一种基于深度卷积神经网络的智能挖掘机行人检测方法与流程
本发明涉及一种基于深度卷积神经网络的智能挖掘机行人检测方法(dcnn),具体来说,是指为了避免挖掘机在挖掘过程中发生安全事故,而将行人检测算法应用其中,通过检测行人框的大小,估算行人距挖掘机的距离,从而减少安全事故,实现智能化。
背景技术:
本发明依托背景是现在挖掘机都依靠人工操作,而重复高强度的工作强度极容易造成挖掘工作人员疲劳而带来安全事故的隐患。而智能化的行人检测算法可以实现挖掘设备的辅助操作,一定程度上可以减轻挖掘工作人员的工作强度。
行人检测是计算机视觉的研究方向之一,在智能驾驶、安防监控等领域有着较广泛的应用,越来越多的研究人员投入其中。具体来说,行人检测是指判定所给图片或者视频中是否包含行人,如果有行人标定其具体位置,位置标定是通过矩形框标出。在检测的图片样本中,行人可以是不同姿态的,可以保持站立也可以弯腰,行人站立的方向也可以位于不同角度,正面,侧面或是背面,只要样本中有行人,那么都应该在检测范围之内。
传统的行人检测主要通过hog+svm来实现,hog(histogramoforientedgradient)是指提取图片的hog特征,svm(supportvectormachine)即支持向量机用来进行分类,这种方法使用人工特征来统计计算图像的梯度方向直方图结合svm分类器来检测行人,虽然它在直立姿态行人图像上取得不错的效果,但是在行人相互遮挡以及非直立状态下效果不好,泛化能力较差。近些年卷积神经网络在图像识别检测领域产生越来越好的结果,rcnn(regionswithcnnfeatures)等一系列目标检测模型的精度远远超过传统方法。但是这种两阶段的网络虽然对一般尺度行人检测精度高但是其速度较慢,无法满足实时检测的需求,而且对小尺度目标行人的检测精度较低。而像yolo(youonlylookonce)、ssd(singleshotmultiboxdetector)这样一阶段的网络模型速度虽然快但精度低,无法满足实际需求。
因而,为了克服行人检测,尤其是挖掘工况下行人检测存在的缺陷,即行人目标存在的多尺度多姿态问题、检测精度与速度存在较大矛盾而无法满足工程需要的问题,本发明提出来一种单阶段检测的深度卷积神经网络的算法(dcnn)来进行挖掘工况下智能挖掘机行人检测。该方法通过自己构建行人数据集来训练神经网络算法,算法通过融合不同阶段的特征信息来解决多尺度多姿态检测的困难问题,借鉴了两阶段目标检测算法的anchor机制提高召回率,但保持了单阶段网络的速度。同时,本方法通过适当的调整便可推广到其他类型的行人检测工况下,普适性更广。
技术实现要素:
本发明针对智能挖掘机行人检测算法存在的多尺度多姿态问题,本发明提供了一种基于深度卷积神经网络算法的智能挖掘机行人检测方法(dcnn)。
本发明的技术方案为:
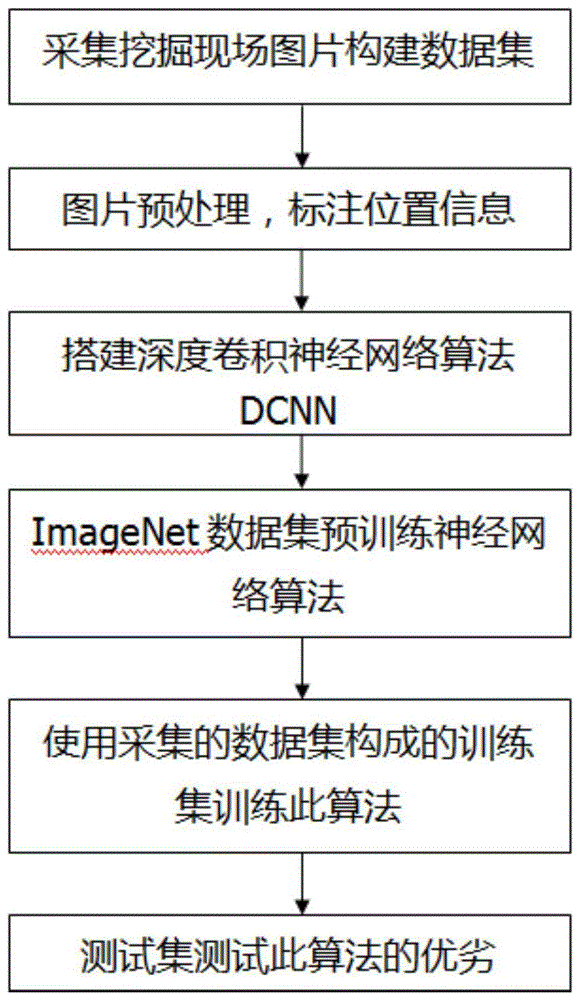
一种基于深度卷积神经网络的智能挖掘机行人检测方法,步骤如下:
s1根据在挖掘现场采集到的大量多样的行人图像数据,构建矿场的行人数据集(mpd),用于训练和测试深度卷积神经网络算法的数据;
s1.1采集挖掘矿区在不同天气、不同时刻的无人体的各种矿山背景图片作为负样本图片,共3000张;
