一种基于深度学习的复杂背景行人检测方法与流程
本发明涉及计算机视觉和人工智能
技术领域:
,具体涉及一种基于深度学习的复杂背景行人检测方法。
背景技术:
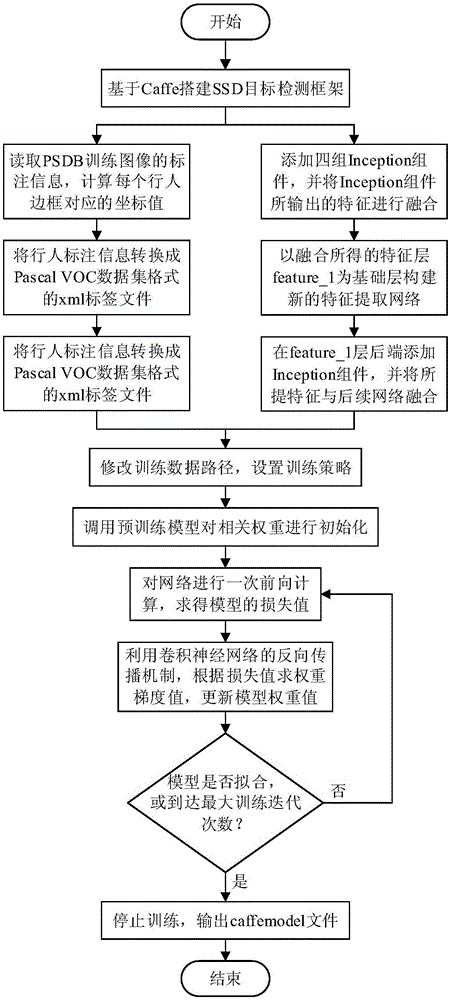
:行人检测即判断输入的图像或视频序列中是否存在行人,并确定其位置。行人检测是目标检测的一个分支,也是目标检测领域的研究热点和难点,其在自动驾驶、视频监控和智能机器人等人工智能领域中具有广泛的应用。同时,行人检测也是许多计算机视觉任务的前提和基础,如行人结构化、行人行为分析和行人再识别等任务,都需要先对输入数据中的行人做出检测才能进行后续的工作。因此,有效的行人检测方法具有重要的研究意义与迫切的实际需求。行人检测技术在20世纪90年代就开始引起了人们的关注,许多学者围绕该领域开展研究,诞生了多种不同类型的行人检测方法,较为经典的有基于机器学习的行人检测方法。基于机器学习的行人检测研究主要集中于2005至2011年这段时间内,从行人描述特征着手,可将此阶段产生的方法分为基于全局特征的方法、基于人体部件特征的方法和基于立体视觉特征的方法三大类。dalal和triggs在2005年提出梯度方向直方图(histogramoforientedgradient,hog)的概念,并在发表于cvpr(ieeeconferenceoncomputervisionandpatternrecognition)会议上的论文《histogramsoforientedgradientsforhumandetection》中将其用于行人检测,该算法在mit行人数据库上获得近乎100%的检测成功率,在包含视角、光照和背景等变化的inria行人数据库上,也取得了大约90%的检测成功率。mikolajczyk等人在eccv(europeanconferenceoncomputervision)会议上发表论文《humandetectionbasedonaprobabilisticassemblyofrobustpartdetectors》,将人体分成人脸、头肩部以及腿部,然后对每个部分采用sift(scaleinvariantfeaturetransform)特征进行描述,该方法在mit行人库上取得了不错的检测效果。hattori等人在bmvc(britishmachinevisionconference)会议上发表论文《stereo-basedpedestriandetectionusingmultiplepatterns》,提出对左右视角的多个图像进行roi(regionofinterest)提取,并将其用于模式分类,降低了目标检测的误检率。基于机器学习的行人检测方法采取人工提取特征的方式,其往往具有片面性和主观性,且存在特征提取能力不足的缺点。最近,深度学习以其端到端的训练方式及强大的特征提取能力,在计算机视觉领域引起了一大批学者的关注。在目标检测和行人检测领域,研究者们也纷纷尝试将深度学习应用到目标检测和行人检测任务中。2014年girshick等人在cvpr会议上发表论文《richfeaturehierarchiesforaccurateobjectdetectionandsemanticsegmentation》,创新性地提出了“候选窗口生成+特征提取+候选窗口分类”的三段式区域卷积神经网络(regionbasedconvolutionalneuralnetwork,r-cnn)目标检测方法,并取得优异的检测效果。虽然r-cnn在精确度上有较大的提升,但是其速度非常慢,处理一张图片大约需要200秒。随后,girshick等人又于2015年分别在iccv(ieeeinternationalconferenceoncomputervision)会议和internationalconferenceonneuralinformationprocessingsystems会议上发表论文《fastr-cnn》和《fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetworks》,提出检测速度更快、检测精确度更高的目标检测框架fastr-cnn和fasterr-cnn,形成r-cnn系列目标检测算法。