一种亲属关系识别方法及系统与流程
本发明涉及亲子鉴定领域,特别涉及一种亲属关系识别方法及系统。
背景技术:
目前,中国每年失踪儿童人数高达20万。根据专家保守统计,每年有20万失踪儿童中只有0.1%被找回。dna亲子鉴定,是运用生物学、遗传学以及有关学科的理论和技术,根据遗传性状在子代和亲代之间的遗传规律,判断被控的父母和子女之间是否亲生关系的鉴定,是一种高精度的检定技术;但是,一方面由于失踪儿童的dna获取非常的困难,另一方面由于dna鉴定技术由于成本太高不适合大规模失散儿童的查询。因此,dna检定技术无法有效的应用于寻找失踪儿童,如何不通过dna技术进行亲子鉴定,成为一个亟待解决的技术问题。
技术实现要素:
本发明的目的是提出一种基于人脸视频的亲属关系识别方法,实现在不采用dna数据的前提下完成人物亲属关系的认证。
为实现上述目的,本发明提供了如下方案:
本发明实施例的第一个方面,提供了一种亲属关系识别方法,所述识别方法包括如下步骤:
基于人脸视频,构建用于描述父母和孩子关系的人脸视频数据库;
对所述人脸视频数据库中的视频进行预处理,并进行人脸检测、人脸归一化处理后,得到输入人脸图像;
建立卷积神经网络模型,以所述输入人脸图像作为输入,训练所述卷积神经网络模型;
通过训练后的所述卷积神经网络模型进行特征识别,输出是否具有亲属关系的判别结果。
可选的,对所述人脸视频数据库中的视频进行预处理,具体包括:
将所述视频分成预设段数的短视频;
从每一段短视频中获取一张图像,作为图像训练样本。
可选的,从每一段短视频中获取一张图像,作为图像训练样本,具体包括:
将所述短视频中的每一帧的图像分别与其前预设帧数的图像和后预设帧数的图像进行比较,获得差值;
选取所述差值最小的图像作为图像训练样本。
可选的,进行人脸检测,具体包括如下步骤:
建立人脸识别线性分类器;
利用所述人脸识别线性分类器提取所述图像训练样本中的人脸部分,得到人脸图像训练样本。
可选的,人脸归一化处理,具体包括:
对所述人脸图像训练样本中人脸中的预设数量个特征点进行定位,得到每个特征点的位置;
根据所述特征点的位置将所述人脸图像训练样本中的人脸变换到统一的角度,得到输入人脸图像。
可选的,建立卷积神经网络模型,具体包括:
在卷积层设置12个5乘5的滤波器、并采用一个带有2乘2核的最大池层,步幅为2;
将特征识别结果输出压缩成一个向量,应用一全连接层,通过sigmoid非线性函数去输出判别结果。
本发明实施例的第二个方面,还提供一种亲属关系识别系统,该识别系统包括:
人脸视频数据库构建模块,用于基于人脸视频,构建用于描述父母和孩子关系的人脸视频数据库;
输入人脸图像获取模块,用于对人脸视频数据库中的视频进行预处理,并进行人脸检测、人脸归一化处理后,得到输入人脸图像;
卷积神经网络模型训练模块,用于建立卷积神经网络模型,以输入人脸图像作为输入,训练卷积神经网络模型;
亲属关系判别模块,用于通过训练后的卷积神经网络模型进行特征识别,输出是否具有亲属关系的判别结果。
可选的,输入人脸图像获取模块,具体包括:
视频分段单元,用于将视频分成预设段数的短视频;
比较单元,将短视频中的每一帧的图像分别与其前预设帧数的图像和后预设帧数的图像进行比较,获得差值;
图像训练样本选取单元,选取差值最小的图像作为图像训练样本。
可选的,图像训练样本获取子模块,还包括:
线性分类器建立子模块,用于建立人脸识别线性分类器;
人脸部分获取子模块,用于利用人脸识别线性分类器提取所述图像训练样本中的人脸部分,得到人脸图像训练样本。
可选的,输入人脸图像获取模块,还包括人脸归一化处理子模块;
