问询处理方法及系统与流程
本发明涉及自然语言处理领域,尤其涉及一种问询处理方法及系统。
背景技术:
随着人工智能技术的不断突破,特别是自然语言处理相关技术的提升,把自然语言处理技术应用到各个领域逐渐受到重视。例如在警务办公、办案过程中经常出现的问询场景即可以与目前语音处理技术相结合。以针对犯罪嫌疑人的审讯为例,警务人员通常需要将审讯内容进行记录,一方面该笔录作为嫌疑人的供述证据;另一方面,特别是对于团伙案件或者多嫌疑人参与的案件,警务人员通过隔离方式对涉案人员进行分时段或同步的逐个审讯,并在后期借由汇总多个涉案人员的审讯记录,能够对案件进行综合分析,例如从笔录中找出多人回答问题时的异同,以此挖掘案件侦破的突破点等。
但是目前的审讯流程中所采用的键盘记录、录音录像等手段,无法在审讯的同时动态地对当前问询内容进行快速比对,而且后期的综合分析过程还需要警务人员将多个涉案人员的审讯记录进行人工比较,不仅程序繁琐,而且在耗费警力和时间资源的同时也可能出现难以避免的人为误判。
技术实现要素:
针对上述需求,本发明的目的是提供一种问询处理方法及系统,实现在线协同处理问询中的信息对比,以此提升办公、办案效率和准确度。
本发明采用的技术方案如下:
一种问询处理方法,包括:
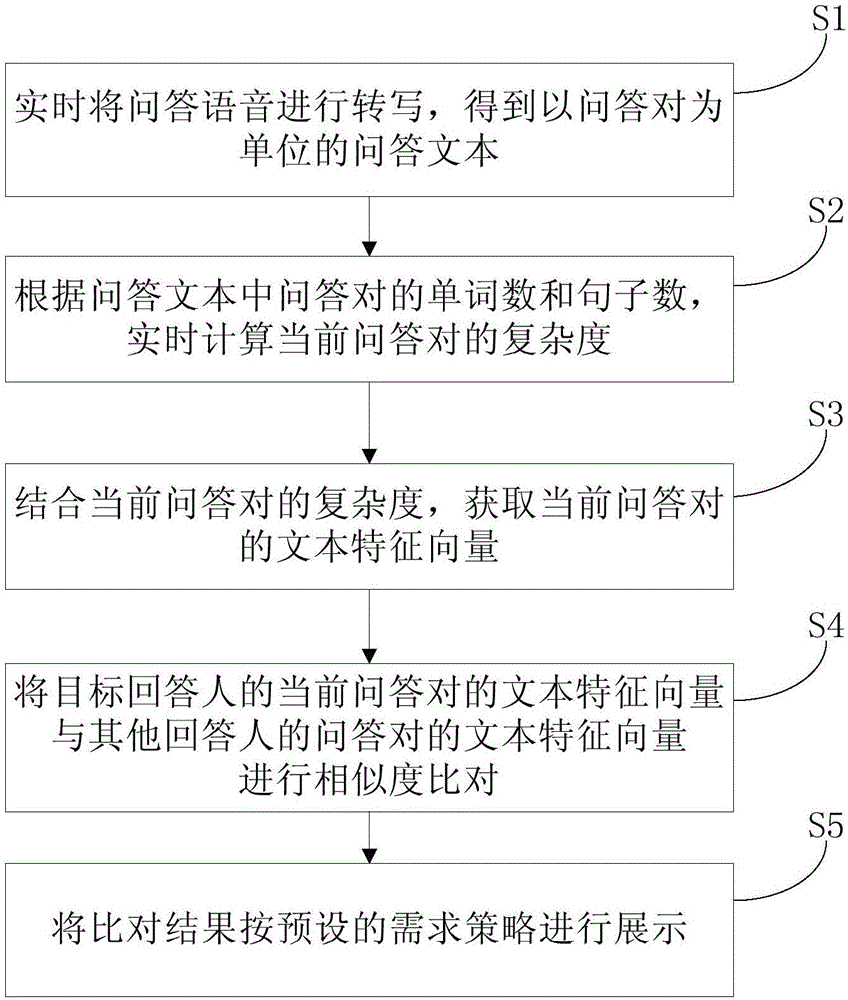
在对目标回答人进行问询时,实时将问答语音进行转写,得到以问答对为单位的问答文本;
根据所述问答文本中问答对的单词数和句子数,实时计算当前问答对的复杂度;
结合当前问答对的复杂度,获取当前问答对的文本特征向量;
将目标回答人的当前问答对的文本特征向量与其他回答人的问答对的文本特征向量进行相似度比对;
将比对结果按预设的需求策略进行展示。
可选地,所述根据所述问答文本中问答对的单词数和句子数,实时计算当前问答对的复杂度包括:
根据所述问答文本中每个问答对的单词数,计算与历史问答对的单词复杂程度相关的当前单词复杂度;
根据所述问答文本中每个问答对的句子数,计算与历史问答对的句子复杂程度相关的当前句子复杂度;
根据所述当前单词复杂度以及所述当前句子复杂度,实时计算当前问答对的复杂度。
可选地,
所述根据所述问答文本中每个问答对的单词数,计算与历史问答对的单词复杂程度相关的当前单词复杂度包括:
计算每个问答对中的回答单词数以及问题单词数的比值,得到每个问答对的单词数复杂度;
计算本次问询中从历史问答对到当前问答对的所有单词数复杂度的加权和,得到所述当前单词复杂度;
所述根据所述问答文本中每个问答对的句子数,计算与历史问答对的句子复杂程度相关的当前句子复杂度包括:
计算每个问答对中的回答句子数以及问题句子数的比值,得到每个问答对的句子数复杂度;
计算本次问询中从历史问答对到当前问答对的所有句子数复杂度的加权和,得到所述当前句子复杂度。
可选地,所述根据所述当前单词复杂度以及所述当前句子复杂度,实时计算当前问答对的复杂度包括:
将所述当前单词复杂度与所述当前句子复杂度进行相加,得到当前问答对的词句复杂度;
计算所述词句复杂度与预设的复杂度上限值的比值,得到当前问答对的复杂度。
可选地,所述结合当前问答对的复杂度,获取当前问答对的文本特征向量包括:
通过实时在线特征提取算法获取或通过多种特征提取算法分别获取当前问答对中的问题语句和回答语句的特征向量;其中,所述多种特征提取算法包括实时在线特征提取算法;
计算问题语句及回答语句的特征向量均值;
基于当前问答对的复杂度设置权重系数,并将问题语句特征向量均值及回答语句特征向量均值进行加权并求和,得到与所用的特征提取算法相对应的单个或多个基础特征向量;
将实时在线特征提取算法得到的单个基础特征向量确定为当前问答对的文本特征向量,或者将基于多种特征提取算法得到的多个基础特征向量进行融合,再将融合结果确定为当前问答对的文本特征向量。
可选地,
所述多种特征提取算法还包括业务知识库特征提取模型;
所述方法还包括:
根据所述问答文本中问答对的关键词,实时计算当前问答对的知识库依赖度;其中,所述关键词为问答对中与预设的业务知识库中的业务词汇相匹配的单词;
所述基于多种特征提取算法得到的多个基础特征向量进行融合包括:
将所述知识库依赖度作为权重系数,对与业务知识库相关的基础特征向量进行加权;
将加权后的与业务知识库相关的基础特征向量与其他基础特征向量进行融合。
可选地,所述根据所述问答文本中问答对的关键词,实时计算当前问答对的知识库依赖度包括:
计算每个问答对的关键词数与该问答对中单词总数的比值,得到每个问答对的关键词覆盖率;