与r-cnn系列方法不同,redmon等人在cvpr会议上发表论文《youonlylookonce:unified,real-timeobjectdetection》,提出yolo目标检测模型,该模型通过直接回归的方法在实现较好检测精确度的同时极大提升检测速度。liu等人在eccv会议上发表论文《ssd:singleshotmultiboxdetector》,其在yolo模型的基础上进行改进,提出ssd目标检测框架,进一步提升检测速度与精确度。上面主要讲述的是近几年基于深度学习的目标检测方法的发展历程,行人检测的方法大都是在通用目标检测方法的基础上进行一些修改,因此主要的发展路径大体一致。当前基于深度学习的行人检测主要包括两大类:一是将传统方法与神经网络相结合,先使用传统方法进行初步检测,然后将检测结果作为神经网络的输入,去掉传统方法在初步检测过程中产生的误检窗口。这一类方法一定程度上减少了误检窗口,然而,深度学习在此过程中扮演分类器的角色,算法的检测精确度主要依赖于传统方法,并且无法形成端到端的检测框架,需要人工参与部分特征的提取。第二类方法是将现有目标检测框架进行修改后使用行人数据进行训练,利用训练好的模型来完成行人检测任务。这类方法虽然取得了一定的效果,但是并未深究什么样的网络结构更适合于行人检测。基于深度学习的行人检测方法虽然在许多公开数据集上(如inria行人数据库等)取得了不错的检测效果,但是对于背景较为复杂的数据集或贴近现实生活的图像或视频数据,此类算法的表现却差强人意。当前针对复杂背景行人检测的研究相对较少,zhao等人在专著intelligentcomputingtheoriesandapplication上发表论文《pedestriandetectionbasedonfastr-cnnandbatchnormalization》,其将edgeboxes算法和fastr-cnn模型相结合,提出了一种针对复杂背景的行人检测方法,该方法先使用edgeboxes算法提取一系列候选框,再将提取的候选框作为输入数据训练修改过的fastr-cnn模型,最后使用训练好的fastr-cnn模型实现行人检测。虽然其所提算法在检测性能上有一定的提升,但距离直接应用于现实生活还存在一定差距,因此需要寻找有效的复杂背景行人检测方法,以解决复杂背景下的行人检测问题。技术实现要素:本发明的目的在于克服现有技术的缺点与不足,提供一种基于深度学习的复杂背景行人检测方法,该方法有效地克服了现有技术在复杂背景下行人检测准确率低和漏检率高等缺点,增强了ssd框架的鲁棒性,提升了该框架在复杂背景下的行人检测性能。本发明基于ssd目标检测框架通过加宽和加深神经网络的方式,结合inception组件、特征融合方式的特点,提出一种基于深度学习的复杂背景行人检测方法,通过在ssd特征提取网络前端添加inception组件,提升模型的特征提取能力,充分挖掘输入图像的背景信息。同时将inception组件所提取的特征进行融合,以此构建新的特征提取网络,接着再次添加inception组件,进一步提升模型的特征提取能力,并将所提取特征与网络后端的卷积层逐层进行融合,共享上下文信息,增强了模型的鲁棒性。本发明的目的可以通过如下技术方案实现:一种基于深度学习的复杂背景行人检测方法,所述方法包括以下步骤:步骤1、以分类网络vgg16为基础网络搭建ssd目标检测框架,将ssd目标检测框架中的分类参数修改为二分类,构建ssd行人检测框架;步骤2、分别在ssd行人检测框架训练神经网络的第一、二层特征提取层中间和第三、四层特征提取层中间各添加两组inception组件,替代原有卷积核大小为3x3的四层卷积层,且保持第三、四层特征提取层的宽度和高度一致,即输出特征尺寸均为10x10;步骤3、通过双线性插值的方式将第二、四层特征提取层的宽度和高度变换为38,得到新的第二、四层特征提取层,且其宽度和高度与第一层特征提取层一致,删除ssd行人检测框架训练神经网络的后两层特征提取层;步骤4、通过concatenation操作将含有inception组件的第一、二、四层特征提取层融合成新的特征提取层,以融合所得新特征提取层为基础层,逐层减小网络的宽度和高度,构建其