一种基于生成网络的图像超分辨率重构的方法与流程
本发明涉及gan网络和图像处理技术领域,尤其涉及一种基于生成网络的图像超分辨率重构的方法。
背景技术:
由于在现代社会中犯罪分子的违法行为越来越专业化、流窜化和动态化,通过视频监控在公安侦查中的发展应用和不断提高,公安机关民警就能通过视频监控所获取的大量信息进行分析研判。通过对案发现场摄像头所拍摄到的信息进行分析处理,迅速确定犯罪体貌特征和实施犯罪的整个作案过程,能直接锁定犯罪嫌疑人,有利于加快破案速度,大大减少破案成本。在发现可疑人员,通过摄像头的拉近,对可疑人员的体貌特征进行特写,但是由于视频监控设备的本身进度不够和监控摄像头距离目标比较远,导致我们获取得视频图像是低分辨率的。低分辨率图像是无法提供具体的细节信息。每当有情况发生时,可以采用超分辨率重建技术对监控图像进行放大处理,更加清楚的展现犯罪嫌疑人脸部的细节信息。提高了公安民警直接发现抓捕犯罪嫌疑人的能力,为城市安防提供了有利保障。
提高图像的分辨率主要分为两个方面。首先是采用高精度的硬件设备比如高质量的图像传感器和光学仪器。通过改进传感器或光学设备来减小成像的单元尺寸以增加图像的像素数。一定程度上缓解了人们对高分辨率的图像的需求。然而这种方法存在很多局限性,一方面随着传感器技术不断改进,感光单元的尺寸越来越小,而随着感光单元的逐渐变小,获取图像像素受散粒噪声的影响越来越大。另一方面,高精度的设备成本高,传感器设计的尖端技术往往掌握在少数几个发达国家。通过硬件提高图像的分辨率存在诸多限制,已经无法满足人们对图像的画质需求。其次从软件角度出发,通过一些算法对低分辨率图像进行重构得到高分辨率图像。此方法称为超分辨率图像重构。该方法只需要在现有低分辨率图像设备的基础上,运用相关图像处理原理和机器学习算法,通过重构一幅或者多幅低分辨率图像,获得一幅高分辨率图像。
生成式对抗网络(generativeadversarialnetwork,简称gan)是由goodfellow在2014年提出的深度学习框架,它基于“博奕论”的思想,构造生成器(generator)和判别器(discriminator)两种模型,前者通过输入(0,1)的均匀噪声或高斯随机噪声生成图像,后者对输入的图像进行判别,确定是来自数据集的图像还是由生成器产生的图像。
传统图像超分辨率重构算法主要分为三类:基于插值、基于多帧重构和基于学习的方法。近年来,随着深度学习兴起,越来越多的视觉领域都尝试运用深度学习算法。通过利用深度学习得到高低分辨率图像块之间的相似度,从而对于待处理的低分辨率图像块可以更为精确的生成与其对应的高分辨率图像块。克服了传统基于样本超分辨率算法中利用手工设计的特征难以学习到准确的高低分辨率图像块空间映射关系的问题。但的图像超分辨率重构未达到更优质的质量。
于2017.10.20公开的中国专利公开号第cn107273936号揭露了一种gan图像处理方法和系统,包括:接收随机噪声,利用基于改进的lsgan的生成式网络,生成生成图像;接收真实图像,对真实图像和生成图像分别进行不同度数的图像梯度变换,得到变换图像集;将变换图像集中的变换图像分别输入到判别网络的多通道卷积网络的各个通道中,进行特征的提取和融合,得到输出结果。本申请通过将随机噪声输入到生成式网络,得到生成图像,再接收真实图像,对真实图像和生成图像分别进行不同度数的图像梯度变化,得到变换图像集,将变换图像集中的变换图像分别输入到判别网络的多通道卷积网络的各个通道,进行特征的提取和融合,得到输出结果,使网络具有较好的泛化能力,避免梯度消失现象,能够输出质量更高更加真实的图像。但其图像真实性未能达到更佳状况。
技术实现要素:
针对现有技术中的缺陷,本发明涉及一种基于生成网络的图像超分辨率重构的方法及其系统,以获取更高质量的高清图像。
为实现上述目的,本发明提供一种基于生成网络的图像超分辨率重构的方法,其包括:
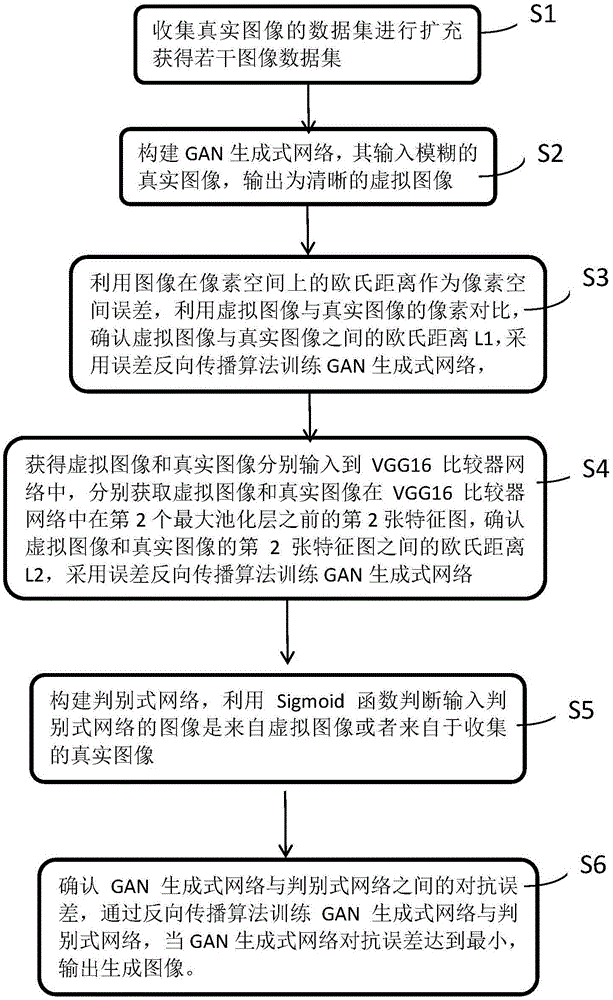
