基于聚类与熵比率的废旧动力电池一致性指标优选的制作方法
本发明属于废旧动力电池指标评价领域,尤其涉及一种基于聚类与熵比率的废旧动力电池一致性指标优选。
背景技术:
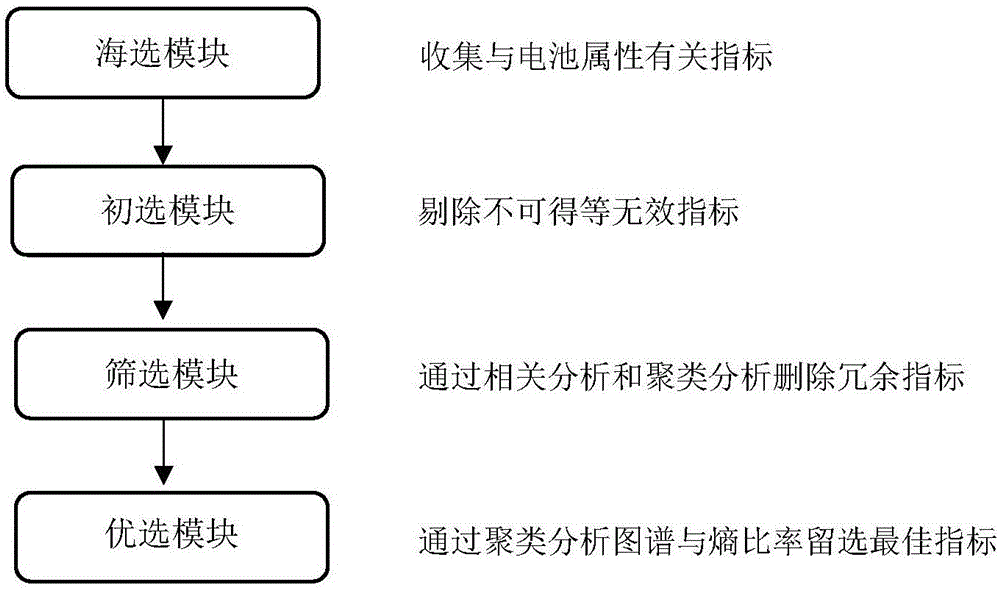
:近年来,我国政府为了实现节能减排、减少城市污染,加大了对电动汽车发展的扶持力度。动力电池是电动汽车的核心部件,随着时间的发展,将面临巨大的动力电池退役问题。电池组中由于生产工过程的复杂因素与使用环境的复杂因素共同作用,导致相同的电池单元在经过使用后,存在使用性能的劣化,且程度不同;甚至刚出厂的电池也会存在一定的性能差异,在长时间的使用过程中,其劣化程度会继续增加,电池组的综合性能所受影响极大。根据木桶效应理论,会极大地缩减电池组的使用寿命,劣化程度最大的电池反而会成为最大的负载,导致电池组提前报废。传统的做法是把不满足性能的电池组全部进行替换,将旧电池组进行物理、化学方法回收或者直接进入二级市场使用,即便是直接进入二级市场使用,仍然存在极大的浪费,性能完好的电池单元无法更进一步地发挥作用,裂化程度大的单体电池仍然是一个负载。电池的一致性评价贯穿始终,无论是从刚生产出来的新单体电池配组,还是废旧动力电池的梯次利用再分配;然而目前评价电池一致性的指标众多,电池性能所受影响因素的范围也较广泛。因此,如何选择评价电池一致性的指标成为了关键。技术实现要素:(一)解决的技术问题本发明要解决的技术问题是克服上述缺陷,提供一种基于聚类与熵比率的废旧动力电池一致性指标优选,提供了一套科学、开放、可行的系统优选方法,使得选择指标更有效、更简便,为提高电池利用率与循环使用奠定坚实的基础。(二)技术方案为解决上述问题,本发明所采用的技术方案是:基于聚类与熵比率的废旧动力电池一致性指标优选,其特征在于,所述方法包括:海选模块,任何与电池属性有关的指标均可纳入到备选指标库;初选模块,剔除数据不可得等无效指标;筛选模块,通过相关分析和聚类分析删除冗余信息量大于阈值的指标,计算各指标之间的相关系数,将相关系数大于阈值的指标进行归类,删除信息重叠指标;优选模块,计算熵比率,结合聚类分析的树状分类图谱与指标数量复杂度,最终留选显著性最高的指标。作为优选,海选模块的任何指标可以是电池的内在固有属性指标,也可以是测量指标,还可以是其衍生指标。作为优选,筛选模块显著性值为t统计量,该统计量服从n-2个自由度的t分布,概率界限可选择1%至5%。作为优选,筛选模块的阈值为0.9至1。作为优选,聚类分析的距离为相关系数距离。作为优选,聚类分析的距离为欧式距离。作为优选,优选模块的显著性可以使用敏感因子,即信息熵与平均熵之差比最大熵来判别z=ln(m),(3)式中,pi为离散型系统状态的概率,i为系统状态数,m为系统状态最大值,且定义当概率为0时,熵为零;h为指标的信息熵值;为平均熵;z为最大熵;d为敏感因子,即信息熵与平均熵之差比最大熵。作为优选,优选模块复杂度可以根据人为经验与需求留选指标,应在聚类分析图谱中,由大类到小类进行分类,在每个类别中均衡选择指标,分类的数量可以人为决策。作为优选,优选模块复杂度指标的数量,是对筛选指标进行主成分分析,为特征根大于1时的主成分个数。(三)有益效果本发明提供了一种基于聚类与熵比率的废旧动力电池一致性指标优选,与现有技术相比,具备以下有益效果:本发明设计合理,开放式选择指标,进一步扩大指标的选择范围,提高指标选择代表性,为得到更包容、更广泛的电池一致性指标打好基础。经过一系列的相关分析、聚类分析、显著性分析,进一步优化指标的选择、量化选择标准,避免了以往指标筛选中的信息重叠与共线性,更均衡地选择指标,使得留选指标冗余信息更少,减少测度系统的复杂程度与盲目性;同时,将指标的选择过程完全可视化,黑箱过程透明化,使得优选过程更加明确、更加科学;为提高电池利用率与循环使用率奠定坚实的基础坚实的基础。