它五层特征提取层,形成新的特征提取网络;步骤5、抽取新特征提取网络的第一层特征提取层,在其后端添加inception组件,通过pooling和concatenation操作将该inception组件的输出特征与特征提取网络的后五层特征提取层逐层进行融合,形成最终的特征提取网络;步骤6、在步骤3和步骤4所添加inception组件中的每层卷积层后端添加batchnormalization层,并在每个inception组件的融合特征层后端添加两层卷积核大小为1x1的卷积层,形成inception组件的最终输出特征;步骤7、获取训练图像并进行标注,使用ssd行人检测框架自带的数据增广操作对标注好的训练图像进行预处理,并以步骤2-5所得神经网络作为训练网络,修改ssd行人检测框架对应参数并设置训练策略,使用预处理后的训练图像训练模型,当模型达到最大训练次数或者拟合时停止训练;步骤8、设定iou交并比阈值、置信度阈值、非极大值抑制阈值,获取测试图像并调用训练好的模型进行前向计算得到检测结果,根据网络的检测结果在测试图像上画出相应的行人框,得到检测后的测试图像。进一步地,所述步骤1中,ssd目标检测框架为论文《ssd:singleshotmultiboxdetector》提出的目标检测框架,其包含基础网络、特征提取网络和分类检测模块三部分,其中基础网络负责初步特征提取,特征提取网络负责多尺度特征提取,分类检测模块负责对特征提取网络所提取的特征进行分类;ssd目标检测框架的默认输入尺寸大小为300x300;其中,基础网络为vgg16中的conv1_1-fc7层,其中vgg16的全连接层fc6、fc7被改为卷积核大小为3x3的卷积层;另外,ssd目标检测框架的特征提取网络包含六层特征提取层,分别为:conv4_3、fc7、conv6_2、conv7_2、conv8_2、conv9_2,其中conv4_3和fc7为基础网络vgg16的卷积层。进一步地,所述步骤2中,通过concatenation操作将卷积核大小分别为5x5、3x3、1x1的三层并联卷积层进行融合,组成inception组件,其中卷积核大小分别为5x5、3x3、1x1的三层并联卷积层的卷积核个数比为1:2:1,且卷积核大小为5x5的卷积层由两层卷积核大小为3x3的卷积层串联实现;新建fc6_inception、fc7_inception、conv7_1_inception、conv7_2_inception共四组inception组件,分别替换ssd行人检测框架训练神经网络中的fc6、fc7、conv7_1、conv7_2四层卷积层,替代默认的3x3卷积操作。进一步地,所述步骤3中,通过双线性插值的方式将fc7_inception、conv7_2_inception的输出转换为38x38尺寸的特征,使其宽度和高度与conv4_3层相同,分别得到fc7_interp、conv7_2_interp,删除ssd行人检测框架训练神经网络中原有的特征提取层conv8_2和conv9_2。进一步地,所述步骤4中,通过concatenation操作将含有inception组件的conv4_3、fc7_interp、conv7_2_interp融合成新的特征提取层feature_1,以特征提取层feature_1为基础层构建特征提取层feature_2、feature_3、feature_4、feature_5、feature_6,形成新的特征提取网络。进一步地,所述步骤5中,在特征提取层feature_1后端添加inception组件,得到特征层feature_1_inception,通过pooling和concatenation操作将feature_1_inception层逐层与feature_2、feature_3、feature_4、feature_5、feature_6融合,形成最终的特征提取网络,其包含六层特征提取层,分别为feature_1、feature_2、feature_3、feature_4、feature_5、feature_6,所包含六层特征提取层所对应的尺寸大小分别为:38x38、19x19、10x10、5x5、3x3、1x1。