一种基于投影变换与字典学习的行人再识别的方法与流程
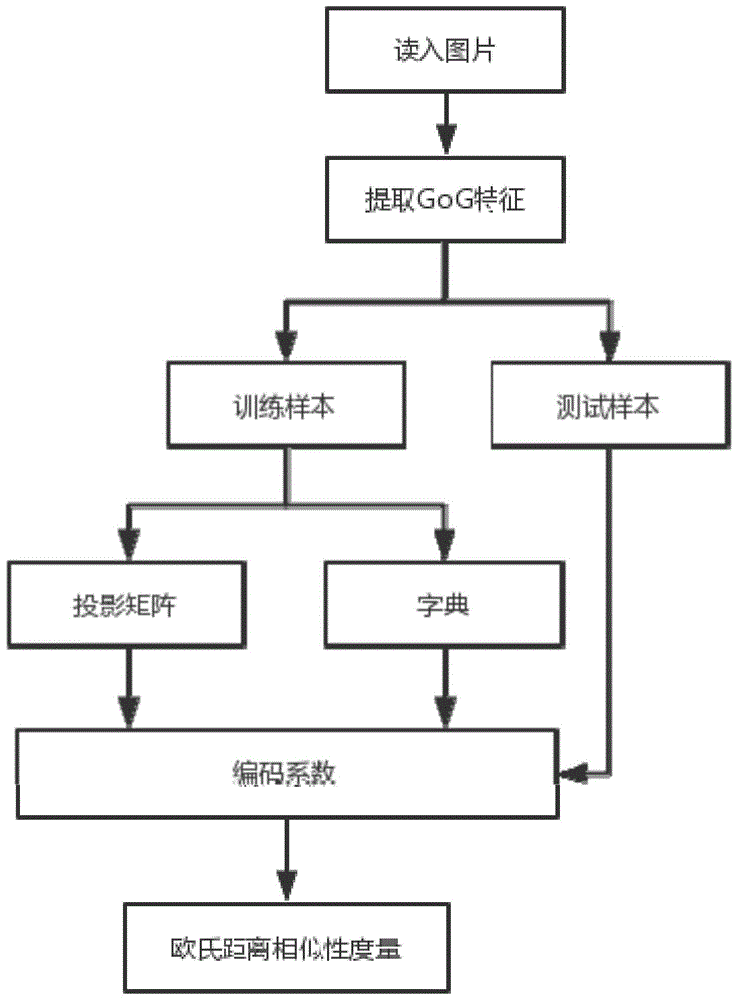
本发明涉及一种基于投影变换与字典学习的行人再识别的方法,属于数字图像识别
技术领域:
。
背景技术:
:随着视频监控系统大量的普及,仅仅依靠人工浏览和研判的方式来实现行人再识别耗费了大量的人力和物力,摄像机网络环境嘈杂、人为无法控制导致很难提升准确率。由于利用计算机视觉技术对跨视角识别指定的人具备快速性、高效性,使得行人重识别技术受到越来越多的关注。在最近这五年里,行人重识别在目标追踪和行为分析[2]等方面有着至关重要的应用。例如,在刑侦工作方面可用于跨视角的嫌疑犯追踪;在商业上,可以判断同一个客户对商场里商品的感兴趣程度。虽然,行人重识别有广阔的应用前景,但在现实生活场景中仍面临着巨大的挑战。因不同摄像机下行人的视角、姿态、光照强度、背景杂波、遮挡等发生显著的变化,这些变化导致同一个人在不同摄像机下外貌特征相差很大,很难判断是否是同一人,而不同的人因行人体型、姿态衣着等外貌特征相似比同一个人在不同的摄像头下更相似,区分开不同的人也极其困难。为了减轻这些变化,传统的方法主要有两种:一种是为行人设计鲁棒性和判别性的描述子,为了区分不同的人。郑等人认为行人在水平方向发生视角变化,在垂直方向上基本稳定不变,因此将行人图片在垂直方向上分成6个条带,再分别每个条带上提取hsv直方图颜色特征和gabor滤波纹理描述两种特征,串联形成最终的特征向量。度量学习就是使用训练集学习一个度量模型让同类人之间的差异性很小,不同类人之间的差异性很大。mignon等人通过pcca(pairwiseconstrainedcomponentanalysis)学习投影矩阵,将行人的特征投影到低维空间,在这个空间里,正样本特征之间的马氏距离小于某个阈值,同时负样本特征之间的马氏距离大于这个阈值。以上两种方法中,利用特征表示的方法直接提取特征进行匹配,不需要训练阶段,但颜色特征严重受光照条件的影响,纹理特征又受图像分辨率的影响,导致很难提取鲁棒性和判别性的特征,从而限制了算法的性能。技术实现要素:本发明要解决的技术问题是提供一种基于投影变换与字典学习的行人再识别的方法,以用于解决光照和姿态的变化,背景杂波、遮挡等导致的行人匹配困难问题。本发明的技术方案是:一种基于投影变换与字典学习的行人再识别的方法,包括如下步骤:step1、构建特征数据在两个视角下的训练样本、测试样本;step2、构建一种投影变换与字典学习的行人再识别方法的学习模型;step2.1、将原始的特征投影到低维的判别性空间,使同一行人之间特征的歧义性达到最小,不同行人特征的发散性达到最大;step2.2、引入不连贯性正则项其中,pa:a视角下的映射矩阵,pai表示pa中的第i列,pb:b视角下的映射矩阵,pbi表示pb中的第i列,ca:a视角下的行人编码系数,cai:为ca的第i列,cb:b视角下的行人编码系数,cbi:为cb的第i列,d:字典,di表示d中的第i列,α,λ均为大于0的实数,||·||f表示frobenius范数,||·||2表示l2范数,||·1表示l1范数,||·||2表示范数的平方运算符,t为矩阵的转置,如pt为矩阵p的转置;step3、迭代求解学习模型中映射矩阵pa和pb以及字典d,从而进行相似性度量;step4、将step1中提取的训练样本特征数据以及step3求得的投影矩阵和字典求得a,b视角下的编码系数再进行相似性度量,从而进行行人再识别。