人脸归一化处理子模块,用于对人脸图像训练样本中的人脸中的预设数量个特征点进行定位,得到每个特征点的位置;并根据特征点的位置将人脸图像训练样本中的人脸变换到统一的角度,得到输入人脸图像。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明公开了一种亲属关系识别方法及系统。该方法基于高质量人脸视频构建人脸视频数据库,然后,对人脸视频库中的视频进行预处理,并进行人脸检测和归一化处理,得到统一后的输入人脸图像,并采用输入人脸图像训练卷积神经网络模型,通过训练后的卷积神经网络模型进行基于视频的亲属关系识别。该方法实现了基于视频的亲属关系识别,无需应用dna技术,降低了亲子识别的成本,一定程度上提高了亲子识别的便利性,可广泛应用于失踪儿童的寻找。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种亲属关系识别方法的流程图;
图2为本发明提供的图像训练样本的选取结果图;
图3为本发明提供的人脸图像训练样本的获取结果图;
图4为本发明提供的在归一化处理过程中人脸关键点检测的结果图;
图5为本发明提供的经过本发明的归一化处理的输入图像和未经过归一化处理的输入图像随光照变化的曲线图;
图6为本发明提供的本发明的识别方法和其他识别方法的工作特征曲线比较示意图。
具体实施方式
本发明的目的是提供一种亲属关系识别方法及系统,以实现监控场景下的亲属关系验证。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对发明作进一步详细的说明。
实施例1
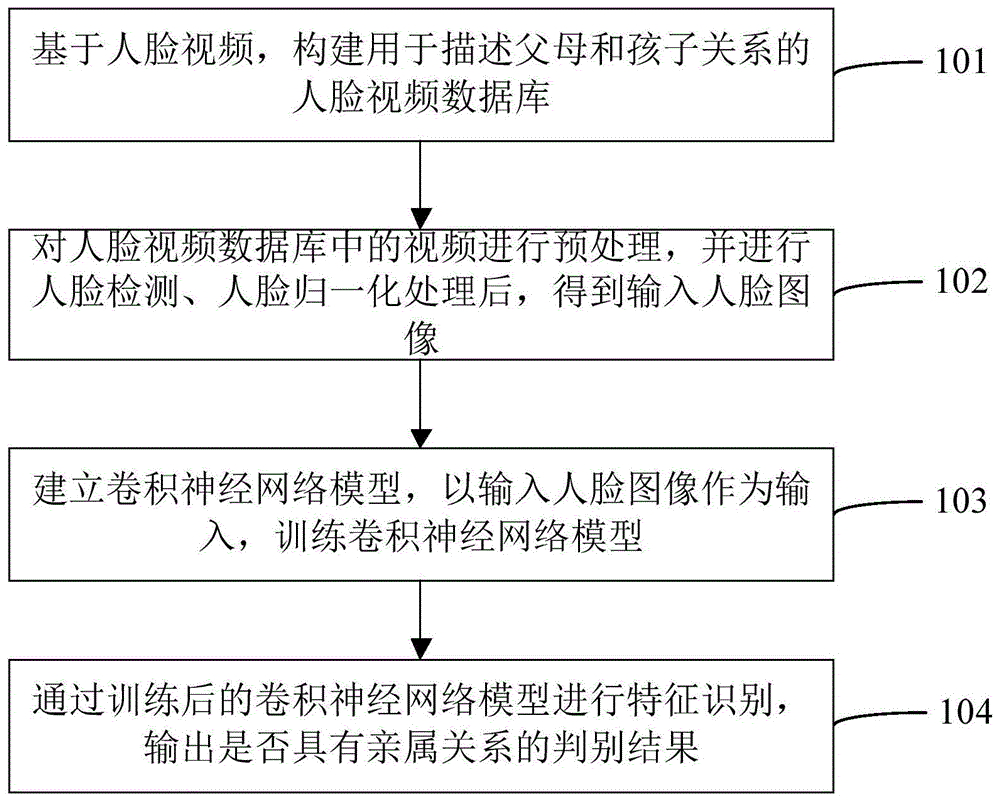
本发明实施例1提供了一种亲属关系识别方法,如图1所示,所述识别方法包括如下步骤:
步骤s101,基于人脸视频,构建用于描述父母和孩子关系的人脸视频数据库。
步骤s102,对人脸视频数据库中的视频进行预处理,并进行人脸检测、人脸归一化处理后,得到输入人脸图像。
步骤s103,建立卷积神经网络模型,以输入人脸图像作为输入,训练所述卷积神经网络模型。
步骤104,通过训练后的卷积神经网络模型进行特征识别,输出是否具有亲属关系的判别结果。
卷积神经网络模型构建并训练完成后,将待测视频按照步骤s102进行处理提取出输入人脸图像,作为卷积神经网络模型的输入,经过该卷积神经网络模型进行特征识别,并输出是否具有亲属关系的判别结果。
本发明该实施例提供的亲属关系判别该方法,能够在不采用dna数据的前提下通过人脸识别实现人物亲属关系的识别,通过自建的人脸视频数据库进行仿真实验结果证明,该方法具有较好的识别性能。
实施例2
本发明实施例2提供一种亲属关系识别方法的一个优选实施例。在本实施例中该方法包括步骤:
步骤201,构建用于描述父母和孩子关系的人脸视频数据库。
在实际应用中,要得出一个精确的机器学习结果,收集数据很重要。一个大的高质量的视频数据集会比图片数据集生成更好的结果,因为它有更多的时间相关的数据。本发明的视频包括网络的公开视频和志愿者的私有视频,都是高质量的,其中公开视频以名人为主,比如总统家庭和其他皇室家庭接受采访,还有其他上电视节目的家庭;私有的视频则来自志愿者。本发明的视频建立过程为手动对所述公开视频和志愿者的私有视频中截取3-10秒的动态短视频。其中接近80%来自网上的节目,其他的是在真实生活中拍摄的。
本发明收集了不同家庭的100组视频,每组3个视频分别来自父母和孩子。截取的视频均为一个人的镜头特写,保证五官清晰且呈现完整。所有的视频平均时长为4.2秒。将100组视频全部存储为mp4格式,命名方式为1-100,标注父亲、母亲和孩子分别为f、m、c。例如,第25组的父亲为25_f.mp4,第76组的孩子为76_c.mp4。每一组家庭均有三个样本,分别是父亲、母亲、孩子的视频样本。利用matlab读入每个家庭的样本,以“_”作为区别,前半部分为组号,后一个字符用于归类是父亲、母亲还是孩子。