计算本次问询中从历史问答对到当前问答对的关键词覆盖率的加权和,得到当前问答对的知识库依赖度。
可选地,所述将比对结果按预设的需求策略进行展示包括:
将该目标回答人的当前问答对与其他回答人的所有问答对的比对结果进行排序,从中选取并展示符合预设标准的其他回答人的问答对;和/或
直接展示该目标回答人的当前问答对与其他回答人的基于相同或相似问题的问答对的相似度比对结果。
可选地,所述实时将问答语音进行转写,得到以问答对为单位的问答文本包括:
采集本次问询中的语音数据;
根据声学特征,划分不同说话人的语音数据边界,其中,所述不同说话人包括目标回答人以及提问人;
基于不同说话人之间的语音切换或静音时长,将语音数据标记为针对不同说话人的语音段,其中,一个所述语音段表征一个说话人一次完整的语音数据;
按照各所述语音段的时间顺序或按照对所述语音段的语义分析结果,生成基于一次问答的问答对语音数据;
实时将所述问答对语音数据转写成对应的文本数据;
将问答对的文本数据汇总成本次问询的问答文本。
一种问询处理系统,包括:
问答文本生成模块,用于在对目标回答人进行问询时,实时将问答语音进行转写,得到以问答对为单位的问答文本;
复杂度计算模块,用于根据所述问答文本中问答对的单词数和句子数,实时计算当前问答对的复杂度;
特征向量获取模块,用于结合当前问答对的复杂度,获取当前问答对的文本特征向量;
比对模块,用于将目标回答人的当前问答对的文本特征向量与其他回答人的问答对的文本特征向量进行相似度比对;
展示模块,用于将比对结果按预设的需求策略进行展示。
可选地,所述复杂度计算模块具体包括:
当前单词复杂度计算单元,用于根据所述问答文本中每个问答对的单词数,计算与历史问答对的单词复杂程度相关的当前单词复杂度;
当前句子复杂度计算单元,用于根据所述问答文本中每个问答对的句子数,计算与历史问答对的句子复杂程度相关的当前句子复杂度;
问答对复杂度计算单元,用于根据所述当前单词复杂度以及所述当前句子复杂度,实时计算当前问答对的复杂度。
可选地,
所述当前单词复杂度计算单元具体包括:
第一计算子单元,用于计算每个问答对中的回答单词数以及问题单词数的比值,得到每个问答对的单词数复杂度;
第二计算子单元,用于计算本次问询中从历史问答对到当前问答对的所有单词数复杂度的加权和,得到所述当前单词复杂度;
所述当前句子复杂度计算单元具体包括:
第三计算子单元,用于计算每个问答对中的回答句子数以及问题句子数的比值,得到每个问答对的句子数复杂度;
第四计算子单元,用于计算本次问询中从历史问答对到当前问答对的所有句子数复杂度的加权和,得到所述当前句子复杂度。
可选地,所述问答对复杂度计算单元具体包括:
词句复杂度计算子单元,用于将所述当前单词复杂度与所述当前句子复杂度进行相加,得到当前问答对的词句复杂度;
当前问答对复杂度计算子单元,用于计算所述词句复杂度与预设的复杂度上限值的比值,得到当前问答对的复杂度。
可选地,所述特征向量获取模块具体包括:
特征获取单元,用于通过实时在线特征提取算法获取或通过多种特征提取算法分别获取当前问答对中的问题语句和回答语句的特征向量;其中,所述多种特征提取算法包括实时在线特征提取算法;
特征向量均值计算单元,用于计算问题语句及回答语句的特征向量均值;
基础特征向量获取单元,用于基于当前问答对的复杂度设置权重系数,并将问题语句特征向量均值及回答语句特征向量均值进行加权并求和,得到与所用的特征提取算法相对应的单个或多个基础特征向量;
文本特征向量确定单元,用于将实时在线特征提取算法得到的单个基础特征向量确定为当前问答对的文本特征向量,或者将基于多种特征提取算法得到的多个基础特征向量进行融合,再将融合结果确定为当前问答对的文本特征向量。
可选地,
所述多种特征提取算法还包括业务知识库特征提取模型;
所述系统还包括:
知识库依赖度计算模块,用于根据所述问答文本中问答对的关键词,实时计算当前问答对的知识库依赖度;其中,所述关键词为问答对中与预设的业务知识库中的业务词汇相匹配的单词;
所述文本特征向量确定单元具体包括:
加权子单元,用于将所述知识库依赖度作为权重系数,对与业务知识库相关的基础特征向量进行加权;
融合子单元,用于将加权后的与业务知识库相关的基础特征向量与其他基础特征向量进行融合。
可选地,所述知识库依赖度计算模块具体包括:
关键词覆盖率计算单元,用于计算每个问答对的关键词数与该问答对中单词总数的比值,得到每个问答对的关键词覆盖率;