具体地,所述步骤step1的具体步骤如下:step1.1、从公开数据集上prid2011的图片提取gog特征;step1.2、然后对特征数据进行降维,降维后的每张图片的数据为一个列向量(n×1),作为一个行人在一个视角下的样本;所有行人在一个视角下的样本数据为特征矩阵(n×m),n为特征的维数,m为行人的个数;step1.3、再以同样的方法得到行人在另一个视角下的样本数据特征矩阵,分别得到在两个视角下的特征矩阵,随机选取一半行人特征为训练样本,剩下的一半行人特征和干扰图片特征为测试样本。具体地,所述步骤step3的具体步骤如下:step3.1、已知公式1,求解映射矩阵pa和pb;其中,λa为pa的拉格朗日对偶变量构成的对角矩阵;其中,λa为pb的拉格朗日对偶变量构成的对角矩阵;step3.2、已知公式1,使用admm算法迭代求解d,同时引入辅助变量b,t,且d=b,当第t+1次更新后的字典与第t次更新后的字典相差为0.0000001时,即|d(t+1)-dt|≤0.0000001时,迭代终止;其中,η为实数,取值为0.999。具体地,所述步骤step4的具体步骤如下:将step1中提取的训练样本特征数据以及step3求得的投影矩阵和字典求得a,b视角下的编码系数见公式5和6,再利用公式7进行相似性度量,从而进行行人再识别;其中,为两个不同视角编码系数列向量之间的距离,此距离最小时即再识别成功,不同视角编码系数列向量距离最小时编码系数所对应的行人为同一行人,表示编码系数中的第i列,表示编码系数中的第j列。具体地,所述的α,λ的值分别为0.4和0.0005。本发明的有益效果是:1、本发明的行人再识别方法对复杂背景及行人姿态变换的鲁棒性效果较好。2、本发明针对每个视角下行人的采用相应的投影矩阵,将特征投影到判别性低维空间,传统方法是直接使用行人的原始特征学习字典,使学习到字典性能有限,因此本发明提出的行人再识别方法相比其他方法辨别行人性能明显提升。附图说明图1为本发明的流程图;图2为行人再识别的匹配说明;图3为本发明使用的公共数据集prid2011的行人图像;图4为本发明使用的公共数据集prid2011上的干扰图片。具体实施方式下面结合附图和具体实施例,对本发明做进一步的说明。实施例1,如图1-4所示,一种基于投影变换与字典学习的行人再识别的方法,包括如下步骤:step1、构建特征数据在两个视角下的训练样本、测试样本;step2、构建一种投影变换与字典学习的行人再识别方法的学习模型;step2.1、将原始的特征投影到低维的判别性空间,使同一行人之间特征的歧义性达到最小,不同行人特征的发散性达到最大;step2.2、引入不连贯性正则项其中,pa:a视角下的映射矩阵,pai表示pa中的第i列,pb:b视角下的映射矩阵,pbi表示pb中的第i列,ca:a视角下的行人编码系数,cai:为ca的第i列,cb:b视角下的行人编码系数,cbi:为cb的第i列,d:字典,di表示d中的第i列,α,λ均为大于0的实数,||·||f表示frobenius范数,||·||2表示l2范数,||·||1表示l1范数,||·||2表示范数的平方运算符,t为矩阵的转置,如pt为矩阵p的转置;step3、迭代求解学习模型中映射矩阵pa和pb以及字典d,从而进行相似性度量;step4、将step1中提取的训练样本特征数据以及step3求得的投影矩阵和字典求得a,b视角下的编码系数再进行相似性度量,从而进行行人再识别。