s1,收集真实图像的数据集进行扩充获得若干图像数据集;
s2,构建gan生成式网络,其输入模糊的真实图像,输出为清晰的虚拟图像;
s3,利用图像在像素空间上的欧氏距离作为像素空间误差,利用虚拟图像与真实图像的像素对比,确认虚拟图像与真实图像之间的欧氏距离l1,采用误差反向传播算法训练gan生成式网络,直至欧氏距离值l1达到最小;
s4,把s3获得虚拟图像和真实图像分别输入到vgg16比较器网络中,分别获取虚拟图像和真实图像在vgg16比较器网络中在第2个最大池化层之前的第2张特征图,确认虚拟图像和真实图像的第2张特征图之间的欧氏距离l2,采用误差反向传播算法训练gan生成式网络,直至欧氏距离l2值达到最小;
s5,构建判别式网络,利用sigmoid函数判断输入判别式网络的图像是来自虚拟图像或者来自于收集的真实图像;确认真实图像与虚拟图像之间的欧氏距离l3,
s6,确认gan生成式网络与判别式网络之间的对抗误差,通过反向传播算法训练gan生成式网络与判别式网络,当gan生成式网络对抗误差达到最小,输出生成图像。
具体的,s1步骤中,针对若干1真实图像依次旋转90度、180度、270度,将数据集扩展为原来的n倍,随机选出多数真实图像用作训练样本,将剩余少数真实图像用作测试样本。
具体的,上述s2步骤中,其步骤包括:s21步骤:将用作训练的地低分辨率真实图像提取过程,由三个大小为f11,f12,f13卷积核组成,设输入图像像素特征y,输出为图像像素特征f,经过三层卷积的表达式依次为:
f11(y)=max(0,w11*y+b11),
f12(y)=max(0,w12*f11(y)+b12),
f13(y)=max(0,w13*f12(y)+b13),
其中w11,w12,w13:b11,b12,b13,分别表示滤波器的权重和偏置,w11对应于尺寸为f11×f11的n11个滤波器的权值,w12对应于尺寸为f12×f12的n12个滤波器的权值,w13对应于尺寸为f13×f13的n13个滤波器的权值,且n11=n12=n13=n1,b11,b12,b13均为n1维矢量。
s22步骤:通过非线性映射层,将得到了n1维图像特征映射到n2维矢量上;相当于通过n2个滤波器分别和n1维图像特征卷积,获取n2维图像特征;非线性映射表达式为:
f21(y)=max(0,w21*f13(y)+b21),
f22(y)=max(0,w13*f21(y)+b22),
f23(y)=max(0,w23*f22(y)+b23),
其中w21,w22,w23:b21,b22,b23,分别表示滤波器的权重和偏置,w21对应于尺寸为f21×f21的n21个滤波器的权值,w22对应于尺寸为f22×f22的n22个滤波器的权值,w23对应于尺寸为f23×f23的n23个滤波器的权值,且n21=n22=n23=n2,b21,b22,b23均为n2维矢量;
s23步骤:图像重建是将s22步骤的高分辨率特征图像经一个重建滤波器卷积后得到清晰的虚拟图像;图像重建表示为:
g(y)=max(0,w3*f23(y)+b3)
w3对应于尺寸为f3×f3的1个滤波器,b3是一个标量。
具体的,上述s3步骤中,欧拉距离l1为通gan生成式网络生成虚拟图像gθ(yi)与真实图像xi之间的欧氏距离平方之和,表达式为:
其中,yi为第i张虚拟图像像素,xi为对应的真实图像像素,n为训练样本的总数,θ为gan生成式网络中的参数。
具体的,s4步骤中,由gan生成式网络生成的图像gθ(yi)和对应的真实图像xi输入到vgg16比较器网络中,获取中间层输出的特征图,获得两者之间的欧氏距离l2,表达式为:
其中,φ为图像所对应的特征图。
具体的,上述s5步骤中,通过leakyrelu激活函数将中间3层卷积层后接批标准化操作,将最后1层卷积层后接全连接层,经过全连接层后,再用sigmoid函数判断输入所述判别式网络的图像。
具体的,判别式网络的对抗误差的表达式如下:
其中,d表示判别网络中的参数,d表示判别网络,g表示gan生成式网络,e表示期望误差。
与现有技术相比,本发明的有益效果:本发明采用了采用示gan生成式网络将模糊的图像转为高清的图像,提供高质量的图像,将模糊的人脸图像转为了清晰的图像,加快工作效率。
附图说明
图1是本发明基于gan生成式网络的图像超分辨率重构的方法的工作流程图。
图2是本发明基于gan生成式网络的图像超分辨率重构系统框架图。
图3是本发明基于gan生成式网络的图像超分辨率重构系统生成虚拟图像的运行模型图。
图4是本发明基于gan生成式网络的图像超分辨率重构的方法的vgg16运行模型流程图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂。下面结合附图对本发明的具体实施方式做详细说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但是本发明能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况做类似改进,因此本发明不受下面公开的具体实施方式的现实。
如图1至图4所示,本发明为一种基于生成网络的图像超分辨率重构的方法,其步骤包括:
s1步骤:收集真实图像的数据集进行扩充获得若干图像数据集;针对若干1真实图像依次旋转90度、180度、270度,将数据集扩展为原来的n倍,随机选出多数真实图像用作训练样本,将剩余少数真实图像用作测试样本。
本实施例中,制作图像数据集,使用photoshop软件的模糊滤镜的方法将1000张图像依次旋转90度、180度、270度,将数据集扩充为原来的4倍,共4000张。随机选出3200图像作为训练样本,将剩余800张图像作为训练样本。
s2步骤:如图2所示,构建gan生成式网络,其输入模糊(低分辨率)的真实图像,输出为清晰的虚拟图像。
具体的,s21步骤,将用作训练的地低分辨率真实图像提取过程,由三个大小为f11,f12,f13卷积核组成,设输入图像像素特征(像素)y,输出为图像像素特征(像素)f,经过三层卷积的表达式依次为:
f11(y)=max(0,w11*y+b11),
f12(y)=max(0,w12*f11(y)+b12),
f13(y)=max(0,w13*f12(y)+b13),
其中w11,w12,w13:b11,b12,b13,分别表示滤波器的权重和偏置,w11对应于尺寸为f11×f11的n11个滤波器的权值,w12对应于尺寸为f12×f12的n12个滤波器的权值,w13对应于尺寸为f13×f13的n13个滤波器的权值,且n11=n12=n13=n1,b11,b12,b13均为n1维矢量。
s22步骤:通过非线性映射层,将得到了n1维图像特征映射到n2维矢量上;相当于通过n2个滤波器分别和n1维图像特征卷积,获取n2维图像特征;非线性映射表达式为:
f21(y)=max(0,w21*f13(y)+b21),
f22(y)=max(0,w13*f21(y)+b22),
f23(y)=max(0,w23*f22(y)+b23),
其中w21,w22,w23:b21,b22,b23,分别表示滤波器的权重和偏置,w21对应于尺寸为f21×f21的n21个滤波器的权值,w22对应于尺寸为f22×f22的n22个滤波器的权值,w23对应于尺寸为f23×f23的n23个滤波器的权值,且n21=n22=n23=n2,b21,b22,b23均为n2维矢量;
s23步骤:图像重建是将s22步骤的高分辨率特征图像经一个重建滤波器卷积后得到清晰的虚拟图像;图像重建表示为:
g(y)=max(0,w3*f23(y)+b3)
w3对应于尺寸为f3×f3的1个滤波器,b3是一个标量。
s3步骤:利用图像在像素空间上的欧氏距离作为像素空间误差,利用虚拟图像与真实图像的像素对比,确认虚拟图像与真实图像之间的欧氏距离l1,采用误差反向传播算法训练gan生成式网络,直至欧氏距离值l1达到最小。