进一步地,所述步骤5中,feature_1后端所添加inception组件的构建方式及卷积核个数占比与步骤2一致。进一步地,所述步骤6中,inception组件融合特征层后端添加的卷积层的卷积核个数等于卷积核大小分别为5x5、3x3、1x1的三层并联卷积层的卷积核个数之和。进一步地,所述步骤7中,修改ssd行人检测框架对应参数包括修改学习率参数、设置训练最大迭代次数、设置学习率更新策略。进一步地,所述步骤8中,测试网络输出结果包含测试图像名称、行人边框置信度及行人边框坐标值。本发明与现有技术相比,具有如下优点和有益效果:1、本发明提供的一种基于深度学习的复杂背景行人检测方法,在行人检测任务上使用深度学习技术代替手工提取特征,利用卷积神经网络强大的表征能力来充分获取输入图像的行人特征,提升了行人检测方法的整体检测性能。2、本发明基于ssd目标检测框架,创新性地结合inception组件、特征融合等多种特性,在ssd特征提取网络前端添加inception组件,提升对应隐藏层的特征提取能力,充分挖掘图像背景信息,并将所提特征进行融合,以此构建新的特征提取网络;后续在新特征提取网络第一层后端再次添加inception组件,并将所提取特征逐层与后端的隐藏层融合,共享上下文信息,增强了模型的鲁棒性,提高了模型在复杂背景下的行人特征提取能力,从而实现了复杂背景行人检测准确率和召回率的提升。3、本发明选择在ssd特征提取网络上进行相应修改,增加ssd特征提取网络的复杂度,提高其特征提取能力,由于该段神经网络特征层宽度和高度均较小,最大宽度和高度为38,最小宽度和高度为1,因此,增加该段神经网络的复杂度不会导致模型参数量的急剧增加,保证模型在训练阶段依旧可以较快达到拟合,且在提高模型特征提取能力的同时不会导致模型检测速度的大幅度下降,保证模型的实时性,使得模型依旧具备实时检测的能力。附图说明图1为本发明方法的复杂背景行人检测模型的训练流程框图。图2为本发明方法的复杂背景行人检测模型的测试流程框图。图3为本发明方法的复杂背景行人检测模型的网络结构图。图4为本发明方法所添加inception组件的结构框图。图5为本发明实施例中测试结果的p-r曲线图。图6为本发明实施例模型训练过程的map值曲线图。图7为本发明实施例的检测结果对比图,其中,图7(a)、图7(c)、图7(e)、图7(g)为ssd模型的检测效果图,图7(b)、图7(d)、图7(f)、图7(h)分别为对应的本发明方法的检测效果图。具体实施方式下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。实施例:本实施例提供了一种基于深度学习的复杂背景行人检测方法,包括复杂背景行人检测模型训练和复杂背景行人检测模型测试两部分。图1所示为本发明的复杂背景行人检测模型的训练流程框图,主要包括ssd目标检测框架搭建、训练神经网络修改、lmdb格式训练数据生成、模型训练策略设置、反向传播更新权重、已拟合模型参数保存等步骤。图2则表示本发明的复杂背景行人检测模型的测试流程框图,主要包括测试神经网络修改、lmdb格式测试数据生成、测试模型调用、测试图像读取、测试网络前向计算、检测结果输出及保存等步骤。图3分别本发明方法的网络结构图,与ssd相比,本发明方法结合了inception组件、特征融合等多种特点,通过加宽和加深网络的方式提高模型的特征提取能力,充分挖掘输入图像的背景信息,增加模型的复杂度来提高模型的表征能力,同时在保证检测精确度提升的同时不会导致模型检测速度的大幅度下降。下面分别以psdb数据集所划分的训练图像和测试图像作为训练数据和测试数据来详细介绍本发明的实施过程,实施例主要基于caffe版的ssd模型实现。psdb(cuhk-sysupersonsearchdataset,也称personsearchdatabase)数据集是香港中文大学多媒体实验室王晓刚研究组发布的行人检测数据集,该数据集由拍摄图像和视频截图组成,共18184幅图像,与其它数据集相比,该数据集收集了数百个生活场景(如地铁、商场、公园等)的图像,具有多场景、背景复杂、多视角、光照变化大等特点。另外,该数据集选择电影和电视剧作为收集图像的另一个来源,使数据集的场景和图像的内容更加丰富,同时也使得该数据集更具有挑战性。