一种基于大数据的风险预警系统的制作方法
本发明涉及风险预警领域,具体涉及一种基于大数据的风险预警系统。
背景技术:
随着互联网的发展,越来越多的业务从线下转移到线上,在网上办理借贷等业务时,如何进行反欺诈、防恶意贷款等成为了银行等金融机构的关注重点,传统的只是对用户提交的资料的真实性进行审查,但对其贷款后是否会及时还款往往是根据工作人员的主观经验来进行判断,并不能够有效的进行风险预测,所以目前亟待需要一种能够有效对风险预测的方法来减少恶意贷款等行为带来的损失。
技术实现要素:
针对上述问题,本发明提供一种基于大数据的风险预警系统。
本发明的目的采用以下技术方案来实现:
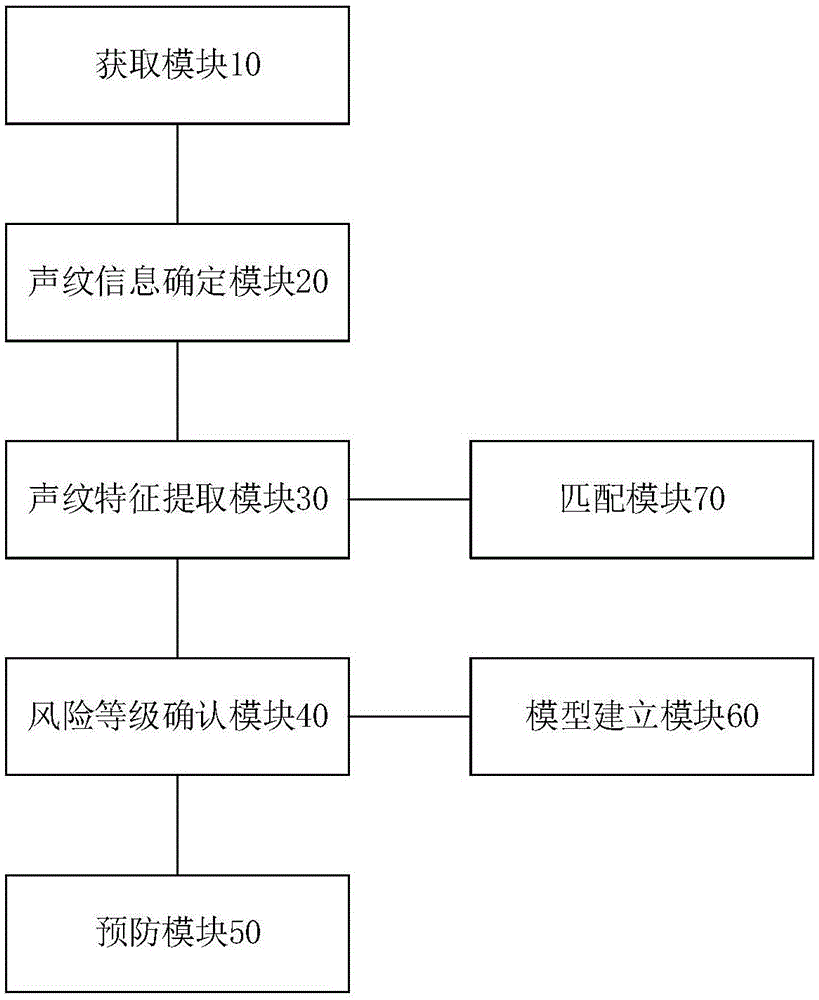
一种基于大数据的风险预警系统,该风险预警系统包括:获取模块,用于获取用户的语音信息;声纹信息确定模块,用于对所述的用户的语音信息进行处理,以获取用户的声纹信息;声纹特征提取模块,用于从用户的声纹信息中提取相应的声纹特征;风险等级确认模块,用于根据所述声纹特征确定用户的风险等级;预防模块,用于根据所述风险评估模块确定的风险等级执行相应的预防操作。
优选地,该风险预警系统还包括模型建立模块,所述模型建立模块与所述风险等级确认模块连接,其用于建立声纹大数据模型,分析出声纹特征与风险等级之间的对应关系。
所述的根据所述声纹特征确定用户的风险等级,具体是:根据所述声纹特征和所述声纹大数据模型,确定所述声纹特征与风险等级之间的对应关系,进而获取所述声纹特征所对应的风险等级。
优选地,所述声纹信息确定模块包括声纹检测单元、声纹去噪单元和声纹信息获取单元;所述声纹检测单元,用于对所述的用户的语音信息进行检测,以获取语音帧片段;所述声纹去噪单元,用于对所述语音帧片段进行降噪处理;所述声纹信息获取单元,用于对降噪后的语音帧片段进行数字化处理,以获取所述用户的声纹信息。
优选地,该风险预警系统还包括匹配模块,所述匹配模块用于将提取到的声纹特征与声纹黑名单中的声纹进行匹配,若匹配成功,则直接拒绝相应的操作请求,若匹配失败,则通知所述风险等级确认模块根据提取到的声纹特征确定用户的风险等级。
优选地,所述预防模块还用于根据预先建立的风险等级与预防操作之间的对应关系,确定与所述风险等级对应的预防操作。
优选地,所述对所述的用户的语音信息进行检测,以获取语音帧片段,其实现过程是:
(1)对用户的语音信息进行分帧、加窗操作;
(2)对分帧、加窗得到的每一帧数据进行傅里叶变换,以获取对应的振幅频谱、相位谱和噪声的频谱估计值;
(3)基于得到的每一帧数据的振幅频谱、噪声的频谱估计值,计算每一帧数据的deta值,根据得到的deta值判断各个帧是否为语音帧,具体判断方法是:
若deta(i)<t,第i帧为噪声帧,若deta(i)≥t,第i帧为语音帧,t为设定的阈值;遍历所有帧,然后将属于语音帧的帧数据进行去窗、叠加和快速傅里叶逆变换,即可得到时域里的语音帧片段;