s1.2采集挖掘矿区在上述不同情况下的行人图片,图片中人体的姿态、尺度、背景光照应多样,图片应该包含挖掘机日常工作所能拍摄的所有可能的情况,为正样本图片,共采集7000张;
s2将现场采集到的图像数据进行预处理,以去除噪声和冗余信息,并标注深度卷积神经网络算法所需要的图片上的位置信息来构建完整的行人数据集(mpd);
s2.1将步骤s1收集到的图片样本进行高斯滤波,直方图均衡化来去除噪声和图片增强;训练集包含8000张图片,测试集包含2000张图片,训练集和测试集各包含一半的正样本图片和一半的负样本图片;
s2.2使用iabelimg标注正样本图片中行人框的坐标,即行人框的左上角坐标和右下角x-y坐标,生成相应的xml文件,该xml文件包含行人框的坐标信息和正样本图片的绝对路径;行人框的坐标信息即为坐标框;
s3根据目标检测算法的常用模型,搭建本方法所用的深度卷积神经网络算法,具体步骤如下:
s3.1使用tensorflow深度学习框架来搭建此算法,主网络基本结构借鉴resnet网络的残差结构,即特征信息依次通过1*1、3*3、1*1的卷积操作,然后与原始信息相加,最后经过prelu激活函数输出;图片输入网络先通过7*7的卷积操作,最大池化操作,之后经过4个bottleneck,每个bottleneck将特征尺度缩小一倍,通道数增加一倍,4个bottleneck包含的残差结构的数目为3、4、6、3,输出特征记为c2、c3、c4、c5;
s3.2特征融合的结构是c5经过1*1卷积,将通道数改为256,记为p5;p5经过最近邻差值增加特征的尺度并与c4经过1*1卷积的特征相加得到p4,同理得到p3;
s3.3p3、p4、p5每个特征点产生9个预选框,宽高比是{1,2,3},尺度系数为
s3.4类别分类结构和边框回归结构是依次将特征p3、p4、p5分别经过四个3*3通道数为256的卷积操作,类别分类结构再经过3*3通道数为1*9的卷积操作,而边框回归结构再经过3*3通道数为4*9的卷积操作;
s3.5边框回归结构的公式如下:
其中,x、y、w、h分别为坐标框标签的中心点x-y坐标、宽、高,xa、ya、wa、ha分别为预选框的中心点x-y坐标、宽、高;
s3.6类别分类结构的损失函数采用focalloss,形式如下:
fl(pt)=-αt(1-pt)γlog(pt)
其中,αt为类别不平衡系数,γ为难易样本的比例系数,pt为预测的前景概率;
s3.7边框回归结构所采用的损失函数是smoothl1loss,形式如下:
s4为了使深度卷积神经网络算法更快收敛,使用imagenet公开数据集预训练神经网络算法的主网络模型,具体步骤如下:
s4.1图片数据输入网络前先对其进行随机翻折、旋转、平移缩放以及改变对比度来保证输入数据的多样性,提高算法的泛化能力,降低过拟合现象;之后进行归一化处理,然后送入网络进行训练;
s4.2去掉算法的分类回归部分,在主网络后加全连接层,使用imagenet数据集训练主网络结构;这样做主要是为了使算法参数的初始化值合理,加快算法收敛;
s4.3在经过s1与s2步骤构建的行人数据集(mpd)上训练搭建的网络,优化器是adam,初始学习率0.0001,batch_size为5,训练50epoch,总损失值从2.56降到0.35;
s5将标注好的图像数据分成训练数据集和测试数据集,用训练集来训练搭建好的神经网络算法;
s6构建soft-nms算法,以有效去除神经网络算法生成的多余候选框,已达到一人一框,具体步骤如下:
