新缓慢,对类别估计进行指数移动平均值,
p't+1=γpt+1+(1-γ)p't
其中:p't+1是第t+1次迭代的类别估计pt+1的指数移动平均值;指数移动平均值保持过去的信息,若当前的类别估计与上一次的类别估计不一致时,p'将会趋于均匀分布,而熵h(p')将增加而不挑选该数据;若估计一致,指数移动平均值则会增强预测;
其中:γ是移动平均的衰减率。
本实施采用交替优化算法训练模型的另一个优化过程:所述所述神经网络与无标签类别估计的联合学习,其方法如下:
神经网络通过随机梯度下降法(sgd)进行训练学习,为了用sgd来训练,本实施例为模型设计了如下的反向传播算法。
对于有标签数据的代价函数,其反向传播算法已经存在,此处仅关注无标签数据的代价函数。
对于无标签数据的代价函数,由于字典是通过直接有标签数据的深度特征进行构造,因此仅需要对无标签数据的网络的估计
f1:无标签数据的代价函数对
f2:根据有标签数据的代价函数,求得对
根据上述的无标签数据的代价函数梯度公式及有标签数据的代价函数梯度公式,通过sgd算法,深度神经网络利用联合类别估计p来提升网络对无标签数据的预测,并学习更好的深度特征。
本实施例通过上述的得到的总体模型对深度神经网络进行训练,将完成训练的深度神经网络对未知的无标签数据进行分类处理,完成分类;
为了更好地解释本发明的效果,进行如下实验:
在手写数字数据集mnist和街道数字数据集svhn上进行了与有监督网络,即使用仅用有标签数据进行训练的深度神经网络作为baseline进行对比。使用adam优化算法对网络进行优化训练,初始学习率设置为0.001在第一部分的训练,随后在7500和14500次迭代时执行学习率衰减策略,衰减率为0.1。对于提出的半监督深度学习方法,有标签数据和无标签数据的训练批次大小都为64。
在手写数据集mnist上,从标准训练数据集中每一类别分别随机挑选10和100个样本作为有标签数据集,即总的有标签样本分别为100和1000个,标准训练数据集上余下的所有样本作为无标签数据,整个标准测试数据集用作测试。实验结果如图3所示。
从图3可以看到,对比仅使用有标签数据的半监督网络,提出的半监督深度网络都有明显地提升,特别是有标签样本较小的情况下,在只有100个有标签样本的情况实验中,提出的方法获得了9.43%的效果提升。
在svhn数据集上,从标准训练数据集中每一类别中分别随机挑选25,50和100个样本作为有标签数据集,即总的有标签样本分别为250,500和1000个,标准训练数据集余下的数据作为无标签数据。实验结果如图4所示。
从图4可以看出,svhn数据集上,提出的半监督深度学习模型在所有实验上都有至少10%的提升,特别是在仅有250个有标签训练样本的情况下,分类精度的提升幅度达到了19.81%。这是因为svhn数据集的样本结果更为复杂,深度神经网络判别性不足,而结合了字典学习的联合类别估计有效地利用无标签数据的信息,使得分类精度出现明显的提升,而且可以看到,当有标签训练样本越少的情况下,提出的方法对有监督深度学习网络的提升就越大。
在svhn数据集实验上,从svhn数据集上可以看到本发明明显优于其他对比方法,在样本结构更复杂、分类难度更大的svhn实验中,这种差距非常明显,这说明了提出的半监督深度学习方法有效地利用了无标签数据来提升深度学习网络,同时利用深度神经网络特征的特征抽取能力和字典学习的判别能力,联合概率估计有效地探索无标签内在判别性信息,并通过挑选高可信无标签数据进行网络的反向传播训练,使得深度网络可以性能得到明显提升。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!