知识库依赖度计算单元,用于计算本次问询中从历史问答对到当前问答对的关键词覆盖率的加权和,得到当前问答对的知识库依赖度。
可选地,所述展示模块具体包括:
问答对展示单元,用于将该目标回答人的当前问答对与其他回答人的所有问答对的比对结果进行排序,从中选取并展示符合预设标准的其他回答人的问答对;和/或
相似度展示单元,用于直接展示该目标回答人的当前问答对与其他回答人的基于相同或相似问题的问答对的相似度比对结果。
可选地,所述问答文本生成模块具体包括:
语音采集单元,用于采集本次问询中的语音数据;
说话人识别单元,用于根据声学特征,划分不同说话人的语音数据边界,其中,所述不同说话人包括目标回答人以及提问人;
语音段生成单元,用于基于不同说话人之间的语音切换或静音时长,将语音数据标记为针对不同说话人的语音段,其中,一个所述语音段表征一个说话人一次完整的语音数据;
问答对构建单元,用于按照各所述语音段的时间顺序或按照对所述语音段的语义分析结果,生成基于一次问答的问答对语音数据;
转写单元,用于实时将所述问答对语音数据转写成对应的文本数据;
问答文本生成单元,用于将问答对的文本数据汇总成本次问询的问答文本。
本发明通过提出一种在线协同的问询处理方案,借由语音识别技术自动将问询语音转录为以问答对为单位的问答文本,并通过计算问答对复杂度的方式,生成针对目标回答人当前问答对的特征向量,用来与其他人员的问答情况进行相似度的在线比对,最后将按需展示比对结果,从而能够实现在线协同处理,提升办案、办公的效率;而且由于采用了成熟的语音处理技术,本发明不仅能大幅节省人力和时间成本,还能够确保处理的准确度,降低误判率。
附图说明
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步描述,其中:
图1为本发明提供的问询处理方法的实施例的流程图;
图2为本发明提供的关于步骤s1的具体实施例的流程图;
图3为本发明提供的关于步骤s2的具体实施例的流程图;
图4为本发明提供的关于步骤s3的具体实施例的流程图;
图5为本发明提供的计算知识库依赖度的实施例的流程图;
图6为本发明提供的问询处理系统的实施例的方框图。
具体实施方式
下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
本发明是通过提出一种在线协同的问询处理方案,借由语音识别技术自动将问询语音转录为以问答对为单位的问答文本,并通过计算问答对复杂度的方式,生成针对目标回答人当前问答对的特征向量,用来与其他人员的问答情况进行相似度的在线比对,最后将按需展示比对结果,从而能够实现在线协同处理,提升办案、办公的效率。据此可知,本发明的应用领域并不限于前文举例的警务应用,只要是类似的问询场景且存在与前文所提需求相符的其他需求,本领域技术人员均可以采用本发明的技术方案予以实时。但是为了实施方式的说明之便同时也为了使本领域技术人员能够直观理解本发明的构思、方案及效果,本发明于此借警务应用对实施过程进行详细而具体的展开。因此,在对本发明的实施方式进行具体说明之前,首先对本发明各实施例及优选方案中涉及或可能涉及的相关概念或背景进行如下解释:
涉及多人案件的审理场景之一:
盗窃团伙成员有p1个人,安排p2位警员同时且分开审理此p1个人,并针对每个嫌疑人建立一份包含问答对序列及相关信息的笔录。
涉及多人案件的审理场景之二:
涉案人员p1个人,由于提审或抓捕到案时间不同,p2位警员则可能分时段审理此p1个人,并针对每个涉案人员建立一份包含问答对序列及相关信息的笔录。
问答对:在警务审讯时,一个问答对是指由办案人员的一次提问和一位涉案人员的回答所组成;其中,提问和回答均可以是一句或者多句话。例如,团伙盗窃案审理时的问答对记录样例:
问答对一:提问1句、回答1句;
问:你是否实施过盗窃?
答:没实施,但参与过。
问答对二:提问1句、回答多句;
问:你把经过交代清楚?
答:大概在xxxx年xx月xx日凌晨xx点钟的时候,我和a从xxx出来沿着xxx高架走。从一个出口下来就进了一个村子,因为我要去村里的公厕方便。a发现在公厕旁停着个大卡车。我从厕所出来后,a提议我把风,他拿着随身带的一个小刀去撬车门。车门弄开以后,他在里面翻东西,从车里找到了几百块钱。他拿了钱之后,分了我一百块,a就和我分头离开了。
问答对三:提问多句、回答1句;
问:xxx,现向你告知,你因涉嫌盗窃,经xxx公安分局批准,决定对你刑事拘留三日。期限自xxxx年xx月xx日至xxxx年xx月xx日,羁押地点为xxx看守所。你是否明白?
