一种基于知识图谱的文学编年史问答系统的构建方法与流程
本发明涉及问答系统,尤其涉及一种基于知识图谱的文学编年史问答系统的构建方法。
背景技术:
问答系统是信息检索系统的一种高级形式,它能回答用户用自然语言提出的问题;问答系统能够满足用户对快速、准确地获取信息的需求;不同于现有的搜索引擎,问答系统返回用户的不再是基于关键词匹配的相关文档排序,而是精准的自然语言形式的答案;问答系统可分为基于阅读理解的问答系统、基于社区问答对的问答系统以及基于知识图谱的问答系统;
知识图谱多是以实体、关系为基本单元所组成的图结构;基于这样的结构化的知识,分析用户自然语言问题的语义,进而在已构建的结构化知识图谱中通过检索、匹配或推理等手段,获取正确答案,这一任务称之为知识库问答(questionansweringoverknowledgebase,kbqa);这一问答范式由于已经在数据层面通过知识图谱的构建对于文本内容进行了深度挖掘与理解,能够有效地提升问答的准确性;知识库问答系统在回答用户问题时,需要正确理解用户所提的自然语言问题,抽取其中的关键语义信息,然后在已有单个或多个知识库中通过检索、推理等手段获取答案并返回给用户;知识库问答所涉及的技术包括:词法分析、句法分析、语义分析、信息检索、逻辑推理、语言生成等;按照问答领域划分,知识库问答又可分为限定领域的知识库问答和开放域的知识库问答;
知识图谱的构建涉及到本体建模,也称为数据建模;本体建模分为自顶向下和自底向上两种方式;开放域知识图谱的本体构建通常用自底向上的方法,自动地从知识图谱中抽取概念、概念层次和概念之间的关系;领域知识图谱多采用自顶向下的方法来构建本体;一方面,相对于开放域知识图谱,领域知识图谱涉及的概念和范围都是固定或者可控的;另一方面,对于领域知识图谱,我们要求其满足较高的精度,通常依靠领域专家通过自顶向下的方式来构建本体。
语义解析是问答系统的一个关键技术问题;知识库问答要回答用户的问题,首先就要正确理解用户所提问题的语义内容;面对结构化知识库,需要将用户问题转化为结构化的查询语句,进而在知识图谱进行查询、推理等操作,获取正确答案;因此,对于用户问题的语义解析是知识库问答研究所面临的首要科学问题。具体过程需要分析用户问题中的语义单元与知识图谱中的实体、概念进行链接,并分析问句中这些语义单元之间的语义关系,将用户问题解析成为知识图谱中所定义的实体、概念、关系所组成的结构化语义表示形式。
技术实现要素:
本发明的目的是为了解决现有文学编年史知识获取系统效率过低等缺点,而实现的一种基于知识图谱的文学编年史问答系统。
为了实现上诉目的,本发明采用了如下技术方案:
基于知识图谱的文学编年史问答系统的构建方法包括如下步骤:
1)预处理数据:设计关系型数据库er图,获取文学编年史相关的结构化数据,转存数据于自定义schema数据库中;
2)本体建模:根据文学编年史涉及的概念、实体,自上而下构建垂直领域的本体结构;
3)数据格式转换:利用创建的本体,创建映射文件;将关系型数据库中的结构化数据转为rdf格式;
4)数据存储及查询服务:利用第三方开源软件存储rdf数据,并启用sparql查询终端提供接口;
5)语义解析:通过基于正则与规则的方法对用户查询进行语义解析,若解析失败,则采用基于神经网络的方法解析用户查询;
6)sparql查询:根据语义解析的结果构建sparql查询,对知识图谱进行搜索得到相应结果返回用户;
7)日志反馈收集:收集用户使用日志和用户反馈用于定位失败的案例,改进系统功能;将日志作为标注数据,迭代训练神经网络模型,提升泛化性能。
