一种面向缺陷补丁代码的软件缺陷原因自动分析方法与流程
本发明属于软件维护领域,特别是一种面向缺陷补丁代码的软件缺陷原因自动分析方法。
背景技术:
随着软件项目规模的增加和软件产品自身的不断演化,软件缺陷的数量也随之产生了巨大的增长。传统的以人工方式分析缺陷原因、定位和修复缺陷已无法满足快速修复缺陷的需求。在开源的软件缺陷跟踪系统缺陷库中存储了大量的已修复缺陷的修复代码,这些修复代码暗含着各种缺陷相关的概念知识,如缺陷修复模式。因此,分析和表征缺陷修复代码可以有效地辅助开发人员快速地理解缺陷原因,并定位和修复缺陷。
目前对缺陷代码分析和描述的技术大体分为两类:一类将代码类同于自然语言,使用基于信息检索的技术来计算代码词汇和缺陷报告自然语言词汇的文本相似度,从而辅助缺陷自动定位。但这些方法存在两个问题,第一是词汇不匹配问题:缺陷报告中用于描述缺陷的术语与源文件中使用的术语和代码词不同;第二是未考虑源代码包含的大量特定的概念知识,如代码元素类型和代码结构信息。另一类是着重于代码的结构,采用基于树形结构的差分算法来提取代码在树形结构上的变化,从历史缺陷修复中得到修复实例,辅助缺陷自动修复。这类方法往往偏向对代码本身的研究,忽略了缺陷与修复代码之间的联系,例如缺陷原因与代码修复模式的相关性。并且这类方法一般用在特定类型的缺陷修复模式的提取,通用性较差。
技术实现要素:
本发明所解决的技术问题在于从多角度刻画软件缺陷修复代码,研发出软件缺陷修复代码的多元表示方法和缺陷的自动分类方法。
实现本发明目的的技术解决方案为:一种面向缺陷补丁代码的软件缺陷原因自动分析方法,包括以下步骤:
步骤1、从缺陷库中抽取已修复缺陷的缺陷报告和修复代码文件,获得缺陷数据集;
步骤2、自定义缺陷产生原因类别,并根据该缺陷产生原因类别对缺陷数据集进行分类标记;
步骤3、利用代码区分工具从步骤1获得的修复代码文件中划分出与修复相关的代码块;
步骤4、从步骤3获取的代码块中提取代码元素术语、修复模式;
步骤5、根据步骤4获取的代码元素术语、修复模式构建缺陷修复代码的修复树;
步骤6、将构建的缺陷修复代码的修复树转化为向量形式,获得修复代码的向量表示;
步骤7、将步骤6获取的修复代码的向量表示及在步骤2标记的分类标签作为卷积神经网络模型的输入,自动学习获取缺陷的原因分类模型,从而完成软件缺陷原因自动分析。
本发明与现有技术相比,其显著优点为:1)本发明使用代码元素术语、代码元素概念类型、代码修复操作多角度来综合表示缺陷修复代码,这种表示同时包含文本词汇语义特征、概念类型语义特征和结构语义特征;2)本发明利用代码修复模式和缺陷原因分类在ast层次结构上的对应关系,将缺陷代码修复模式与缺陷原因分类紧密相连;3)本发明采用基于树形结构的表示学习方法表示缺陷修复代码的修复树,这种表示方法包含了上述多角度的修复代码特征,将这种表示作为深度学习模型的输入,利用深度学习模型可以自动学习数据特征的优点,得到缺陷原因分类器,能更有效地辅助开发者查找缺陷产生原因。
下面结合附图对本发明作进一步详细描述。
附图说明
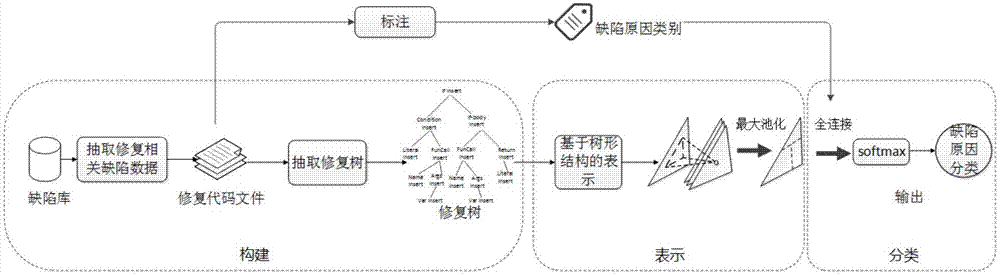
图1为本发明面向缺陷补丁代码的软件缺陷原因自动分析方法的流程图。
图2为本发明实施例中抽取的mozilla项目和radare2项目的缺陷原因分布图。
图3为本发明实施例中抽取的一个缺陷修复前后区分代码截图。
图4为本发明实施例中ast结构的修复树示意图。
具体实施方式
结合图1,本发明一种面向缺陷补丁代码的软件缺陷原因自动分析方法,步骤如下:
步骤1、从缺陷库中抽取已修复缺陷的缺陷报告和修复代码文件,获得缺陷数据集。
步骤2、自定义缺陷产生原因类别,并根据该缺陷产生原因类别对缺陷进行分类标记,获得缺陷产生原因类别的代码数据集。其中,自定义缺陷的产生原因类别如下表1所示:
表1本发明中使用的缺陷原因分类表
步骤3、利用代码区分工具从步骤1获得的修复代码文件中划分出与修复相关的代码块。其中,划分与修复相关的代码块时,划分粒度为完整的ast树形结构。
步骤4、从步骤3获取的代码块中提取代码元素术语、修复模式,具体为:
步骤4-1、利用预定义的规则从步骤3获取的代码块中提取代码元素术语;
其中,代码元素术语即代码文本词,包括标识符、字面量和操作符;
预定义的规则为:去掉编程语言的关键词,去掉除运算符之外的常用符号;
步骤4-2、利用基于抽象语法树的提取技术并结合代码区分工具,从步骤3获取的代码块中提取修复模式;
其中,修复模式包括代码元素概念类型和修复操作;代码元素概念类型为代码元素在代码中的角色,修复操作为对代码元素的修改操作。
步骤5、根据步骤4获取的代码元素术语、修复模式构建缺陷修复代码的修复树,具体为:
基于抽象语法树构建修复树,其中每个节点为对一个抽象语法树节点的修复,包括该节点涉及的代码元素术语、代码元素概念类型和对其的修复操作。
步骤6、将构建的缺陷修复代码的修复树转化为向量形式,获得修复代码的向量表示,转化为向量形式采用的方法为基于树形结构的表示学习方法,具体为:
步骤6-1、修复树的叶子节点由其直接向量表示,而非叶子节点由组合向量表示;
所述组合向量为非叶子节点的直接向量和其子节点表示的线性组合,其中,子节点为叶子节点或非叶子节点;
假设c1,…,cn为非叶子节点p的子节点,p的组合向量表示为:
p=wcomb1·vec(p)+wcomb2·tanh(∑liwcode,i·vec(ci)+bcode)
式中,vec(·)为节点的直接向量,
所述直接向量为相关代码元素项、该元素的概念类型和修复动作的直接向量的线性组合,某一个节点f的直接向量表示为:
f=wfe·vec(fe)+wft·vec(ft)+wfa·vec(fa)
式中,vec(fe)、vec(ft)、vec(fa)分别为代码元素术语、代码元素概念类型、修复操作的直接向量;
由上可知,修复树的每个节点都表示为分布式的实值向量
步骤6-2、在基于树形结构的神经网络中应用特征检测器在修复树上滑动以检测提取步骤6-1所述表示方法中的特征,假设修复树有n个节点,则特征检测器的输出为:
式中,
步骤7、将步骤6获取的修复代码的向量表示及在步骤2标记的分类标签作为卷积神经网络模型的输入,自动学习获取缺陷的原因分类模型,具体为:
步骤7-1、利用单向池的标准动态池层聚合所述特征检测器提取的所有特征;
步骤7-2、将步骤1的缺陷数据集划分成训练集和测试集;
步骤7-3、将聚合后的特征作为卷积神经网络模型输出层的输入,即将步骤6获取的修复代码的向量表示及在步骤2标记的分类标签作为卷积神经网络模型的输入,利用卷积神经网络模型对所述训练集进行验证,之后对所述测试集进行交叉验证获得缺陷自动分类器,完成对历史缺陷的按产生原因自动分类。
下面结合实施例对本发明作进一步详细的描述。
实施例
结合图1,本发明面向缺陷补丁代码的软件缺陷原因自动分析方法,包括以下步骤:
步骤1、本实施例中使用mozilla、radare2缺陷库作为数据,考虑到缺陷数据的准确性,采用关键词匹配搜索和爬虫技术将状态为fixed(已修复)和verified(已验证)的历史缺陷筛选出来,并提取这些历史缺陷提交信息里的前后代码片段,作为实验的数据集。图3为抽取的其中一个缺陷的修复前后区分代码示意图。