答:明白了。
问答对序列:指由审理时,办案人员和当前涉案人员进行的多轮问答产生的问答对序列。
历史问答对:在一次问询过程中,处于当前问答对之前的问答对统称为历史问答对。
基于上述,本发明提供了一种问询处理方法的实施例,如图1所示,该方法可以包括如下步骤:
步骤s1、实时将问答语音进行转写,得到以问答对为单位的问答文本;
这里所称目标回答人即可以是指前述样例中的一位涉案人员,在对该目标回答人进行问询时,通过现已成熟且智能的语音处理技术,实现在审讯过程中办案人员与涉案人员的问答语音采集、识别处理,并以此形成基于该目标回答人的本次问询的问答文本过程,可借鉴多种现有的语音处理解决方案,本发明在下文中提供了一种实施方式以供参考,此处不予赘述。但需说明的是,本领域技术人员可知,在进行语音转写时还可以根据场景所需获取并存储与问答对相关的信息,例如在审讯数据库中存储本次审讯的原始问答语音数据,在前述问答文本中则可以存储问答参与人、审讯时间、案由名目以及各问答对用时等基本信息,对此本发明不做限定。
步骤s2、根据问答文本中问答对的单词数和句子数,实时计算当前问答对的复杂度;
根据不同的需求,对问答对的特征向量的调控方向可以有不同的角度,例如以犯罪心理分析为立足点,则可以从问答过程中的语气、语速、韵律、停顿时间甚至说话时的呼吸节奏等方面侧重考察。但在本发明提出的实施例中,结合了相关适用场景的应用经验以及对本实施例处理效果的期待,本发明着重考虑问答对的复杂程度对后续比对结果的影响。并且,问答对话的复杂程度也可以从多种维度反映,例如语义内容、关键信息量以及表述逻辑性等,通过大量现实场景的反馈,发现问答对中的单词数和句子数与前述各复杂程度的维度强相关,也即是表达出大量的语义内容或者大量关键信息或者逻辑复杂的表述,几乎均是在问答过程中包含了大量的单词数和句子数;据此,本发明根据实际经验,选择以问答对的单词数和句子数为侧重点,考察问答对的复杂度,因而本领域技术人员可以理解的是,在实施本步骤时,还会具体包括分词、标注以及过滤停用词等常规的对语音识别文本的预处理操作。
此外还需说明的是,由于现有的语音处理技术足以实时处理语音数据,因而在本步骤中,本发明所提出的计算复杂度的对象是“当前问答对”,也就是对本次问询中刚刚发生的问答过程进行复杂度的确定;再者,本步骤中提及计算复杂度是根据问答文本中问答对的单词数和句子数,在实际操作中,既可以是指当前问答对的单词数和句子数,也可以是指整个问答对序列(从历史到当前)的单词数和句子数。所以,由单词数和句子数计算复杂度的过程可以有多种方式,例如将单词数和句子数二者求和;或者,将所有句子按各自包含的单词数进行排序,按预定单词数标准选出符合标准的句子数;再或者,根据问答文本中每个问答对的单词数,计算与历史问答对的单词复杂程度相关的当前单词复杂度,同理地,根据问答文本中每个问答对的句子数,计算与历史问答对的句子复杂程度相关的当前句子复杂度,再根据该当前单词复杂度以及当前句子复杂度,实时计算当前问答对的复杂度。本发明在下文实施例中给出了针对与历史问答对相关的复杂度计算方法,此处不予赘述。
步骤s3、结合当前问答对的复杂度,获取当前问答对的文本特征向量;
周知地,在语音处理技术领域内进行文本比对操作时,常用且有效的方式即是对文本特征向量进行特证距离的比较,因而在进行后续比对前,由本步骤提出获取当前问答对的文本特征向量,而提取方式则有多种现有技术可以选取,例如在线实时提取或者通过预先训练的特征提取模型等进行特征向量的提取,本发明在下文中提供了一种优选的提取特征向量的方式,此处不予赘述;但需指出的是,本步骤的重点在于强调该当前问答对的文本特征向量是与前述步骤中计算得到的当前问答对的复杂度相关的,也即是如前文阐明,本发明侧重由问答对复杂度作为特征表达的调控方向,因而这里所称相关,可以是指由当前问答对的复杂度作为在计算当前问答对的文本特征向量表达中的权重因素,具体将在下文给出实施参考。
步骤s4、将目标回答人的当前问答对与其他回答人的问答对进行相似度比对;
这里所称其他回答人,是指区别于本次问询中所述目标回答人的其他被问询对象。由上述步骤的说明,比对过程显而易见是指问答对之间通过文本特征向量的相似度进行比对、匹配。具体在实际操作中,可以是基于目标回答人的当前问答对的文本特征向量,循环遍历与本次问询相关的其他回答人(一个或多个或全部,但不包括目标回答人)的问答文本中所有或特定的问答对文本特征向量进行动态的相似度计算。这里需指出三点,其一、由于基于文本特征向量的计算是显而易见的,因此,在进行比对前一般还需对已经储存的其他回答人的问答文本(包含其他回答人的问答对特征序列)中的问答对进行特征向量提取操作,当然,也可以考虑另为每个回答人建立其个人的问答对特征库,而无需在每次进行动态比对时重复提取其他回答人的问答对文本特征向量,即直接将目标回答人的当前问答对的文本特征向量与其他回答人的问答对特征库中的文本特征向量进行比对。这里所称问答对特征库可以与前述问答文本集成或建立关联,使得问答文本成为追加了所有与本次问询相关的问答对数据的信息记录载体(可以将该问答文本视为一份信息完整的综合笔录);其二、比对过程中,既可以进行一一比对,也可以基于与当前问答对强相关的一个或多个问答对进行针对性比对,例如按照预设的审讯提问模板,将次序相对应的问答对进行针对性比对;其三、由于现有语音处理技术及网络通讯技术的成熟化,使得比对过程足以适用在分时段问询或者同步问询。举例来说,由于嫌疑人到案时间不同,对嫌疑人a和b的审讯时序是a先b后,则在审讯b的过程中可以将b的当前问答对与已经在先存储的a的问答对序列进行一一比对或针对性比对。如果a和b采用同步问询,则可以在审讯a和b的过程中,进行高效的在线交叉比对,即在审讯a的过程中可以将a的当前问答对与b的历史问答对或当前问答对进行实时在线比对,同理,b的当前问答对也可以与a的历史或当前问答对进行比对;再者,在交叉比对过程中如果出现因为进度差异或问题顺序变动,导致一次比对未能得到预期的比对结果时,还可以通过提问人之间的人为配合或者设置延时、定时等技术手段,重复前述比对过程,以此更新比对结果。具体在实际应用中的比对方式以及所采用的相似度计算方法等,皆可按问询所需进行调整和选取,本发明对此不作限定。