psdb数据集共有训练图像11206张,测试图像6978张,全部图像中有12490幅图像由电子设备拍摄于各类生活场景,包括夜间、阴天、雨天、室内及室外等;另外的5694幅图像来源于电影或电视剧的截图。由于psdb数据集中有许多图像背景较为复杂,检测难度较大,符合本发明的实施要求,故选择该数据集作为实施例的训练数据和测试数据。实施例通过本发明的方法,将背景较为复杂的psdb测试图像中的行人检测出来,并给出精确的行人坐标框及其对应的置信度,其模型训练流程如图1所示,对应的模型测试流程如图2所示,模型的网络结构图如图3所示。实施具体步骤如下:第一步,框架搭建及修改。基于caffe搭建ssd目标检测框架,并使用python编程语言执行ssd_pascal.py文件,生成适用于pascalvoc数据集的多分类ssd模型。修改上述ssd模型的训练网络和测试网络中的相关类别参数,将其由21类分类网络修改为二分类网络,使其适用于行人检测。第二步,psdb数据集格式转换。从psdb数据集的标注文件中读取行人边框标注信息,计算每个行人框所对应的坐标值。以pascalvoc数据集的格式为标准生成psdb数据集中每幅图像所对应的xml标签文件,共生成18184份xml标签文件,包含行人框99809个。第三步,生成训练数据与测试数据。将psdb数据集所划分的训练图像和测试图像与相应的xml标签文件一一对应起来,并分别创建txt文件保存图像与xml的对应信息。运行create_data.sh文件读取相应的图像和xml标签文件生成lmdb格式的训练数据和测试数据。第四步,修改训练神经网络,提高模型特征提取能力。删除fc6、fc7、conv7_1、conv7_2共四层特征提取层,添加fc6_inception、fc7_inception、conv7_1_inception、conv7_2_inception共四组inception组件,分别替换删除的四层卷积层,且保持conv7_2_inception的宽度和高度与conv6_2层的尺寸相同,即输出特征尺寸均为10x10。上述添加的inception组件由三层卷积核大小分别为5x5、3x3、1x1的卷积层并联组成,其中卷积核大小分别为5x5、3x3、1x1的三层并联卷积层的卷积核个数比为1:2:1,且卷积核大小为5x5的卷积层由两层卷积核大小为3x3的卷积层串联实现。在所添加inception组件中的每层卷积层后端添加batchnormalization层,并在每个inception组件的融合特征层后端添加两层卷积核大小为1x1的卷积层,形成inception组件的最终输出特征,本发明所添加inception组件的结构框图如图4所示。新建interp层通过双线性插值的方式将fc7_inception、conv7_2_inception的宽度和高度变换为38,分别得到特征提取层fc7_interp、conv7_2_interp,删除训练神经网络中原有的特征提取层conv8_2和conv9_2。新建concat层将含有inception组件的conv4_3、fc7_interp、conv7_2_interp融合成新的特征提取层feature_1,以特征提取层feature_1为基础层,设置卷积核大小为3x3,逐层减小网络的宽度和高度,构建特征提取层feature_2、feature_3、feature_4、feature_5、feature_6,形成新的特征提取网络。第五步,修改训练神经网络,共享上下文信息。在第四步的基础上,在特征提取层feature_1后端添加inception组件,得到特征层feature_1_inception,接着对feature_1_inception层通过五次pooling操作得到五层尺寸不同的特征层:feature_1_pool1、feature_1_pool2、feature_1_pool3、feature_1_pool4、feature_1_pool5,且保持这五层特征层的宽度和高度分别与feature_2、feature_3、feature_4、feature_5、feature_6相同,接着通过concatenation操作将五次pooling操作所得的五层特征层分别与feature_2、feature_3、feature_4、feature_5、feature_6层进行融合,并将融合所得特征进行一次3x3卷积操作之后送进ssd模型的检测模块进行分类和回归。