步骤2、定义缺陷的产生原因类别,如上表1所示。将步骤1获得的缺陷数据集按缺陷数量3:1:1的比例划分成训练集、验证集和测试集。人工分析数据集中的缺陷报告和修复代码,对数据集中的每条缺陷都按定义的缺陷产生原因做一个原因分类标注。其中缺陷原因分类标注时使用缺陷原因分类的19个子类型。图2为本实施例中抽取的mozilla项目和radare2项目的缺陷原因数量分布图。
步骤3、使用代码区分工具从步骤1获得的修复代码文件中提取出已修复缺陷的提交信息里的修复前后的代码片段,并将修复代码片段划分成具有独立ast结构的代码块;以图3所示的缺陷修复代码为例,其中一个与修复相关的if语句:if(0==strlen(phones)){ckd_free(phones);return0;}为一个具有独立ast结构的代码块。
步骤4、使用预定义的规则提取步骤3获得的代码块的代码元素术语,使用基于抽象语法树(ast)的提取技术提取步骤3获得的代码块的包含代码元素概念类型和修复模式;
步骤4-1、使用预定义的规则提取步骤3获得的代码块的代码元素术语。以图3所示的缺陷修复代码和上述if语句为例,去掉常用符号和多余的空格,抽取代码元素词,得到每一个缺陷的代码元素术语。本实施例中的代码元素术语包含:‘0’,‘==’,‘strlen’,‘phones’,‘ckd_free’。
步骤4-2、借助基于ast提取的修复模式提取技术,提取ast级别的代码元素概念类型和修复操作。本实施例中提取的的代码元素概念类型及修复操作包含:“ifinsert”“conditioninsert”“if-bodyinsert”“literalinsert”“funcallinsert”“returninsert”“nameinsert”“argsinsert”“varinsert”。
步骤5、将步骤4获得的每个缺陷的代码元素术语、代码元素概念类型、修复操作结合起来构建修复树。如本实施例的缺陷修复代码表示添加了包含跳转语句的if语句块,其修复树的示意图如图4所示。为了直观表示,图4中省略了实际抽取了的每个节点的代码元素术语。从图4可以看出,修复树的每个节点为一个元修复模式,例如f1=(ifinsert,*),f2=(condtninsert,f1),f3=(if-bodyinsert,f1),f4=(literalinsert,f2),f5=(funcallinsert,f2),f6=(funcallinsert,f3),andf7=(returninsert,f3),等等。上述每个节点的形式化表示是fi=(eti,pti),其中eti是当前节点的修复,pti是其父节点的修复。可以看出f1与f2和f3分别是父子关系,其他情况类似,也就是说,它们嵌套在ast结构上。
步骤6、基于树形结构的表示学习方法将步骤5构建的修复树转化成向量形式,得到修复代码的向量表示。
步骤7、使用步骤6获得的修复代码的向量表示集合及其在步骤2标记的人工分类标签作为卷积神经网络模型的输入,自动学习得到缺陷的原因分类模型。如本实施例的缺陷,使用此分类模型得到其分类结果为:0302忽略了极端条件(见上述表1)。
本发明的方法从多个角度表示缺陷的修复代码,充分利用了修复代码中包含的概念知识,并且将这种表示与缺陷原因分类联系在一起,得到缺陷原因自动分类模型,能够更有效地辅助开发者定位和修复缺陷。
- 还没有人留言评论。精彩留言会获得点赞!