附图说明图1指标选择流程图图2筛选指标聚类树状图谱、相关系数与熵比率图具体实施方式对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。选取了24样本,共搜集到了10个潜在指标。海选模块:搜集得到10个指标,得到10x24阶矩阵;初选模块:考虑到信息搜集的可得性、连续性,同时也考虑到指标的客观性,剔除数据不可得等无效指标后,保留了7个指标,荷电状态soc、功率状态sop、健康状态soh、端电压u、电压u0、内阻r和温度t,得到一个7x24阶的原始矩阵,如表1所示;筛选模块:计算7个指标的相关系数及伴随概率,可以使用spss软件计算得到相关系数表,如表2所示,其中u与u0两个指标相关系数为1,可以归为一类,两个指标为完全相关,信息完全重叠。为删除冗余信息量大于阈值的指标,通过相关聚类分析,得到系统树状图谱,根据图谱明确了7个指标的亲疏关系,如图2。筛选模块的相关系数阈值选为1,剔除冗余信息最大的指标,并将相关系数标记在7指标聚类图谱中,如图2所示相关系数列。需要说明的是,相关系数为1,意味着其地位相同,可以相互代表,只需留选1个指标。7个指标中,有1个相关系数为1,故缩减为6个指标。为了更好地说明本技术方案,在下一步仍然按照7个指标进行计算分析。优选模块:计算7个待选指标的熵比率值z=ln(m),(3)式中,pi为离散型系统状态的概率,i为系统状态数,m为系统状态最大值,且定义当概率为0时,熵为零;h为指标的信息熵值;为平均熵;z为最大熵;d为敏感因子,即信息熵与平均熵之差比最大熵。平均熵、最大熵的大小只与系统状态的最大值有关,且与其它指标的信息熵大小没有关系。针对本发明的开放式指标选择方法,无疑是最佳选择。无论有多少个待选指标进入指标库,都不会影响信息含量特征的识别。信息熵与平均熵作差之后,再除以最大熵,可以明显得出信息增量的百分比,进而使得指标系统的横向对比性能提升。因此,信息熵与平均熵之差比最大熵作为优选模块的显著性判别是切实可行的。将熵比率标记在7个待选指标中,图2。熵比率越大,则说明指标的信息含量越大,具有更显著的信息特征,具有更强的代表性。通过聚类分析图谱结合熵比率,在所分的大类中,选择熵比率最大的指标作为留选指标。留选个数可以结合经验与复杂程度确定。事实上,可以将7个指标分为2类、3类、4类甚至7类。留选指标个数越多,描述的精确度会相应增加,且符合边际递减效应,但系统复杂度也会相应提升。对筛选指标进行主成分分析,计算特征根大于1时的主成分个数,结果如表3,特征根大于1的主成分共有3个,为了进一步提升精确度,结合人为经验,把接近于1的第4个主成分也统计进去,因此,本文按照分4大类举例说明。如图2聚类图谱右半部分所示,从右至左,类别数量逐渐增多,虚线与图谱交点数量逐渐增多,其中,交点数量即为分类数量。本文按照分4大类举例说明,为了使表述更加清晰,在图2中,已经作出1条分类虚线。若将7个指标分为4大类,则可按图2中最右侧虚线分为共4类。表1序号socuu0soprtsoh10.47472.89593.76467100.11290.010223.8420.794920.64992.9153.7895100.440.009724.40.802430.40142.89123.75856100.10170.009924.71410.802540.7952.93623.81706102.78730.010624.59520.800750.47192.88763.7538898.83330.01124.62410.793960.96182.97733.8704998.14570.009