优选的,所述的预处理数据,具体步骤为:
2.1设计关系型数据库er图
er图主要包括人物表格、地点表格、作品表格和职位表格;er图也包含了表格之间的关系,主要包含人物之间的亲属关系、人物之间的非亲属关系、人物与地点之间的关系、人物与作品的关系;
2.2结构化数据获取
收集结构化数据,对数据进行去重,繁简转化操作;将数据导入已设计好schema的mysql数据库中。
优选的,所述的本体建模,具体步骤为:
利用开源的本体编辑软件protégé设计本体结构;结合mysql数据库的表结构,自上而下地构建文学编年史垂直领域本体结构;设定属性的domain和range;指定属性的特性,用于知识的推理。
优选的,所述的数据格式转换,具体步骤为:
4.1创建映射文件
采用第三方开源软件d2rq的数据映射配置规范;撰写配置文件,将mysql数据库的表映射到本体结构对应的类别下;其次,针对该表的每个字段,编写映射代码将其映射到本体结构中对应的属性;对数据库的每个表结构执行上述相同的操作流程;
4.2数据转换
借用d2rq提供的转换工具dump-rdf,结合所撰写的配置文件,将mysql中的结构化数据转换为rdf格式的数据。
优选的,所述的数据存储及查询服务,具体步骤为:
5.1数据存储
采用开源的java语义网和链接数据框架jena作为rdf数据存储和查询的后端;利用jena提供的原生高性能三元组存储组件tdb持久化rdf数据;使用jena提供的命令行工具tdbloader为rdf数据建立索引和存储;
5.2查询服务
利用jena提供的fuseki组件来查询rdf数据;将构建的本体文件放置在fuseki服务对应的配置文件目录下;通过脚本fuseki-server启动fuseki服务。
优选的,所述的基于正则与规则的方法具体为:
将用户查询中的每个词作为一个对象;该对象拥有两个基本属性:词汇与词性;利用开源工具refo定义匹配规则;当拥有特定词汇或词性的组合出现时,一条规则匹配成功,执行预设的函数;针对每条用户查询,首先利用开源分词工具jieba对用户查询进行分词和词性标注,得到一个对象列表;其次与预定义的规则逐一匹配;匹配成功,则执行对应的函数;匹配失败,则采用基于神经网络的方法;
所述的基于神经网络的方法具体为:
将用户查询语义解析分解为两个子问题:命名实体识别与短文本分类;采用bilstm+crf网络结构来解决命名实体识别问题;lstm每个单元的具体实现如下:
it=σ(wxixt+whiht-1+bi)
ft=σ(wxfxt+whfht-1+bf)
ot=σ(wxoxt+whoht-1+bo)
ct=ftct-1+ittanh(wxcxt+whcht-1+bc)
ht=ottanh(ct)
其中σ代表sigmoid函数;it,ft,ot,ct分别代表t时刻的输入门、遗忘门、输出门和记忆单元,大小与隐藏单元一致;wxi、wxf、wxo、wxc分别代表任一时刻输入门、遗忘门、输出门和记忆单元关于输入的参数;whi、whf、who、whc分别代表任一时刻输入门、遗忘门、输出门和记忆单元关于隐藏单元的参数;bi、bf、bo、bc分别代表任一时刻输入门、遗忘门、输出门和记忆单元的偏置;xt代表当前时刻的输入;ht-1代表上一个时刻的隐藏单元;利用双向lstm结构获取当前时刻之前和之后的特征;经过lstm抽取的特征作为crf模型的输入,解码得到当前时刻字符的标签;