s6.1将置信度大于0的预选框取出,按置信度大小对预选框进行排序;
s6.2置信度最高的预选框与其他预选框取交并比值i0;
s6.3交并比值i0小于阈值0.5的那些其他预选框的置信度不变,而交并比值i0大于等于阈值0.5的那些预选框的置信度改为1-i0;
s6.4将置信度最大的预选框取出,如果置信度大于0.3,将剩余的预选框返回s6.1继续执行算法,否则退出算法,将取出的高置信度预选框作为算法最终预测的包含行人的坐标框;
行人检测算法的评价指标主要是当每张图片的假正数(falsepositiveperimage)为0.1时,漏检率(missrate)的大小,漏检率越小代表算法效果越好;
s7.使用测试集测试训练好的算法模型,若达不到精度,调节学习率等超参数重新训练算法模型。
本发明的有益效果:构建挖掘工况下,特定的行人检测数据集,并搭建了一个单阶段的行人检测的深度卷积神经网络算法,该算法并没有包含区域候选网络,速度明显比两阶段检测算法要快,通过融合不同阶段的特征信息来解决多尺度多姿态检测的困难问题,并且采用focalloss来提高检测精度。
附图说明
图1为基于深度卷积神经网络dcnn的智能挖掘机行人检测算法示意图;
图2为基于深度卷积神经网络dcnn算法流程图;
图3为基于深度卷积神经网络dcnn算法结构示意图;
图4为dcnn算法不同网络层输出的可视化结果;
图5为dcnn算法的分类损失、回归损失和总损失随训练epoch数的变化情况;
图6为比较该dcnn算法与其他流行的行人检测算法的漏检率。
具体实施方式
下面结合附图对本发明作进一步说明,本发明依托背景为智能挖掘机行人检测的多尺度多姿态问题,检测算法示意图如图1所示。
一种基于深度卷积神经网络算法的智能挖掘机行人检测方法,包括以下步骤:
s1.根据在挖掘现场采集到的大量多样的行人图像数据,生成用于训练和测试深度卷积神经网络算法的数据;
s2.将现场采集到的图像数据进行预处理,以去除噪声和冗余信息,并标注神经网络算法所需要的图片上的位置信息;
s3.根据流行的通用目标检测算法的常用模型,搭建本发明所用的深度卷积神经网络算法;
s4.为了使神经网络算法更快收敛,使用imagenet公开数据集预训练神经网络算法的主网络模型;
s5.将标注好的图像数据分成训练数据集和测试数据集,用训练集来训练搭建好的神经网络算法;
s6.构建soft-nms算法,以有效去除神经网络算法生成的多余候选框,已达到一人一框;
s7.使用测试集测试训练好的算法模型,若达不到精度,调节学习率等超参数重新训练算法模型。
其中,采集用于训练和测试深度卷积神经网络算法的行人图像数据,用于构建矿场专用的行人数据集(mpd)的步骤如下:
s1.采集挖掘矿区在不同天气、不同时刻的不含人体的各种矿山背景图片作为负样本图片,一共有3000张;
s2.采集挖掘矿区在上述不同情况下的行人图片,图片中人体的姿态、尺度、背景光照应多样,图片应该包含挖掘机日常工作所能拍摄的所有可能的情况,一共采集到7000张;
图像数据进行预处理并标注神经网络算法所需要的图片上的位置信息的步骤如下:
s1.将收集到的图片样本进行高斯滤波,直方图均衡化来去除噪声和图片增强;训练集包含8000张图片,测试集包含2000张图片,训练集和测试集各包含一半的正样本和一半的负样本。