步骤s5、将比对结果按预设的需求策略进行展示。
最后,是将前述步骤中的比对结果向相关人员进行展示。这里所称的按预设的需求策略,是表明针对不同问询场景或者不同的提问人,可能存在对比对结果有不同的期待,因而展示结果的方式可有但不限于如下策略:
将该目标回答人的当前问答对与其他回答人的所有问答对的比对结果进行排序,从中选取并展示符合预设标准的其他回答人的问答对。该策略中强调的是排序后的选取以及直接展示符合标准的问答对内容(可以是问答对原始语音也可以问答对的语音识别文本),因此不对排序采用倒序或正序限定;而此处所述预设标准则可以是指预设的不同的相似度门限,具体标准取决于不同的问询需求;而展示符合标准的问答对则是为了直接使相关人员了解到问答对的实际问题和回答的语音(或文本)内容,以便提升办案、办公效率。
可以与前述同时或者单独实现的另一个展示策略:直接展示该目标回答人的当前问答对与其他回答人的基于相同或相似问题的问答对的相似度比对结果。该策略中强调的是,利用现有的语音处理技术可以实时且准确获得语义内容,因此可以将当前问答对中的所提问题与其他回答人的问答对的所提问题进行先行“定位”,即先判断问题之间的相似对锁定目标问题,再综合判断整个问答对的相似度,当然在其他策略中,也可以采用问题相关而非相似进行问题的锁定,对此本发明不做限定;而最终展示的结果可以简化为基于该相同或相似问题的相似度情况,例如二者的匹配得分,这样,相关人员可以通过匹配得分迅速获知比对结果,而具体的问答对内容信息则可以在后期进行调取分析,从而节省本次问询的时间。
可见,无论采取上述何种策略进行展示皆各有所长,因而可以根据实际所需选择其一或多种进行结果展示。并且还可以基于该实施方式进行拓展,例如在本次问询结束后,自动将包含问答对信息及比对结果的问答文本生成结构化文档作为归档备案。
本发明通过上述实施例提出了一种在线协同的问询处理方案,借由语音识别技术自动将问询语音转录为以问答对为单位的问答文本,并通过计算问答对复杂度的方式,生成针对目标回答人当前问答对的特征向量,用来与其他人员的问答情况进行相似度的在线比对,最后将按需展示比对结果,从而能够实现在线协同处理,提升办案、办公的效率;而且由于采用了成熟的语音处理技术,本发明不仅能大幅节省人力和时间成本,还能够确保处理的准确度,降低误判率。
关于步骤s1,本发明提供了一种优选的通过语音转写得到以问答对为单位的问答文本的实施示例,如图2所示,具体可以包括如下步骤:
步骤s11、采集本次问询中的语音数据;
步骤s12、根据声学特征,划分不同说话人的语音数据边界;
具体可以采用说话人分离方法识别出不同说话人的语音数据边界,其中,不同说话人可以是指目标回答人以及提问人。
步骤s13、基于不同说话人之间的语音切换或静音时长,将语音数据标记为针对不同说话人的语音段;
这里需说明的是,在本实施例中采用以语音切换及静音时长作为划定语音段的条件,是因为后续构建问答对的步骤决定了诸如计算复杂度以及相似度比对等操作的准确性。这里所称语音切换是指语音来源在提问人和目标回答人之间发生变换,当存在不同说话人语音切换时即表明切换前的说话人的语音结束,这其中能够包括该人说话结束或者被打断等情况;静音时长是指在一个说话人的语音结束后,出现静音间隔且超过一定时长的情况,例如当问询时提问人在提出问题后,回答人沉默不作答且沉默时长超过了一个预设的时间门限。此种情况,提问人通常会再提出相同或不同的问题,从说话人辨别角度由于两次连续发问皆出自同一声源,可能会被认为同一个说话人的本次语音没有结束,使得后续问答对的构建操作出现划定错误,但实际上前一问答对可能已经结束(前一问答对中的回答内容为空),因此本发明以此方式能够提升问答对的构建准确性。于此,将上述两种情形之一作为确定语音段的依据,即是将切换前的语音数据或者超过静音时长之前的语音数据,标记为一个用来表征一个说话人一次完整的语音数据的语音段。需指出的是,在本步骤中该两项条件以“或”关系表示,仅为了说明二者满足其一即可标记出语音段,并不代表在完整的问询过程中只能以二者之一进行语音段标记。
步骤s14、按照各语音段的时间顺序或按照对语音段的语义分析结果,生成基于一次问答的问答对语音数据;
由语音段的先后顺序可以确定组成问答对的问和答,举例来说,按时序有a0、q1和a1三个语音段,由于从时间角度而言,回答通常位于提问之后,如果a0表示前一时刻回答人的语音段,q1则表示当前时刻提问人的语音段,a1则表示q1之后的回答人的语音段,因此可以将q1和a1划定为一个问答对;或者,对语音段进行语义分析,根据语义结果查找与问题相关的回答,据此将二者构建为一个问答对,该过程的具体实现已有多种现有技术支持,本发明在此不作赘述。
步骤s15、实时将问答对语音数据转写成对应的文本数据;
上述构建的仍是基于语音数据的问答对,因此在本步骤中将问答对语音数据进行转写得到相应于问答对的文本数据,具体的转写方法已有多种现有技术支持,本发明在此不作赘述。
步骤s16、将问答对的文本数据汇总成本次问询的问答文本。也即是表示,本次问询的问答文本是由该目标回答人的多个问答对所组成。
关于前述步骤s2,本发明提供了一种与历史问答对相关的复杂度计算方法的实施参考,如图3所示,该计算方法可以包括如下步骤:
步骤s21、计算每个问答对中的回答单词数以及问题单词数的比值,得到每个问答对的单词数复杂度;
步骤s22、计算本次问询中从历史问答对到当前问答对的所有单词数复杂度的加权和,得到当前单词复杂度;
步骤s23、计算每个问答对中的回答句子数以及问题句子数的比值,得到每个问答对的句子数复杂度;