其中,deta值的计算公式为:
式中,deta(i)为第i帧的deta值,i=1,2,…i,i为帧个数;s(i,k)为第i帧的振幅频谱,n(i,k)为噪声的频谱估计值,k表示第k个频点,其满足k=1,2,…,k。
本发明的有益效果为:本发明是基于大数据的声纹数据库,建立了声纹特征与风险等级之间的关系,然后根据用户的声纹特征可以获取用户对应的风险等级,然后根据确定的风险等级进行相应的预防操作。因为声纹具有特定性和稳定性的特点,通过建立声纹特征与风险等级之间的关系,可以便捷地获取用户对应的风险等级,从而可以根据该风险等级进行预防操作。
附图说明
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
图1是本发明实施例中基于大数据的风险预警系统的结构框图;
图2是本发明实施例中声纹信息确定模块的结构框图。
附图标记:获取模块10;声纹信息确定模块20;声纹特征提取模块30;风险等级确认模块40;预防模块50;模型建立模块60;匹配模块70;声纹检测单元21;声纹去噪单元22;声纹信息获取单元23。
具体实施方式
结合以下实施例对本发明作进一步描述。
图1示出了一种基于大数据的风险预警系统,该风险预警系统包括:获取模块10,用于获取用户的语音信息;声纹信息确定模块20,用于对所述的用户的语音信息进行处理,以获取用户的声纹信息;声纹特征提取模块30,用于从用户的声纹信息中提取相应的声纹特征;风险等级确认模块40,用于根据所述声纹特征确定用户的风险等级;预防模块50,用于根据所述风险评估模块确定的风险等级执行相应的预防操作。
优选地,该风险预警系统还包括模型建立模块60,所述模型建立模块60与所述风险等级确认模块40连接,其用于建立声纹大数据模型,分析出声纹特征与风险等级之间的对应关系。
所述的根据所述声纹特征确定用户的风险等级,具体是:根据所述声纹特征和所述声纹大数据模型,确定所述声纹特征与风险等级之间的对应关系,进而获取所述声纹特征所对应的风险等级。
在本实施例中,预先建立声纹大数据模型,根据以往有过恶意行为的声纹信息分析出声纹特征与风险等级之间的关系。然后获取与用户的声纹特征对应的风险等级。风险等级用于评估用户发生恶意行为的概率,比如,若是涉及借贷业务,此时风险等级就是用于评估用户借款后不按时还款的概率。若用户对应的风险等级比较高,说明该用户不还款的概率就比较高,可以通过降低该用户的借贷额度来进行预防。具体的,通过对大量的有过不良记录的声纹信息进行大数据分析,找出其共同具有的某些特征,然后将这些特征作为参考的依据。当获取到的用户的声纹特征后,计算用户的声纹特征与高风险的声纹特征之间的相似度,相似度越高,说明该用户的风险等级越高,反之,相似度越低,说明该用户的风险等级低。
