基于TOF相机的头发分割方法与流程
本发明涉及三维图像领域,具体地说是一种反向利用噪声的基于tof相机的头发分割方法。
背景技术:
目前,对于头发分割方法都不是很鲁棒,主要是由于基于rgb图像的分割方法受到光照以及背景的影响非常剧烈,传统基于图像的分割方法并不能很好地完成这个任务,特别是针对高清图像的头发分割一直以来是一个非常困难的问题。
随着人工智能时代的到来,人们开始尝试使用深度学习的方法来对头发进行分割。但是一个非常显而易见的问题是,目前对于头发的数据集少之又少。主要原因是不同人的头发千变万化,而且边界非常不光滑,这样对数据标注产生了非常大的困难。在数据集标注非常艰难而且不精确的前提下,简单利用深度学习的方法并不能非常好地实现对头发的分割。
tof(timeofflight)相机的工作原理是通过给目标连续发送光脉冲,然后用传感器接收从物体返回的光,通过探测光脉冲的飞行往返时间来得到目标的距离,从而最终得到整幅图像的深度信息。然而,如果利用tof相机直接拍摄头部毛发,会发现得到的深度图像会有很多噪声,其主要原因在于毛发从一个方向看上去深度不一致导致光脉冲返回的时间不完全相同。头发越是参差不齐,得到的深度图噪声就越严重;在一般情况下,头发部分得到的深度图的噪声要远远大于面部以及背景部分。
一般情况下,用tof相机拍摄头发部分会得到很大一部分噪声。噪声意味着深度图像的变换不连续、边缘不清晰,是一个十分有害的东西。但是在我们这种情况下,仅仅拍摄头部所得到的噪声边缘十分锋利,但是头发部分的深度的高低起伏十分明显。故可以反向利用这种看似有害处、需要做平滑处理的噪声信息,通过噪声来确定头发的大概位置概率。
技术实现要素:
本发明为解决现有的问题,旨在提供一种基于tof相机的头发分割方法。
为了达到上述目的,本发明采用的技术方案包括:包括:
步骤一,基于头发彩色图及其掩膜的数据集,建立深度学习网络;
步骤二,利用tof相机得到深度图,并获取对应的方差图;
步骤三,对深度学习得到的初步头发掩膜进行优化,得到优化后的头发掩膜;步骤四,利用方差图对优化后的头发掩膜做再次优化,得到最终的精确头发掩膜。
步骤一中,对数据集中的头发加入噪声、改变亮度饱和度,得到训练数据;然后构建编码-解码的深度学习网络,结合图像的梯度信息,训练训练拟合,最终得到较为精确的头发分割结果。
步骤二中,对于每一个像素点,都有一个以这个像素点为中心的小块设置一个阈值,对于小块中像素点与中心像素点的差值在阈值范围以内的像素点求取方差,最终得到方差图,公式如下:
步骤三中,利用像素点之间的距离信息、颜色信息以及方差信息,结合利用densecrf模型的方法对初步头发掩膜进行优化,得到优化后的头发掩膜:
和现有技术相比,本发明巧妙地反向利用飞行时间在头发上产生一定程度噪声的这一特性,结合方差图对头发掩膜进行两次优化,实现了对毛发的更高精度分割;利用像素点之间的距离信息、颜色信息以及方差信息来对头发的掩膜做优化,得到掩膜的质量较高。
附图说明
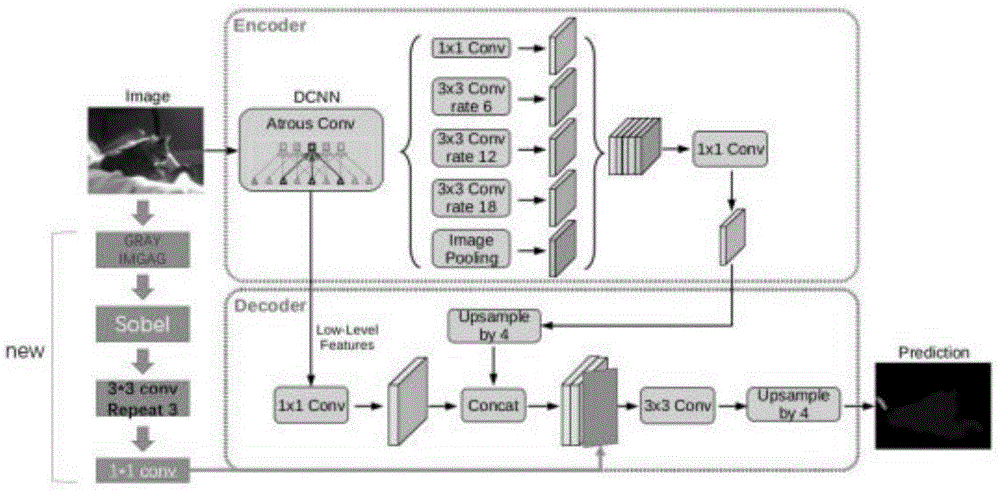
图1为所构建深度学习网络的示意图;
图2为本发明的一个实施例的流程图。
具体实施方式
现结合附图对本发明作进一步地说明。
参见图1、图2,图1、图2展示的是本发明的一个实施例,本实施例基于tof相机实现对人体头发的更高精度分割,反向利用飞行时间在头发上产生一定程度噪声的这一特性,实现对毛发的更高精度分割。
首先,深度学习实现对头发的初步分割。
