一种电网计量大数据存储系统及其创建方法与流程
本申请涉及电网技术领域,尤其涉及一种电网计量大数据存储系统及其创建方法。
背景技术:
随着现代计算、通信和网络计算的发展,电力系统的互联程度和远距离输电系统的不断进步,能覆盖一个甚至多个大型区域的大规模电力系统正在不断地出现;伴随着电力系统规模的不断扩大和结构的越趋复杂,对于系统安全的评估、安全与经济运行、系统控制将变得越来越困难;此外,最近2年在世界范围内成为热潮的电力系统“智能化”趋势也给现有的电力系统分析计算和控制工具带来了极大挑战。
为了更好地满足未来智能电网海量数据存储的巨大需求,需要一种有效的电网计量大数据存储方法。
技术实现要素:
本申请实施例提供了一种电网计量大数据存储系统及其创建方法,使得电网计量大数据存储系统可以满足未来智能电网海量数据存储的巨大需求。
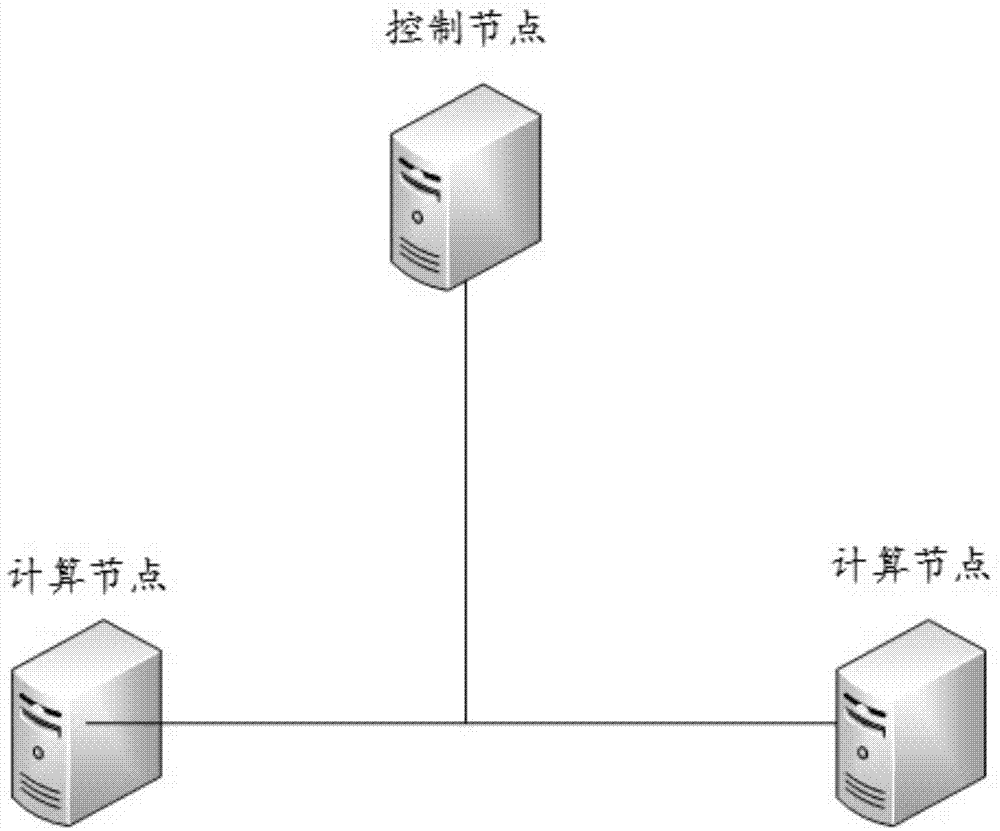
有鉴于此,本申请第一方面提供了一种电网计量大数据存储系统,包括:多台计算机;
每台计算机上创建有多台可长时间运行的虚拟机,每台所述虚拟机上安装有hadoop平台且挂载有本地存储磁盘;
任意两台计算机间通信连接,且每台计算机均与公共网络连接;
多台计算机中的一台计算机为控制节点,且所述控制节点上运行有openstack云计算平台的核心服务,所述核心服务包括keystone、glance、cinder和quantum中的至少一种;
除所述控制节点外的其他计算机为计算节点,且所述计算节点上运行有openstacknova计算服务。
优选地,
每台计算机上的所有虚拟机的rack值相同。
优选地,
当所述核心服务包括cinder时,所述控制节点上升成的卷通过iscsi协议与所述计算节点连接。
优选地,
所述openstack云计算平台的磁盘类型为根磁盘。
本申请第二方面提供一种电网计量大数据存储系统的创建方法,包括:
在多台计算机中的每台计算机上创建可长时间运行的至少两台虚拟机,并将本地存储磁盘挂载到每台虚拟机上;
在每台所述虚拟机上安装有hadoop平台;
将多台计算机中的一台计算机作为控制节点,并在所述控制节点上运行openstack云计算平台的核心服务,所述核心服务包括keystone、glance、cinder和quantum中的至少一种;
将除控制节点外的其他计算机作为计算节点,并在所述计算节点上运行openstacknova计算服务;
将任意两台计算机间通信连接,并将每台计算机与公共网络连接。
优选地,
当所述核心服务包括cinder时,通过iscsi协议将所述控制节点上升成的卷与所述计算节点连接。
优选地,
所述的创建方法还包括:采用根磁盘作为所述openstack云计算平台的磁盘类型。
优选地,
所述的创建方法还包括:定期对根磁盘中的数据进行快照。
优选地,
所述的创建方法还包括:将每台计算机上的所有虚拟机的rack值设置为相同。
优选地,
所述的创建方法还包括:修改所述虚拟机本身的初始化序列。
优选地,
所述的创建方法还包括:增加用于指示所述计算节点中是否包括卷的标志。
优选地,
所述的创建方法还包括:创建过滤器,通过所述过滤器对虚拟机的启动进行控制。
从以上技术方案可以看出,本申请实施例具有以下优点:
本申请实施例中,提供了一种电网计量大数据存储系统,包括:多台计算机;每台计算机上创建有多台可长时间运行的虚拟机,每台所述虚拟机上安装有hadoop平台且挂载有本地存储磁盘;任意两台计算机间通信连接,且每台计算机均与公共网络连接;多台计算机中的一台计算机为控制节点,且所述控制节点上运行有openstack云计算平台的核心服务,所述核心服务包括keystone、glance、cinder和quantum中的至少一种;除所述控制节点外的其他计算机为计算节点,且所述计算节点上运行有openstacknova计算服务;在这个存储系统中,大量虚拟机在openstack云计算平台下长期运行,这些虚拟机整体构成了与hadoop集群类似的系统架构,其中每个虚拟机都类似于hadoop集群的单个节点,可以满足未来智能电网海量数据存储的巨大需求;并且,与直接硬件构成的hadoop集群相比,由于空闲的虚拟机并不会占用太多的硬件资源,因而,通过虚拟机的方式生成大于需求数量的hadoop节点,对计算机不会造成太大的性能影响。