优选地,参见图2,所述声纹信息确定模块20包括声纹检测单元21、声纹去噪单元22和声纹信息获取单元23;所述声纹检测单元21,用于对所述的用户的语音信息进行检测,以获取语音帧片段;所述声纹去噪单元22,用于对所述语音帧片段进行降噪处理;所述声纹信息获取单元23,用于对降噪后的语音帧片段进行数字化处理,以获取所述用户的声纹信息。
优选地,该风险预警系统还包括匹配模块70,所述匹配模块70用于将提取到的声纹特征与声纹黑名单中的声纹进行匹配,若匹配成功,则直接拒绝相应的操作请求,若匹配失败,则通知所述风险等级确认模块40根据提取到的声纹特征确定用户的风险等级。
建立声纹黑名单就是将有过恶意行为的人的声纹进行记录,即将有过不良记录的声纹拉入黑名单。通过该声纹黑名单,可以有效地防止二次风险,即防止有过不良记录的人继续进行恶意行为。
优选地,所述预防模块50还用于根据预先建立的风险等级与预防操作之间的对应关系,确定与所述风险等级对应的预防操作。
本发明的有益效果为:本发明是基于大数据的声纹数据库,建立了声纹特征与风险等级之间的关系,然后根据用户的声纹特征可以获取用户对应的风险等级,然后根据确定的风险等级进行相应的预防操作。因为声纹具有特定性和稳定性的特点,通过建立声纹特征与风险等级之间的关系,可以便捷地获取用户对应的风险等级,从而可以根据该风险等级进行预防操作。
优选地,所述对所述的用户的语音信息进行检测,以获取语音帧片段,其实现过程是:
(1)对用户的语音信息进行分帧、加窗操作;
(2)对分帧、加窗得到的每一帧数据进行傅里叶变换,以获取对应的振幅频谱、相位谱和噪声的频谱估计值;
(3)基于得到的每一帧数据的振幅频谱、噪声的频谱估计值,计算每一帧数据的deta值,根据得到的deta值判断各个帧是否为语音帧,具体判断方法是:
若deta(i)<t,第i帧为噪声帧,若deta(i)≥t,第i帧为语音帧,t为设定的阈值;遍历所有帧,然后将属于语音帧的帧数据进行去窗、叠加和快速傅里叶逆变换,即可得到时域里的语音帧片段;
其中,deta值的计算公式为:
式中,deta(i)为第i帧的deta值,i=1,2,…i,i为帧个数;s(i,k)为第i帧的振幅频谱,n(i,k)为噪声的频谱估计值,k表示第k个频点,其满足k=1,2,…,k。
有益效果:上述实施例中将用户的语音信息进行分帧、加窗和傅里叶变换后,根据得到的各个帧数据对应的振幅频谱、相位谱和噪声频谱估计值,求出各个帧的tae值,然后将得到的tae值与预设的阈值进行比较,进而完成对当前帧是否属于语音帧的判断,在求解tae值不仅考虑了当前帧的振幅频谱和噪声频谱估计值的影响,而且能够根据各个帧的振幅频谱和噪声频谱估计值实现对各个帧是否属于语音帧的自适应判断,提高了该声纹检测单元21的鲁棒性,降低了后续声纹去噪单元22和声纹信息获取单元23的工作负担,并提高了声纹去噪单元22和声纹信息获取单元23的工作效率,即只需对检测出来的语音帧片段分析即可,进而提高了声纹信息确认模块20的工作效率。