即利用现存的少量且并不非常精细的头发彩色图加掩膜的数据集,构建头发风格的深度学习网络,并且整合加入头发梯度这一重要信息,训练得到初步的头发分割图。
参见图1,本实施例使用figaro1k头发数据集,该数据集有1050张头发数据。对所述数据集进行数据增强,对头发加入噪声、改变亮度饱和度等操作,最终得到约1万张训练数据。然后构建编码-解码(encoder-decoder)的深度学习网络,结合图像的梯度信息,训练训练拟合,最终得到较为精确的头发分割结果。
其次,利用tof相机得到的深度图(depthmap),求取方差图处理。
参见图2,即对于每一个像素点,都有一个以这个像素点为中心的小块(patch)设置一个阈值(通过预处理可以得到);对于小块中像素点与中心像素点的差值在阈值范围以内的这些像素点求取方差,最终得到方差图。公式如下:
对于所有|di-dcenter|<threshold,其中n是di的数量。
再次,基于densecrf的方法对头发掩膜进行第一次优化。
传统的densecrf的方法主要是基于像素点之间的颜色信息以及像素点之间的位置信息进行图像的全局优化,使得边缘更加锋利。然而由于衣服等其他背景颜色和头发颜色相似,从而会得到一个非常差的结果。本实施例利用像素点之间的距离信息、颜色信息以及方差信息来对头发的掩膜做优化,能够得到一个较为不错的结果。
利用像素点之间的距离信息、颜色信息以及方差信息,结合利用densecrf模型的方法对深度学习得到的初步头发掩膜进行优化,得到优化后的头发掩膜:
公式如上。其中,x为输入图像的像素点的标签。ψu(xi)为一阶映射函数。ψp(xi,xj)为像素之间的相互联系映射。在ψp(xi,xj)中,μ(xi,xj)为μ(xi,xj)=[xi≠xj]。k(fi,fj)为关系函数,第一项为像素颜色值,像素位置,像素方差值之间的关系。第二项为平滑函数,主要依赖于像素位置之间的关系。
最后,利用上述的方差图对优化后的头发掩膜做第二次优化。
利用densecrf模型得到的优化结果会把眉毛眼睛等部分加入,其主要原因是眉毛眼睛的方差图以及彩色图的权重也同样十分高,所以不能有效排除位置。同时,由于考虑到了颜色信息,就很容易收到光照的影响。
头发原本的颜色基本都是黑色的,但是由于光照的影响使得头发有了很大一部分白的的部分,利用densecrf就会得到一个错误的结果。
但是,本实施例也必须要用到densecrf可以得到比较细节的边缘信息的这一个很大的优势。
所以,为了避免这些错误,须要单纯只利用方差图对得到的掩膜再做一次优化。通过上述公式可以了解到,由于多考虑了颜色信息,得到的掩膜相对于真正正确的掩膜要小,要基于方差来扩展这个掩膜,最终得到精确到头发掩膜。
具体的算法是,对上一个步骤计算得到的整个二值mask进行逐个像素点遍历。如果当前像素点确定为非掩膜区域,那么就对这个像素点以及周围4*4区域进行基于颜色和方差进行优化确认。如果周围有半数以上的像素点与中心像素点的颜色和方差相差不大,以及他们都确认为是掩膜部分,那么把测试的像素点更改为掩膜部分。如此进行一轮有一轮的优化迭代,直到掩膜区域不再发生改变。同时只保留联通区域最大的掩膜,去除那些联通区域比较小的部分。
上面结合附图及实施例描述了本发明的实施方式,实施例并不构成对本发明的限制,本领域内熟练的技术人员可依据需要做出调整,在所附权利要求的范围内做出各种变形或修改均在保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!