附图说明
图1为本申请实施例中电网计量大数据存储系统的一个实施例的结构示意图;
图2为本申请实施例中电网计量大数据存储系统的创建方法的一个实施例的流程示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为了便于理解,请参阅图1,图1为本申请实施例中电网计量大数据存储系统的一个实施例的结构示意图。
本申请实施例提供了一种电网计量大数据存储系统,包括:多台计算机。
每台计算机上创建有多台可长时间运行的虚拟机,每台虚拟机上安装有hadoop平台且挂载有本地存储磁盘。
需要说明的是,可以对本地存储磁盘进行分区,一个虚拟机可以挂载一个或多个分区。
hadoop是一个分布式文件系统基础框架,它最核心的由hdfs和mapreduce两部分组成,主要是用于设计实现具有高可靠性、高效性、大规模性于一体的分布式数据存储和处理框架,它的设计思想就是将单一的服务器节点扩展成为成千上万个服务器节点集群,且实现节点集群中的每个服务器节点同时具有数据本地存储和处理能力。
hdfs是设计在通用计算机上的分布式文件系统,具有高容错性,并一般部署在廉价的商用计算机上,实现应用程序高的数据吞吐量,主要应用于存储和处理大规模海量数据集,hdfs遵循posix协议,以保证应用程序流式快速存储和处理文件系统数据。
mapreduce是hadoop框架中的核心部分,它主要用于廉价的商用计算机硬件集群对海量数据实现高可靠性、高扩展性、高容错性的并行计算,其基本思想是将一个大的复杂问题,分解成多个简单的小问题进行解决,然后将多个小问题的结果进行合并,最终得到初始的复杂问题的解。mapreduce这种分布式数据处理模式是处理大数据的一个非常重要的方式。它的这种设计适合于处理大集群的且持续增长的海量数据的计算。
因此,本申请实施例在每台虚拟机上都安装hadoop平台,以适应电网计量大数据的量大及持续增长的特点。
任意两台计算机间通信连接,且每台计算机均与公共网络连接。
具体地,每台计算机可以采用英特尔至强e3-1220v2@3.10ghz,8mb缓存,16gb内存和1tb硬盘的硬件配置,两台计算机之间、计算机与公共网络之间均可以通过1g网络实现通信连接。
多台计算机中的一台计算机为控制节点,且控制节点上运行有openstack云计算平台的核心服务,核心服务包括keystone、glance、cinder和quantum中的至少一种。
除控制节点外的其他计算机为计算节点,且计算节点上运行有openstacknova计算服务。
需要说明的是,为了说明电网计量大数据存储系统的结构和连接关系,本申请实施例通过以三台计算机为例,具体可参阅图1,这三台计算机中的一台为控制节点,两外两台为计算节点,三台计算机之间相互通信连接;可以理解的是,为了适应电网计量大数据的海量数据,电网计量大数据存储系统中的计算机数量远远超过三台。
进一步地,每台计算机上的所有虚拟机的rack值相同。
可以理解的是,由于在云计算系统中,包含同一个文件副本的多台虚拟机,有可能被调度在相同的物理机器上,为了保证hadoop的复制功能不被破坏,可以使用hadoop的rackawareness属性配置将同一台计算机上运行的所有虚拟机指定为相同的rack值,保证不同计算机上存在不同的数据副本。
进一步地,当核心服务包括cinder时,控制节点上升成的卷通过iscsi协议与计算节点连接。