人脸视频数据库包含了具有不同表情和角度的人脸视频,而且本发明的人脸视频数据库中的视频不仅提供了更便于使用的数据,而且阐释了三个家庭的关系,而不是普通的双人关系成员,提高了卷积神经网络模型训练的精度。
步骤s202,视频预处理。
考虑到输入视频的长度在5s以上,那么这一段小视频中包含了上百帧的人脸图像,这其中便会遇到数据量过于庞大和某些帧图像不清晰的双重问题。针对输入数据过于庞大的问题,本发明实施例选择在上百帧包含人脸的图像中提取4张有代表性的人脸图像,优选地,这些图像中的人脸是不同表情的。
本发明实施例将视频分为4个时间更短的视频,并在每一段视频中选取一个较好的人脸图像。针对个别帧图像不清晰的问题,本发明实施例将某一帧的图像与前后若干帧进行比较,找到与前后变化最小的那一张图像,并作为该段视频中的最优人脸图像,即图像训练样本。例如,图2为图像训练样本的选取结果图,其每排的最后一张图像为选取的图像训练样本。通过上述步骤,本发明实施例从任意一段视频中可以提取一组图像,包含4个较为清晰并且表情不同的人脸图像。
步骤s203,人脸检测。
步骤s202得到的人脸在画面中占有的比例不是固定的,因此本发明实施例采用人脸检测器从人脸画面中检测出人脸区域。具体在实施的过程中,采用经典的adaboost人脸检测器,从给定人脸图像中自动找到一个区域,其包含了人脸区域的所有像素。最终,本发明将该部分截取下来,统一图像尺寸,作为卷积神经网络的输入图像,即人脸图像训练样本。图3为人脸图像训练样本的获取结果示意图。
步骤s204,人脸图像归一化处理。
在步骤s203之后得到的每组4张图像中,人脸的角度会有所不同。为了使人脸图像更加统一,本发明实施例采用了asm(activeshapemodel,主动形状模型)算法,首先搜集训练样本并记录关键特征点,之后构建训练集的形状向量并归一化,经过pca处理后为每个特征点构建局部特征,即可对人脸中的28个特征点进行定位。通过定位这些特征点的位置,本发明实施例对人脸图像做进一步的变换,得到输入人脸图像,以提高卷积神经网络的分类准确度。图4为进行特征点定位后的输入人脸图像的获取结果示例图。在后期的实验中,本发明实施例发现归一化步骤可以将分类准确度从83.06%提升至89.42%。
步骤s205,卷积神经网络的建立与训练。
卷积神经网络(convolutionalneuralnetwork,cnn)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现,包括卷积层(convolutionallayer)和池化层(poolinglayer)。
cnn的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
本发明实施例中,构建的卷积神经网络模型的卷积层用了12个5乘5的滤波器,并且用了一个带有2乘2核的最大池层,步幅为2。这个向下取样的过程减少了神经网络中参数的数量,同时在分类器中引进了平移不变性。之后,本发明实施例将结果输出压缩成一个向量,应用了一个完全连接层,并且通过sigmoid函数输出输入脸符合一个家庭的可能性大小。sigmoid函数,即神经元的非线性作用函数,f(x)=1/(1+e^-x)。
完成卷积神经网络模型的构建和训练后,则需要对待识别人员进行具体识别。在该实施例中,待识别人员的视频中获取待识别图像的方法,与从人脸视频数据库中的视频中提取输入人脸图像的方法相同,包括将待识别人员的视频分成预设段数的短视频,从每一段短视频中获取一张图像,作为待识别图像输入卷积神经网络模型。
本发明通过视频预处理、人脸检测、人脸对齐、特征识别和结果输出这五步完整的流程,实现了基于人脸视频的亲属关系识别,经过实际测试,该方法可以提高分类器精度,达到较为理想的识别准确度。