至此,完成本发明所提方法的训练神经网络的修改,网络结构图如图3所示。第六步,设置模型训练策略。设置训练batch_size=16,iter_size=2,最大训练迭代次数max_iter=100000,设置优化函数为sgd(stochasticgradientdescent,随机梯度下降),动量参数momentum=0.9,初始学习率base_lr=0.0005,在第80000次迭代之后将学习率缩小10倍。第七步,模型训练与保存。修改第五步所得训练神经网络的训练数据路径,将其指向lmdb格式的psdb训练数据集,以论文《ssd:singleshotmultiboxdetector》的作者weiliu所提供的vgg_ilsvrc_16_layers_fc_reduced.caffemodel文件作为预训练模型,输入相关参数运行caffe开始训练,利用卷积神经网络的反向传播机制不断更新模型权重值,降低模型的损失值,当模型拟合或者达到最大训练迭代次数,停止训练并保存模型权重值,输出对应的caffemodel文件。第八步,修改测试神经网络,提高模型特征提取能力。删除fc6、fc7、conv7_1、conv7_2共四层特征提取层,添加fc6_inception、fc7_inception、conv7_1_inception、conv7_2_inception共四组inception组件,分别替换删除的四层卷积层,且保持conv7_2_inception的宽度和高度与conv6_2的尺寸相同,即输出特征尺寸均为10x10。上述添加的inception组件由三层卷积核大小分别为5x5、3x3、1x1的卷积层并联组成,其中卷积核大小分别为5x5、3x3、1x1的三层并联卷积层的卷积核个数比为1:2:1,且卷积核大小为5x5的卷积层由两层卷积核大小为3x3的卷积层串联实现。在所添加inception组件中的每层卷积层后端添加batchnormalization层,并在每个inception组件的融合特征层后端添加两层卷积核大小为1x1的卷积层,形成inception组件的最终输出特征,本发明所添加inception组件的结构图如图4所示。新建interp层通过双线性插值的方式将fc7_inception、conv7_2_inception的宽度和高度变换为38,分别得到特征提取层fc7_interp、conv7_2_interp,删除训练神经网络中原有的特征提取层conv8_2和conv9_2。新建concat层将含有inception组件的conv4_3、fc7_interp、conv7_2_interp融合成新的特征提取层feature_1,以特征提取层feature_1为基础层,设置卷积核大小为3x3,逐层减小网络的宽度和高度,构建特征提取层feature_2、feature_3、feature_4、feature_5、feature_6,形成新的特征提取网络。第九步,修改测试神经网络,共享上下文信息。在第八步的基础上,在特征提取层feature_1后端添加inception组件,得到特征层feature_1_inception,接着对feature_1_inception层通过五次pooling操作得到五层尺寸不同的特征层:feature_1_pool1、feature_1_pool2、feature_1_pool3、feature_1_pool4、feature_1_pool5,且保持这五层特征层的宽度和高度分别与feature_2、feature_3、feature_4、feature_5、feature_6相同,接着通过concatenation操作将五次pooling操作所得的五层特征层分别与feature_2、feature_3、feature_4、feature_5、feature_6层进行融合,并将融合所得特征进行一次3x3卷积操作之后送进ssd模型的检测模块进行分类和回归。至此,完成本发明所提方法的测试神经网络的修改,网络结构图如图3所示。