824.32690.787870.3842.88493.7503798.85930.010324.54320.803280.63982.91273.7865198.90670.009824.00840.786690.29582.86993.7308799.56640.010224.2720.7897100.45532.89223.7598699.83150.010424.25440.8133110.48132.90443.7757299.78150.009424.65590.7958120.68032.91343.78742100.54130.010324.49580.7986130.78842.93453.81485100.38930.010624.15330.809140.66012.91233.78599100.75120.010124.49710.797150.52542.88463.74998101.77830.011724.29310.8103160.76312.943.822101.22310.009424.30.7965170.75982.94023.8222698.71670.009324.75920.8101180.6242.9263.803897.6710.008324.5340.8063190.71422.91373.78781100.90190.010924.61950.7979200.68262.90783.7801498.16440.010924.76520.7913210.40262.89143.75882100.06680.009924.55410.7896220.75192.92223.79886100.03550.010924.66530.7973230.46862.89533.76389102.22720.010224.70490.7956240.47922.89523.7637699.93080.010324.85120.7959表3主成分特征根方差贡献率%累积贡献率%13.0343.27943.27921.38619.79863.07731.0314.71477.79140.93613.37491.16550.5868.36599.52960.0330.471100700100表2**.在.01水平(双侧)上显著相关。在各类中,分别选择熵比率最大的指标作为留选指标。如在第1类的3个指标中,应选择熵比率最大的“soc”作为此类留选指标。在第2类的2个指标中,应选择熵比率最大的“sop”作为此类留选指标。在第3类的1个指标中,应选择“soh”作为此类留选指标。在第4类的1个指标中,应选择“t”作为此类留选指标。最终,在分4类的情形下,可以得到4个主要指标通过对7个指标进行主成分分析,可以知道前4个主成分的累计贡献率为91.1%超过了85%的一般水平,将上述7个指标分成4大类是合理的。同时,可知6个主成分指标增加到7个主成分指标时,累计贡献率还是100%,增加的这1个指标没有作用,也间接印证了筛选模块中两个指标完全相关的信息重叠性。事实上,随着图2中的虚线从右向左移动,类别数逐渐增加,综合评价一致性越准确,但是指标系统复杂度增加,可以根据实际需求来确定指标的数量,寻求信息成本的时间效率与能量利用率的平衡。综上所述,建立了废旧动力电池一致性指标的优选方法,使得指标筛选更规范合理;开放式系统,提高了筛选范围,使得指标更具有代表性;经过一系列相关分析、聚类分析、显著性分析的系统量化分析,使得筛选更科学,同时,过程完全可视化,为人为决策提供依据;为提高电池利用率与循环使用率奠定坚实的基础。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1