步骤s24、计算本次问询中从历史问答对到当前问答对的所有句子数复杂度的加权和,得到当前句子复杂度;
步骤s25、将当前单词复杂度与当前句子复杂度进行相加,得到当前问答对的词句复杂度;
步骤s26、计算词句复杂度与预设的复杂度上限值的比值,得到当前问答对的复杂度。
该实施方式可以举例如下:对一个问答对的文本进行分词及过滤停用词等预处理后,得到问题单词个数为qw,问题句子数为qc,同理地,得到回答单词个数为aw,回答句子数为ac。因而前述单词数复杂度v=回答单词数/问题单词数,即v=aw/qw,v的理论取值范围(0,∞),但可结合实际应用场景为其预设一个经验值,也即是对于该场景下的一个问答对的单词复杂度上限值d1。前述句子数复杂度w=回答句子数/问题句子数,即w=ac/qc,w的理论取值范围(0,∞),但同样可结合实际应用场景为其预设一个经验值,也即是对于该场景下的一个问答对的句子复杂度上限值d2。
在本实施例中,考虑到当前问答对的复杂程度与本次问询的历史问答对相关,也即是当前问答对的复杂度可能会受到之前历史问答对的复杂度的影响,因此提出分别计算本次问询中从历史问答对到当前问答对的所有单词数复杂度/句子数复杂度的各自的加权和,得到当前单词复杂度
接着,由于为单词复杂度和句子复杂度分别设计了经验上限值,因而在计算当前问答对的复杂度sc时可采用如下公式:
公式中的分母部分即是表示按照同样的权重系数将单词和句子的复杂度上限值作加权和处理,便于求得本次问询中的当前单词/句子复杂度与经验上限的占比,而该占比sc即为本实施例所述当前问答对的复杂度。对于上述计算方式还可以补充说明的是:一方面,为了数学表达和后续计算的便利性,还可以利用诸如tanh曲线特性将上述sc做归一化处理,对此本发明不作限定;另一方面,图3所示的计算步骤实际分为两部分,即一部分是综合了问答对序列的复杂度后求得当前单词/句子复杂度,另一部分是利用当前单词/句子复杂度和预设的复杂度上限值计算最终的当前问答对的复杂度,但此两部分计算方式并非仅有上述算法,基于单词数和句子数的计算方法实则可根据需求进行选择,例如在计算当前单词/句子复杂度时可以包括求取均值,在计算sc时可以分别计算当前单词复杂度与单词上限比值以及当前句子复杂度与句子上限比值,而后再将二者融合。采用不同的计算方式可能得到不同的复杂度数值,这取决于场景的实际所需,上述方式仅为抛砖引玉,本领域技术人员可在上述实施参考基础上进行拓展。
关于前述步骤s3需作具体说明的是,其一、因为语句相较孤立的单词而言,能够较为清晰地表达出语义。因此,在对当前问答对进行文本特征向量提取时,优选以当前问答对中的问题语句和回答语句为单元,进行文本特征向量提取。其二、毋庸置疑的是,本次问询内容与本次问询的事由强相关,因此本次问询的内容实质是最为核心的关键数据,但是由于本次问询的数据样本不满足模型训练条件,因此优选考虑应至少采用一种实时在线特征提取算法对当前问答对进行特征提取作业,也即是无论采取一种或多种提取算法,均包含实时在线特征提取算法,实时提取方法可以但不限于通过计算每一条语句的所有单词的词向量的均值,获得每个语句的文本特征向量。
基于前文所述并且为了提升特征提取的准确度,本发明提供了一种针对步骤s3的获取文本特征向量的具体方案,如图4所示,可以包括如下步骤:
步骤s31、通过多种特征提取算法分别获取当前问答对中的问题语句和回答语句的特征向量;
在本实施例中本发明提出利用多种算法分别提取当前问答对中各语句的特征向量,其中多种特征提取算法不仅包括了前述实时在线特征提取算法,还可以包括业务知识库特征提取模型、离线大数据特征提取模型及其他特征提取工具,本发明对于特征提取工具的总数并没有限制,在本实施例中可以是两种、三种甚至四种及以上,但是在实际操作中还需要考虑提取的特征数量与运算数据量的平衡,因而优选可采用包括实时在线特征提取算法、业务知识库特征提取模型以及离线大数据特征提取模型,此三种特征提取工具。其中,由实时在线特征提取算法提取到的问题/回答语句的特征向量可表示为vecrt;所述业务知识库特征提取模型可以是前期根据各个业务知识库(以警务为例,可以是诸如赌博案件库、盗窃案件库、假发票案件库等)的数据样本训练得到,由其提取到的问题/回答语句的特征向量可表示为veckb;所述离线大数据特征提取模型可采用以语句为单位,基于字、词、词性等信息的深度神经网络模型,由其提取到的问题/回答语句的特征向量可表示为vecom。有关该离线大数据特征提取模型具体可以如下:
以句子为单位,融合字、词、词性等信息,通过transformer的encoder端网络+双向lstm网络+attentionlayer的深度网络模型,再经过lda案件主题分类得到离线训练的大数据模型,提取每句话的文本特征向量;该模型的结构可以主要由三部分组成:
第一部分为嵌入层(输入层),其结构基于字向量的cnn网络+预训练的词向量+词汇位置编码+词性编码等,其功能是丰富句子的词汇向量化表示。其实现一方面为了消除unk词汇(非词典词汇)对语义表达的影响,利用基于字向量的cnn网络结构对unk词汇进行向量化表示(由于字集合是确定的有限集合,而词汇是一个开放的集合,任何一个unk词汇所包含的字都在字集合内,所以可以通过字向量消除unk词汇对语义表达的影响);另一方面为了加强对句子中词汇语义的表征,额外地增加基于词汇的位置向量以及词性信息对词汇进行表征。
第二个部分为句子向量表示层(隐藏层),其结构主要为transformer(机器翻译中一种深度学习网络结构)的encoder端网络+双向lstm网络+attentionlayer(多组attention,加强语义),通过此隐藏层网络结构对句子进行深层次的语义向量化表示。
第三个部分为lda案件主题分类模型的应用(输出层),主要将生成的句子向量在实际案件数据中进行应用。lda模型是基于现有案件库中的案件大类,进行主题内容建模,生成案件库的主题模型。对于第二个部分生成的语义向量,进行主题内容的空间仿射,生成每个句子的主题特征向量(即每个句子的特征向量),该部分使得不同案件类的问题所生成的语义向量具有空间的良好分辨性。