第十步,模型测试并输出测试结果。修改第九步所得测试神经网络的训练数据路径,将其指向lmdb格式的psdb测试数据集,设定iou交并比阈值、置信度阈值,调用第七步所保存的caffemodel文件作为测试模型,输入相关参数运行caffe调用测试模型对测试网络参数进行初始化,读取测试图像并对测试网络进行前向计算得到测试结果,最后将测试结果存储于txt文件中,包含测试图像名称、检出行人框坐标值及该矩形框所对应的置信度。使用python编程语言执行plot_detections.py文件,在测试图像上绘制所检测出的行人框,并在行人框上方显示其置信度。为了验证本发明方法的可行性以及检验该方法的各项性能,本发明在caffe深度学习框架上对所提方法进行仿真。实验选择psdb数据集中的训练图像作为训练数据,共有训练图像11206张。同样,选择psdb数据集中的测试图像作为测试数据,共有测试图像6978张。程序运行平台为linux-ubuntu16.04操作系统,所使用的gpu型号为nvidiageforcegtx1080ti,gpu显存为11g,详细训练参数设置为:batch_size=16,iter_size=2,最大训练迭代次数max_iter=100000,优化函数为sgd(stochasticgradientdescent,随机梯度下降),动量参数momentum=0.9,初始学习率base_lr=0.0005,且在第80000次迭代之后将学习率缩小10倍;详细测试参数设置为:batch_size=1,test_iter=6978,iou交并比阈值overlap_threshold分别取0.25、0.50、0.75,nms非极大值抑制阈值nms_threshold=0.45,置信度阈值confidence_threshold的取值范围为0.1-0.9,步进为0.1。为了更好地验证本发明所提方法的有效性,将本发明方法的测试结果与默认的ssd框架的测试结果进行对比,在检测准确率、召回率、模型收敛速度等方面对本发明方法进行分析评价,为了保证实验数据的有效性及公平性,本次实验ssd模型与本发明方法的实验环境和所有实验参数均相同。表1、2、3列举了ssd模型和本发明方法的各项检测结果,以及这两个模型的对比数据。其中“原始数据”表示psdb测试集所包含的数据,其它三列分别表示ssd的检测结果、本发明方法的检测结果、本发明方法对比于ssd模型的提升量。“height<60”表示高度小于60个像素值的行人框数量,由于psdb数据集只标注了高度大于50个像素值的行人,故该项也表示高度位于50-60像素值的行人数量,“60≤height<200”和“200≤height”则分别表示行人高度位于60-200像素值以及行人高度大于200个像素值的行人数量。另外,表1的测试数据所对应的测试参数为:iou交并比阈值overlap_threshold=0.25,nms非极大值抑制阈值nms_threshold=0.45,置信度阈值confidence_threshold=0.50,两种方法的实验环境及其他实验参数全部保持一致。表1对比项原始数据ssd本发明方法提升量height<60193916575559060≤height<200223291291313805892200≤height136421075211001249正样本数量3791023830255611731检测框数量-25120266141494召回率-58.30%62.54%4.24%准确率-94.86%96.04%1.18%map-81.80%83.75%1.95%由表1的数据可知,本发明方法在所有对比指标上的检测结果均优于ssd模型。其中对于高度小于60个像素值的行人框,psdb测试集原有的数量为1939个,ssd模型只检测出了165个,召回率约为8.51%,漏检率高达91.49%,而本发明方法检测出了755个,召回率约为38.94%,相比于ssd模型提高了30.43%;对于高度位于60-200像素值的行人,本发明方法也有较大的提升,比ssd模型多检测出了892个行人框;对于高度大于200像素值的行人,ssd模型和本发明方法的召回率分别为78.82%和80.64%,该项两个模型的召回率均高于75%,虽然提升空间有限,但本发明方法依旧比ssd模型多检测出了249个行人框。