进一步地,所述步骤step1的具体步骤如下:step1.1、从公开数据集上prid2011的图片提取(gaussianofgaussian)gog特征;图3为prid2011数据集上的正样本,每一列为同一行人,图4为prid2011数据集上的干扰图片。step1.2、然后对特征数据进行降维,降维后的每张图片的数据为一个列向量(n×1),作为一个行人在一个视角下的样本;所有行人在一个视角下的样本数据为特征矩阵(n×m),n为特征的维数,m为行人的个数;step1.3、再以同样的方法得到行人在另一个视角下的样本数据特征矩阵,分别得到在两个视角下的特征矩阵,随机选取一半行人特征为训练样本,剩下的一半行人特征和干扰图片特征为测试样本。进一步地,所述步骤step3的具体步骤如下:step3.1、已知公式1,求解映射矩阵pa和pb;其中,λa为pa的拉格朗日对偶变量构成的对角矩阵;其中,λa为pb的拉格朗日对偶变量构成的对角矩阵;step3.2、已知公式1,使用(alternatingdirectionmethodofmultipliers)admm算法迭代求解d,同时引入辅助变量b,t,且d=b,当第t+1次更新后的字典与第t次更新后的字典相差为0.0000001时,即|d(t+1)-dt|≤0.0000001时,迭代终止;其中,η为实数,取值为0.999。进一步地,所述步骤step4的具体步骤如下:将step1中提取的训练样本特征数据以及step3求得的投影矩阵和字典求得a,b视角下的编码系数见公式5和6,再利用公式7进行相似性度量,从而进行行人再识别;其中,为两个不同视角编码系数列向量之间的距离,此距离最小时即再识别成功,不同视角编码系数列向量距离最小时编码系数所对应的行人为同一行人,表示编码系数中的第i列,表示编码系数中的第j列。进一步地,所述的α,λ的值分别为0.4和0.0005,这两个具体值在本方明中所使用的数据集上识别率更高。行人再识别(personre-identification)是利用计算机视觉技术判断图像序列(gallery集)中是否存在特定行人(probe集)的技术,如图2所示。图2中左边的一副为probe集,右边为gallery集,即从右边的gallery集找出与probe中相匹配的行人。表1为prid2011数据集本文中的方法和其他方法匹配率(%)比较,由表1可知,本发明与其他先进的方法在rank1,rank5,rank10,rank20上进行对比,结果如表1所示,虽然rank5比次好的匹配率低1.5%,但是rank1,rank10,rank20比次好的匹配率分别提升了2.5%,1.3%,0.9%。这表明本发明的算法具有较高的识别性能。方法rank1rank5rank10rank20lomo+kcca(2014)14.3037.4047.6062.50lomo+mfa(2014)22.3045.6057.2068.20lomo+klfda(2014)22.4046.5058.1068.60lomo+xqda(2015)26.7049.9061.9073.81gog+xqda(2016)35.960.168.578.1lomo+nullspace(2016)29.8052.9066.0076.50lomo+m(2017)15.236.148.360.4lomo+ladf(2017)16.234.0-59.5lomo+dmlv(2017)27.8048.4059.5072.70本发明的方法38.4058.6069.8079.00表1以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1