采用textcnn模型进行短文本分类;用户查询作为模型的输入,查询对应的属性作为输出;假设
一个卷积操作的卷积核大小为
ci=f(w·xi:i+h-1+b)
其中ci是每次卷积操作得到的特征,f是一种非线性函数;该卷积应用于所有的查询子序列{x1:h,x2:h+1,……,xn-h+1:n},最后得到如下特征图:
c=[c1,c2,……,cn-h+1]
其中c是长度为n-h+1的向量,即
采用卷积核大小分别为3,4,5的卷积核各100个,将每个卷积核得到的特征值进行拼接,最终得到一个长度为300的特征向量;对该特征向量进行全接连操作,加上softmax函数求得每个属性的概率。
优选的,所述的sparql查询,具体步骤为:
7.1构建sparql查询
若步骤5)中采用基于正则和规则的方法进行语义解析,则为每一条规则构造对应的sparql查询模板;当用户查询与某条规则匹配时,将匹配的实体和属性填入到相应的sparql模板当中;
若步骤5)中采用基于神经网络的方法进行语义解析,则本发明结合bilstm+crf模型识别的实体名和textcnn模型得到的属性类别构造sparql查询;在sparql查询中加入了筛选机制解决实体重名的情况:优先返回属性更多的实体所对应的结果;
7.2搜索返回结果
通过第三方库sparqlwrapper向fuseki终端发送查询请求;解析返回的查询结果;若存在多个答案,将其进行拼接;将最终答案返回给用户;若语义解析失败或者查询返回结果为空,随机选取一条预定义的回答返回给用户。
优选的,所述的日志反馈收集,具体步骤为:
8.1日志反馈收集
利用mongodb数据库存储用户使用日志;根据语义解析返回的处理状态,将使用日志分别存储在表示查询成功、无对应结果、解析失败三个表中;将用户反馈的查询存入表示结果错误的表中;
8.2模型迭代训练
表示查询成功的表所存储的数据作为正确的标注数据;存储的字段包含用户id、用户查询、解析的sparql语句、答案、解析方式、查询包含的实体、查询所指属性;设定阈值,每当新增的数据超过该阈值则重新训练bilstm+crf与textcnn两个神经网络模型。
本发明还可以服务器后端开发、网页端开发和微信公众号服务开发的步骤,具体为:
9.1服务器后端开发
服务器后端基于web.py框架进行开发,同时为网页端和微信公众号服务提供支持;整合了获取用户请求,处理用户请求,返回处理结果的功能;实现收集用户反馈和使用日志的功能;
9.2网页端开发
前端界面的开发基于html5、css和javascript;前端界面的控件主要包括:查询输入框、查询提交框、答案呈现框、反馈按钮、反馈弹窗以及系统使用说明浮窗;
9.3微信公众号服务开发
实现解析微信转发的用户请求,处理用户文字请求,包装系统回复为微信指定格式的功能。
本发明系统与现有系统相比具有以下效果:
1.该系统基于文学编年史知识图谱,可以返回用户更精准的回答,提升用户获取特定知识的效率;搜索引擎返回相关问题的排序文档,用户为了获得目标信息,需要在文档中做进一步的信息筛选;该系统基于知识图谱所建模的结构化知识,能够直接返回用户查询的信息,不需要用户做后续的信息过滤操作。
2.该系统结合了两种语义解析方法,提升了系统语义解析的泛化性,能够更准确地解析用户查询的语义;具体而言,基于正则和规则的方法主要考虑了系统的准确性,由于本系统处理的是文学编年史领域的问题,我们能够对常见的用户问题做一定的收集和归纳;成功解析此类问题,则可以覆盖大部分用户提问;对于规则之外的问题,该系统利用基于神经网络的方法,所训练的模型具有一定泛化性,能够覆盖一些少见的问题。