关于上述模型的训练,可以获得所有一般审讯场景(包括团伙案件、非团伙案件等)问答对数据作为数据来源,再通过交叉熵损失函数训练准则,分别得到审讯问、答的向量,利用全连接网络判断问答是否匹配。关于该模型的训练与结构组成本发明不限于上述,但可以说明的是前述业务知识库特征提取模型结构可以与该离线大数据特征提取模型采用近似结构。
步骤s32、计算问题语句及回答语句的特征向量均值;
为便于整体上把握特征向量的表达以及后续计算过程,对上述提取到的问题/回答语句的特征向量进行均值计算,需指出如果仅采用一种特征提取工具,也即是由实时在线特征提取算法提取到的特征向量,仅需对该算法对应的特征向量求取均值;接续上文,对由前述三种特征提取工具获得的特征向量均值可以分别表示如下:
1)基于实时在线特征提取算法:
2)基于业务知识库特征提取模型:
3)基于离线大数据特征提取模型:
步骤s33、基于当前问答对的复杂度设置权重系数,并将问题语句特征向量均值及回答语句特征向量均值进行加权并求和,得到与所用的特征提取算法相对应的多个基础特征向量;
本步骤结合了前述步骤得到的当前问答对的复杂度sc,分别求取基于不同特征提取工具的基础特征向量,此处所称“基础”是相对后续步骤中完整的文本特征向量的区分表述;还需指出,本实施例为了突显目标回答人的回答内容在询问过程中的主要作用,对于特征向量均值的加权方式可以是将复杂度sc赋予回答语句的特征向量均值,而将(1-sc)赋予问题语句的特征向量均值,但在实际应用中并不限于此加权方式。接续上文,对基于前述三种特征提取工具获得的基础特征向量可以分别表示如下:
1)实时在线特征提取算法:
其中用vecamp1表示实时基础特征向量。
2)业务知识库特征提取模型:
其中用vecamp2表示知识库基础特征向量。
3)离线大数据特征提取模型:
其中用vecamp3表示离线大数据基础特征向量。
步骤s34、将基于多种特征提取算法得到的多个基础特征向量进行融合,再将融合结果确定为当前问答对的文本特征向量。
为了得到完整的文本特征向量表达,本步骤中采用融合上述三个基础特征向量的方式,得到本发明所述当前问答对的文本特征向量:
vecamp=vecamp1+vecamp2+vecamp3
其中用vecamp表示当前问答对的文本特征向量。并且,具体的融合方式既可以采用向量加权拼接(每个基础特征向量维度相同),也可以是向量加权累加求平均等,对此本发明不作限定。
但需说明的是,如果仅采用一种特征提取工具,也即是由实时在线特征提取算法提取特征向量,则当前问答对的文本特征向量可以表达成:
vecamp=vecamp1
由于上述实施例中运用了业务知识库特征提取模型,因此在本发明的另一个较佳实施例中,提出除了计算当前问答对的复杂度,还可以进一步实时计算出当前问答对的知识库依赖度kdd,如此在进行前述基础特征向量融合的过程中,还可以对vecamp2进行基于知识库依赖度的控制。具体而言,可以将所述知识库依赖度kdd作为权重系数,对与业务知识库相关的基础特征向量vecamp2进行加权;之后再将加权后的与业务知识库相关的基础特征向量与其他基础特征向量进行融合,得到本发明所述当前问答对的文本特征向量的另一种表达形式:
vecamp=vecamp1+kdd×vecamp2+vecamp3
关于该较佳实施方式中所述知识库依赖度的计算方法,本发明提供了一种与问答文本中问答对的关键词相关的参考示例,如图5所示
步骤s300、计算每个问答对的关键词数与该问答对中单词总数的比值,得到每个问答对的关键词覆盖率;
其中所称关键词为问答对中与预设的业务知识库中的业务词汇相匹配的单词;具体来说,同样可以先对当前问答对进行分词、过滤停用词等预处理操作,进而得到问答对的单词总数aqw=qw+aw。其中,qw为问题单词个数,aw为回答单词个数,aqw为当前问答对中单词总数。接着,根据已有的业务知识库(以警务为例,可以是诸如赌博案件库、盗窃案件库、假发票案件库等),可以离线生成一个与该业务相关的关键词列表;再将当前问答对中aqw个单词和该关键词列表进行字符串比较,如果字符串相等即记为匹配成功一条,最后统计出所有相匹配的关键词数,本示例中以bw表示。而针对该业务的关键词覆盖率p=bw/aqw,p取值范围是(0,1]。
步骤s301、计算本次问询中从历史问答对到当前问答对的关键词覆盖率的加权和,得到当前问答对的知识库依赖度。
与前文所述计算复杂度同理,本发明将整个问答对序列中所有问答对均考虑在内,得到一个与历史问答对相关的知识库依赖度,并且同样是越靠近当前问答对的历史问答对其对当前问答对的知识库依赖度影响越大,最终得到当前问答对的知识库依赖度表示为
基于上述内容,关于前述步骤s4可以再作补充说明的是,所谓文本特征向量的比对即是将上述获得的目标回答人的vecamp与其他回答人的问答对序列中的各问答对的文本特征向量vec1、vec2、vec3…等进行诸如余弦距离或者欧式距离的计算;特征比对过程非本发明的重点,实施时可借鉴多种现有的比对方案,本发明对此不作赘述。但可以补充的是,后台计算此问答对的基础特征向量时,包括上述离线大数据模型基础特征向量、业务知识库相似度计算基础特征向量、在线实时问答对相似度基础特征向量,把此问答对的基本信息和基础特征向量追加到某个预设的数据库,作为该目标回答人的一个问询综合数据集;最后,还可以据此生成结构化文档,作为问询的笔录卷宗,此卷宗可以包括各个分开问询的笔录、相同/相似问题不同回答人所回答情况表格等。
本发明通过提出一种在线协同的问询处理方案,借由语音识别技术自动将问询语音转录为以问答对为单位的问答文本,并通过计算问答对复杂度的方式,生成针对目标回答人当前问答对的特征向量,用来与其他人员的问答情况进行相似度的在线比对,最后将按需展示比对结果,从而能够实现在线协同处理,提升办案、办公的效率;而且由于采用了成熟的语音处理技术,本发明不仅能大幅节省人力和时间成本,还能够确保处理的准确度,降低误判率。