具体的,采用误差反向传播算法,使用图像在像素空间上的欧氏距离l1作为误差:现有技术用均方误差(meansquarederror,mse)作为网络中的损失函数,本文采用mse作为网络的损失函数,欧拉距离l1为通gan生成式网络生成虚拟图像gθ(yi)与真实图像xi之间的欧氏距离平方之和,表达式为:
其中,yi为第i张虚拟图像像素,xi为对应的真实图像像素,n为训练样本的总数,θ为gan生成式网络中的参数。
s4步骤:把s3步骤获得虚拟图像和真实图像分别输入到vgg16比较器网络中,分别获取虚拟图像和真实图像在vgg16比较器网络中在第2个最大池化层之前的第2张特征图,确认虚拟图像和真实图像的第2张特征图之间的欧氏距离l2,作为特征空间上的误差,采用误差反向传播算法训练gan生成式网络,直至欧氏距离l2值达到最小。具体的,由gan生成式网络生成的图像gθ(yi)和对应的真实图像xi输入到vgg16比较器网络中,获取中间层输出的特征图,获得两者之间的欧氏距离l2,表达式为:
其中,φ为图像所对应的特征图。
s5步骤,如图3,构建判别式网络,利用sigmoid函数判断输入判别式网络的图像是来自虚拟图像或者来自于收集的真实图像;确认真实图像与虚拟图像之间的欧氏距离l3;
具体的,通过leakyrelu激活函数将中间3层卷积层后接批标准化操作,将最后1层卷积层后接全连接层,经过全连接层后,再用sigmoid函数判断输入所述判别式网络的图像。如果输入判别器的图像为真实图像,输出为“1”,若是生成器生成的虚拟图像,则输出为“0”。卷积层1大小为4x4,步长为2,卷积核个数为64,卷积层2大小为4x4,步长为2,卷积核个数为128,卷积层3大小为4x4,步长为2,卷积核个数为256,卷积层4大小为4x4,步长为2,卷积核个数为512,卷积层5大小为4x4,步长为2,卷积核个数为1。
s6步骤,确认gan生成式网络与判别式网络之间的对抗误差,通过反向传播算法训练gan生成式网络与判别式网络,当gan生成式网络对抗误差达到最小,输出生成图像。
具体的,以gan生成式网络与判别式网络之间的对抗误差作为新的误差,
s61步骤,每轮训练先固定gan生成式网络参数,训练判别式网络,例如:每批输入n张生成清晰虚拟图像作为负样本,n张清晰真实图像作为正样本,采用误差反向传播算法,训练gan生成式网络;
s62步骤,固定判别式网络参数,训练gan生成式网络,加入判别式网络所带来的对抗误差到生成式网络的总体误差之中,采用反向传播的方法训练gan生成式网络;
s63步骤,重复s61和s62两个步骤共n轮。
其中,总体误差,具体计算方法如下:
对于判别式网络,输入为真实图像或者生成虚拟图像,训练目标为:当输入为真实图像时,网络输出为1;当输入为生成虚拟图像时,网络输出为0。因此对抗误差的表达式如下:
其中,d表示判别网络中的参数,d表示判别网络,g表示gan生成式网络,e表示期望误差。对于生成式网络g希望上式的值越小越好,则表生gan生成式网络所生成的图像与真实的清晰图像更加接近;对于判别式网络d希望上式的值越大越好,则表示判别式网络能更准确地分辨生成的图像和真实的图像。
本发明提出了一种基于深度学习的生成网络人脸图像超分辨率重构方法提供高质量的图像,将模糊的人脸图像转为了清晰的图像,加快工作效率。
基于srgan人脸图像超分辨率工作原理:生成网络通过低分辨率的图像生成高分辨率图像,由判别网络判断拿到的图像是由生成网络生成的,还是数据库中的原图像。当生成网络能成功骗过判别网络的时候,那我们就可以通过这个生成对抗完成超分辨率了。
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人是能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡如本发明精神实质所做的等效变换或修饰,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!