实施例3
本发明实施例3提供一种亲属关系识别系统,包括:人脸视频数据库构建模块、输入人脸图像获取模块、卷积神经网络模型训练模块和亲属关系判别模块。
人脸视频数据库构建模块,用于基于人脸视频,构建用于描述父母和孩子关系的人脸视频数据库。输入人脸图像获取模块,用于对人脸视频数据库中的视频进行预处理,并进行人脸检测、人脸归一化处理后,得到输入人脸图像。卷积神经网络模型训练模块,用于建立卷积神经网络模型,以输入人脸图像作为输入,训练卷积神经网络模型。亲属关系判别模块,用于通过训练后的卷积神经网络模型进行特征识别,输出是否具有亲属关系的判别结果。
优选地,输入人脸图像获取模块,具体包括:视频分段子模块,用于将视频分成预设段数的短视频;图像训练样本获取子模块,用于从每一段短视频中获取一张图像,作为图像训练样本。图像训练样本获取子模块,具体包括:比较单元,将短视频中的每一帧的图像分别与其前预设帧数的图像和后预设帧数的图像进行比较,获得差值;图像训练样本选取单元,选取差值最小的图像作为图像训练样本。
为了进一步的提高图像训练样本的质量,以提高训练的精度,所述输入人脸图像获取模块还包括:线性分类器建立子模块,用于建立人脸识别线性分类器;人脸部分获取子模块,用于利用所述人脸识别线性分类器提取所述图像训练样本中的人脸部分,得到人脸图像训练样本。
优选地,卷积神经网络模型训练模块,用于在卷积层设置12个5乘5的滤波器、并采用一个带有2乘2核的最大池层,步幅为2;将特征识别结果输出压缩成一个向量,应用一全连接层,通过sigmoid非线性函数去输出判别结果。
本发明建立了一个大型人脸视频数据集并完成人物亲属关系的标注,在此基础上设计了一种计算模型,应用卷积神经网络进行人物亲属关系的识别,判断三段人脸视频是否来自于同一个家庭。该方法为一种基于人脸视频的亲属关系识别方法,建立了一种全新的人脸亲属关系识别的数据集ffvw(familyshipfacevideosinthewild),该数据集是基于人脸视频而不是人脸图像的,而且它描述了父母和孩子三人的关系,而不是一对亲子的关系。
本发明对比了ffvw和其他现有技术已有识别方法的效率,也检查了数据处理的时间线。
参见图5所示,图5为处理输入数据光照强度(正常)和未处理光照强度(昏暗)的ffvw工作曲线,其显示了随着光照强度趋于正常,识别准确率的提升。由以往的研究可知,光照强度是影响人脸识别的一个重要因素。相比于正常光照,昏暗灯光下的照片往往带来了不尽如人意的识别结果。本发明运用现有技术cnn中已有的学习与训练模型来分析识别的准确性。仿真实验结果表明,昏暗的灯光依旧导致了一些程度上的准确率失常。
更重要的是,本发明发现人脸对齐的过程将分类器的准确度从83.06%提升到了89.42%。
上述两个实验都证实了本发明在保证输入一致性上取得的成功。在本发明中,处理的输入为抖动的视频,人脸对齐的过程为不可或缺的一步,因为视频中的截图可能为对应人物人脸的任何角度,经过人脸对齐后再进行下一步处理。
参见图6所示,图6示出了本发明的亲属关系识别方法和现有识别方法的工作特征曲线(roc曲线)。图5统一总结了实验结果。可以明显地看到,本发明识别方法(即图中所示vbr)相比于其他方法例如sbm(slacks-basedmeasuremodel)和abm(agent-basedmodel)带来了高达4-48.6%表现上的提升。由此可见,按照本发明识别方法设置的卷积神经网络模型在本发明数据集下有极为出色的表现。经实验表明,本发明的识别方法足够达到血缘关系识别配对的准确度,在较少的输入也可达到较为理想的识别准确度。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!