相应于前述各实施例及其优选方案,本发明还提供了一种问询处理系统的实施参考,如图6所示,该系统可以包括至少一个用于存储相关指令的存储器以及至少一个用于执行下述各模块的处理器:
问答文本生成模块,用于在对目标回答人进行问询时,实时将问答语音进行转写,得到以问答对为单位的问答文本;
复杂度计算模块,用于根据问答文本中问答对的单词数和句子数,实时计算当前问答对的复杂度;
特征向量获取模块,用于结合当前问答对的复杂度,获取当前问答对的文本特征向量;
比对模块,用于将目标回答人的当前问答对与其他回答人的问答对进行相似度比对;
展示模块,用于将比对结果按预设的需求策略进行展示。
可选地,复杂度计算模块具体包括:
当前单词复杂度计算单元,用于根据问答文本中每个问答对的单词数,计算与历史问答对的单词复杂程度相关的当前单词复杂度;
当前句子复杂度计算单元,用于根据问答文本中每个问答对的句子数,计算与历史问答对的句子复杂程度相关的当前句子复杂度;
问答对复杂度计算单元,用于根据当前单词复杂度以及当前句子复杂度,实时计算当前问答对的复杂度。
可选地,
当前单词复杂度计算单元具体包括:
第一计算子单元,用于计算每个问答对中的回答单词数以及问题单词数的比值,得到每个问答对的单词数复杂度;
第二计算子单元,用于计算本次问询中从历史问答对到当前问答对的所有单词数复杂度的加权和,得到当前单词复杂度;
当前句子复杂度计算单元具体包括:
第三计算子单元,用于计算每个问答对中的回答句子数以及问题句子数的比值,得到每个问答对的句子数复杂度;
第四计算子单元,用于计算本次问询中从历史问答对到当前问答对的所有句子数复杂度的加权和,得到当前句子复杂度。
可选地,问答对复杂度计算单元具体包括:
词句复杂度计算子单元,用于将当前单词复杂度与当前句子复杂度进行相加,得到当前问答对的词句复杂度;
当前问答对复杂度计算子单元,用于计算词句复杂度与预设的复杂度上限值的比值,得到当前问答对的复杂度。
可选地,特征向量获取模块具体包括:
特征获取单元,用于通过实时在线特征提取算法获取或通过多种特征提取算法分别获取当前问答对中的问题语句和回答语句的特征向量;其中,多种特征提取算法包括实时在线特征提取算法;
特征向量均值计算单元,用于计算问题语句及回答语句的特征向量均值;
基础特征向量获取单元,用于基于当前问答对的复杂度设置权重系数,并将问题语句特征向量均值及回答语句特征向量均值进行加权并求和,得到与所用的特征提取算法相对应的单个或多个基础特征向量;
文本特征向量确定单元,用于将实时在线特征提取算法得到的单个基础特征向量确定为当前问答对的文本特征向量,或者将基于多种特征提取算法得到的多个基础特征向量进行融合,再将融合结果确定为当前问答对的文本特征向量。
可选地,
多种特征提取算法还包括业务知识库特征提取模型;
系统还包括:
知识库依赖度计算模块,用于根据问答文本中问答对的关键词,实时计算当前问答对的知识库依赖度;其中,关键词为问答对中与预设的业务知识库中的业务词汇相匹配的单词;
文本特征向量确定单元具体包括:
加权子单元,用于将知识库依赖度作为权重系数,对与业务知识库相关的基础特征向量进行加权;
融合子单元,用于将加权后的与业务知识库相关的基础特征向量与其他基础特征向量进行融合。
可选地,知识库依赖度计算模块具体包括:
关键词覆盖率计算单元,用于计算每个问答对的关键词数与该问答对中单词总数的比值,得到每个问答对的关键词覆盖率;
知识库依赖度计算单元,用于计算本次问询中从历史问答对到当前问答对的关键词覆盖率的加权和,得到当前问答对的知识库依赖度。
可选地,展示模块具体包括:
问答对展示单元,用于将该目标回答人的当前问答对与其他回答人的所有问答对的比对结果进行排序,从中选取并展示符合预设标准的其他回答人的问答对;和/或
相似度展示单元,用于直接展示该目标回答人的当前问答对与其他回答人的基于相同或相似问题的问答对的相似度比对结果。
可选地,问答文本生成模块具体包括:
语音采集单元,用于采集本次问询中的语音数据;
说话人识别单元,用于根据声学特征,划分不同说话人的语音数据边界,其中,不同说话人包括目标回答人以及提问人;
语音段生成单元,用于基于不同说话人之间的语音切换或静音时长,将语音数据标记为针对不同说话人的语音段,其中,一个语音段表征一个说话人一次完整的语音数据;
问答对构建单元,用于按照各语音段的时间顺序或按照对语音段的语义分析结果,生成基于一次问答的问答对语音数据;
转写单元,用于实时将问答对语音数据转写成对应的文本数据;
问答文本生成单元,用于将问答对的文本数据汇总成本次问询的问答文本。
虽然上述系统实施例及优选方案的工作方式以及技术原理皆记载于前文,但仍需指出的是,本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。可以把实施例中的模块或单元组合成一个模块或单元,也可以把它们分成多个子模块或子单元予以实施。
以及,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的系统实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上依据图式所示的实施例详细说明了本发明的构造、特征及作用效果,但以上仅为本发明的较佳实施例,需要言明的是,上述实施例及其优选方式所涉及的技术特征,本领域技术人员可以在不脱离、不改变本发明的设计思路以及技术效果的前提下,合理地组合搭配成多种等效方案;因此,本发明不以图面所示限定实施范围,凡是依照本发明的构想所作的改变,或修改为等同变化的等效实施例,仍未超出说明书与图示所涵盖的精神时,均应在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!