另外,本发明方法在整体召回率和map(meanaverageprecision)等指标上与ssd模型相比均有所提升。表2和表3分别为iou交并比阈值overlap_threshold=0.50和0.75时两种方法的检测结果,测试环境及其他测试参数与表1相同。随着iou交并比阈值的提高,两种方法对应的检测精确度均有所下降。对比表1、2、3可以发现,在iou交并比阈值overlap_threshold取值不同的情况下,本发明方法的检测结果均优于ssd模型。表2对比项原始数据ssd本发明方法提升量height<6019399647037460≤height<200223291257013441871200≤height136421060810913305正样本数量3791023274248241550检测框数量-25120266141494召回率-56.94%60.73%3.79%准确率-92.65%93.27%0.62%map-76.57%78.09%1.52%表3对比项原始数据ssd本发明方法提升量height<6019392312410160≤height<2002232988689743875200≤height1364288809373493正样本数量3791017771192401469检测框数量-25120266141494召回率-43.48%47.07%3.59%准确率-70.74%72.29%1.55%map-45.52%47.10%1.58%图5是测试结果的p-r曲线图,纵坐标表示检测准确率(precision),横坐标表示检测召回率(recall),设置不同的置信度阈值求得多对p-r值,将多对p-r值绘制成相应的p-r曲线。红色曲线为本发明方法的p-r曲线,绿色为ssd模型的p-r曲线,其中iou交并比阈值overlap_threshold=0.5,nms非极大值抑制阈值nms_threshold=0.45,置信度阈值confidence_threshold的最大值为0.9,最小值为0.1,步进为0.1,每种方法包含9对p-r值。由图可知,在曲线的右上角部分,本发明方法在相同的准确率下召回率高于ssd模型,虽然ssd模型在曲线的右下角取得较高的召回率,但其在取得高召回率率的同时准确率却低于30%,而本发明方法的9对p-r值的准确率均高于60%,图5表明本发明方法的整体性能优于ssd模型。图6是本发明方法与ssd模型训练过程中的map值曲线图。其中横坐标表示训练迭代次数,纵坐标表示map值,红色曲线为本发明方法的map值变化曲线,绿色为ssd模型的map值变化曲线。以模型开始训练为起点,每进行一万次迭代后使用测试数据集进行测试并求得相应的map值。如图6所示,整个训练过程中,两种方法的map值变化趋势基本一致,说明了本发明方法的模型训练收敛速度与ssd模型大致相同,表明了本发明方法对训练网络的修改不会增加模型的训练难度。图7是实施例检测结果对比图,如图所示,左边一列,即图7(a)、图7(c)、图7(e)、图7(g)为ssd模型的检测效果图,右边一列,即图7(b)、图7(d)、图7(f)、图7(h)为对应的本发明方法的检测效果图。由图可知,在背景较为复杂的场景下,如夜间环境,室内环境、街道场景等,相比与ssd模型,本发明方法能更好地检测出图像中的行人,证明了本发明方法在复杂背景下具有较强的行人检测能力。上述实施例通过设置不同阈值并从多个角度将本发明方法的测试结果与ssd模型的测试结果进行对比,由对比结论可知,本发明方法以psdb数据集作为训练数据和测试数据,在不同的对比条件下检测结果优于ssd模型,且模型的训练收敛速度与ssd模型相当,证明了本发明方法的有效性。以上所述,仅为本发明专利较佳的实施例,但本发明专利的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明专利所公开的范围内,根据本发明专利的技术方案及其发明专利构思加以等同替换或改变,都属于本发明专利的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1