s2.使用iabelimg标注正样本图片中行人框的坐标,具体就是行人框的左上角坐标和右下角x-y坐标,生成相应的xml文件,该文件除了框坐标信息,还应包含图片文件的绝对路径,
搭建本发明所用的深度卷积神经网络算法(dcnn),具体步骤如下:
s1.使用tensorflow深度学习框架来搭建此算法,主网络基本结构借鉴resnet网络的残差结构,即特征信息依次通过1*1、3*3、1*1的卷积操作,然后与原始信息相加,最后经过prelu激活函数输出。图片信息输入网络先通过7*7的卷积操作,最大池化操作,之后经过4个bottleneck,每个bottleneck将特征尺度缩小一倍,通道数增加一倍,4个bottleneck包含的残差结构的数目为3、4、6、3,输出特征记为c2、c3、c4、c5,算法的c2、c3、c4、c5层输出特征的可视化结果如图3所示。
s2.特征融合的结构是c5经过1*1卷积,将通道数改为256,记为p5,p5经过最近邻差值增加特征的尺度并与c4经过1*1卷积的特征相加得到p4,同理可以得到p3;
s3.p3、p4、p5每个特征点产生9个预选框,宽高比是{1,2,3},尺度系数为
s4.类别分类和边框回归结构是依次将特征p3、p4、p5分别经过四个3*3通道数为256的卷积操作,类别分类结构再经过3*3通道数为1*9的卷积操作,而边框回归结构再经过3*3通道数为4*9的卷积操作;
s5.边框回归的公式如下:
其中x、y、w、h分别为坐标框标签的中心点x-y坐标和宽高,xa、ya、wa、ha分别为预选框的中心点x-y坐标和宽高。
s6.类别分类的损失函数采用focalloss,形式如下:
fl(pt)=-αt(1-pt)γlog(pt)
其中αt为类别不平衡系数,γ为难易样本的比例系数,pt为预测的前景概率
s7.边框回归所采用的损失函数是smoothl1loss,形式如下:
如图4所示,训练此深度卷积神经网络的算法,具体步骤如下:
s1.图片数据喂入网络前先对进行随机翻折、旋转、平移缩放以及改变对比度等变化来保证输入数据的多样性,提高算法的泛化能力,降低过拟合现象。之后进行归一化处理,然后送入网络进行训练;
s2.去掉算法的分类回归部分,在主网络后加全连接层,使用imagenet数据集训练主网络结构。这样做主要是为了使算法参数的初始化值合理,加快算法收敛。
s3.在s1与s2步骤构建的行人数据集(mpd)上训练搭建的网络,优化器是adam,初始学习率0.0001,batch_size为5,训练50epoch,总损失值从2.56降到0.35。
此算法训练过程中loss的变化情况如图5所示。
soft-nms算法的具体步骤如下:
s1.将置信度大于0的预选框取出,按置信度大小对预选框进行排序;
s2.置信度最高的预选框与其他预选框取交并比值i0;
s3.交并比值i0小于阈值0.5的那些其他预选框的置信度不变,而交并比值i0大于等于阈值0.5的那些预选框的置信度改为1-i0。
s4.将置信度最大的预选框取出,如果置信度大于0.3,将剩余的预选框返回s1继续执行算法,否则退出算法,将取出的高置信度预选框作为算法最终预测的包含行人的坐标框。
图6为dcnn算法与其他行人检测算法的评价结果比较图。由图可以明显看出dcnn的效果最好,tffi=0.1时,漏检率是5.775%。
- 还没有人留言评论。精彩留言会获得点赞!