可以理解的是,cinder用于提供卷管理服务。
进一步地,openstack云计算平台的磁盘类型为根磁盘。
需要说明的是,在openstack云计算平台中,一共包含三种类型的存储:根磁盘、短暂磁盘和持久磁盘;其中,一台虚拟机的根磁盘是直接驻留在宿主机器而不附着于网络上,这也意味着其不依赖于网络延迟和带宽的影响;短暂磁盘的数据尽管也不附着于网络,但是非持久化的;持久磁盘是通过网络依附于openstack卷服务的持久化存储,其使用和性能都受到网络环境的影响;所以本申请实施例选择使用根磁盘类型作为openstack云计算平台的磁盘类型,用来运行虚拟机hadoop架构中的hdfs组件。
请参阅图2,本申请实施例中电网计量大数据存储系统的创建方法的一个实施例的流程示意图。
本申请实施例提供一种电网计量大数据存储系统的创建方法的一个实施例,包括:
步骤101,在多台计算机中的每台计算机上创建可长时间运行的至少两台虚拟机,并将本地存储磁盘挂载到每台虚拟机上。
步骤102,在每台虚拟机上安装有hadoop平台。
步骤103,将多台计算机中的一台计算机作为控制节点,并在控制节点上运行openstack云计算平台的核心服务,核心服务包括keystone、glance、cinder和quantum中的至少一种。
可以理解的是,openstack云计算平台有多种服务,核心服务的种类可以根据实际需要进行设置。
步骤104,将除控制节点外的其他计算机作为计算节点,并在计算节点上运行openstacknova计算服务。
步骤105,将任意两台计算机间通信连接,并将每台计算机与公共网络连接。
需要说明的是,步骤103、步骤104和步骤105之间没有严格先后顺序,不限于图2所示的执行顺序。
进一步地,当所述核心服务包括cinder时,通过iscsi协议将所述控制节点上升成的卷与所述计算节点连接。
进一步地,创建方法还可以包括:采用根磁盘作为所述openstack云计算平台的磁盘类型。
进一步地,创建方法还可以包括:定期对根磁盘中的数据进行快照。
需要说明的是,由于根磁盘类型存储不具有持续性,即存储在根磁盘的数据在虚拟机终止之后将会丢失,因此通过异步执行的后台任务定期地对根磁盘中的数据进行快照,这样,即使虚拟机崩溃,存储在根磁盘中的数据并不会立即消失,只要将虚拟机快速重新启动,存储的数据将不会丢失。
进一步地,创建方法还可以包括:将每台计算机上的所有虚拟机的rack值设置为相同。
进一步地,创建方法还可以包括:修改所述虚拟机本身的初始化序列。
通过改变初始化序列,可以避免虚拟机对连接的本地存储磁盘进行格式化。
进一步地,创建方法还可以包括:增加用于指示所述计算节点中是否包括卷的标志。
需要说明的是,openstack云计算平台包含一个libvirt_images_volume_group配置标记,libvirt_images_volume_group配置标记用来指定在每个计算节点中包含的短暂磁盘卷组了;在本申请实施例中,标志libvirt_localpersistent_volume_group可以与openstack中libvirt_images_volume_group类似,用于指定计算节点包含local_persistent卷,以保证能够通过常用的openstack访问控制机制来对local_persistent卷进行访问。
进一步地,创建方法还可以包括:创建过滤器,通过所述过滤器对虚拟机的启动进行控制。
需要说明的是,通过创建过滤器并设定相应的过滤条件,可以保证管理员能够利用过滤器调度控制,使得仅在包含local_persistent的计算节点上启动长期运行的虚拟机。
以上,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!