在一个具体的实施例中,各个帧的噪声频谱估计值可通过下述过程进行估算:
(1)基于分帧、加窗、傅里叶变换后的用户的语音信息,根据前十帧数据获取噪声频谱的初始估计值;
(2)利用下方的分段函数对噪声频谱估计值进行更新:
式中,n(i,k)为第i帧的噪声频谱估计值,s(i,k)为第i帧的振幅频谱,n0为噪声频谱的初始估计值,n(i-1,k)为第(i-1)帧的噪声频谱估计值,α1为平滑因子,其取值范围是:
有益效果:通常一段语音信号的前十帧只包含噪声帧,利用前十帧数据得到噪声频谱的初始估计值,然后基于得到噪声频谱的初始估计值、当前帧以及其上一帧的振幅频谱对当前帧的噪声频谱估计值进行更新,得到更新后的各个帧的噪声频谱估计值,该算法能够自适应的实现对各个帧的噪声频谱估计值的更新,提高了后续对语音帧检测的鲁棒性,有利于对语音帧片段的准确检测。
优选地,所述的对所述语音帧片段进行降噪处理,具体是:
(1)对所述语音帧片段进行分帧、加窗和傅里叶逆变换,获取相应帧的振幅频谱、功率谱、噪声频谱估计值和噪声功率谱;
(2)基于得到的每一帧的振幅频谱、功率谱、噪声频谱估计值和噪声功率谱,计算每一帧的噪声抑制增益因子,其中第j帧噪声抑制增益因子的计算公式为:
式中,g(j)为第j帧的噪声抑制增益因子,s(j,k)为第j帧的振幅频谱,n(j,k)为第j帧的噪声频谱估计值,ps(j,k)为第j帧的功率谱,pn(j,k)为第j帧的噪声功率谱,γ为权重系数,η为噪声衰减因子;
(3)基于得到所述语音帧片段的噪声抑制增益因子、振幅频谱和相位谱,通过去窗、叠加和快速傅里叶逆变换,即可得到降噪后的语音帧片段。
有益效果:在上述实施例中,将从声纹检测单元21得到的时域里的语音帧片段经过分帧、加窗和傅里叶变换后,并获取各个帧的振幅频谱、功率谱、噪声频谱估计值和噪声功率谱,根据自定义的噪声抑制增益因子的计算公式计算各个帧的噪声抑制增益因子,将得到的各个帧的噪声抑制增益因子与相应的振幅频谱相乘,即可得到修正后的振幅频谱。将修正后的振幅频谱及其相应的相位谱进行去窗、叠加和快速傅里叶变换,即可得到降噪后的语音帧片段,该算法通过对各个帧的振幅频谱进行修正,能够有效抑制所述语音帧片段中的随机噪声,同时增强了非噪声部分。使去噪后的语音帧片段保留语音信号中的细节特征,有利于后续从去噪后的语音帧片段中获取用户的声纹信息,并进一步获取用户的声纹特征,根据声纹特征确定用户的风险等级,该声纹去噪单元22便于后续对用户的风险等级的准确确认,进而采取与之相应的预防操作,能够真正做到对用户的风险等级的准确预测以及根据确认的风险等级进行预防操作。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!