3.该系统基于收集的用户使用日志和反馈信息可以迭代地训练神经网络语义解析模型,能够进一步提升模型的泛化性能;具体而言,用户的每一次查询都将记录在日志反馈收集模块中;假若用户没有反馈错误,我们可以认定系统给出了正确的答案;将这些数据作为标注数据,训练基于神经网络的模型,可以提升模型的泛化能力。
4.该系统具有一定的推理能力,有助于文学编年史领域的研究;比如,知识图谱中存在这样的数据:<苏迈,父亲,苏轼>,<苏轼,父亲,苏洵>,同时存在这样的规则:“父亲的父亲是爷爷”;该系统所构建的本体即可用于此类知识的推理;即使知识图谱中没有<苏迈,爷爷,苏洵>这样的知识,系统也可以通过推理得到该知识;该特性能够节省总结知识的时间,加速相关学者在此领域的研究。
附图说明
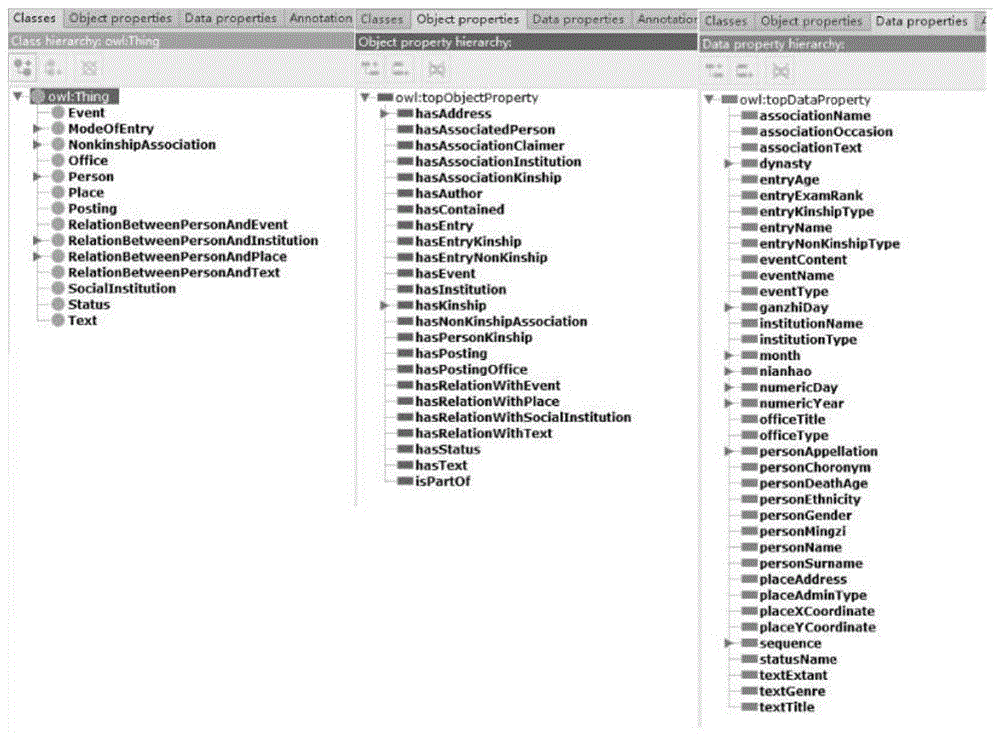
图1是本发明的文学编年史本体结构图;
图2是本发明的问答系统架构图;
图3是本发明的问答系统流程图;
图4是本发明的问答系统网页端界面;
图5是本发明的问答系统微信公众号界面。
具体实施方式
依据图1-5,本发明的具体实施步骤如下:
1)预处理数据:设计关系型数据库er图,获取文学编年史相关的结构化数据,转存数据于自定义schema数据库中;
2)本体建模:根据文学编年史涉及的概念、实体,自上而下构建垂直领域的本体结构;
3)数据格式转换:利用创建的本体,创建映射文件;将关系型数据库中的结构化数据转为rdf格式;
4)数据存储及查询服务:利用第三方开源软件存储rdf数据,并启用sparql查询终端提供接口;
5)语义解析:通过基于正则与规则的方法对用户查询进行语义解析,若解析失败,则采用基于神经网络的方法解析用户查询;
6)sparql查询:根据语义解析的结果构建sparql查询,对知识图谱进行搜索得到相应结果返回用户;
7)日志反馈收集:收集用户使用日志和用户反馈用于定位失败的案例,改进系统功能;将日志作为标注数据,迭代训练神经网络模型,提升泛化性能。
所述步骤1)为:
2.1设计关系型数据库er图
er图中独立概念表格主要包括人物、地点、作品、职位;er图也包含了独立概念之间的关系,包含人物之间的非亲属关系、人物与之间之间的关系、人物与作品的关系等;总计20个表格;
2.2结构化数据获取
利用哈佛大学开源的中国历代人物传记数据库(thechinabiographicaldatabase,cbdb)作为知识图谱的数据源,其收录了422,600人的传记资料,这些人主要出自七世纪至十九世纪,数据用sqlite数据库存储;对数据进行去重,繁简转化等操作;根据cbdb提供的表结构说明,将数据导入已设计好的mysql数据库中。
所述步骤2)为:
利用开源的本体编辑软件protégé设计本体结构;结合mysql数据库的表结构,共创建14个主类,24个主对象属性,39个主数据属性;设定属性的domain和range;指定属性的特性,如:相反关系,用于知识的推理。
所述步骤3)为:
4.1创建映射文件
本发明采用第三方开源软件d2rq的数据映射配置规范;撰写配置文件,将mysql数据库的表映射到本体结构对应的类别下;其次,针对该表的每个字段,编写映射代码将其映射到本体结构中对应的属性;对数据库的每个表结构执行上述相同的操作流程;
4.2数据转换
借用d2rq提供的转换工具dump-rdf,结合所撰写的配置文件,将mysql中的结构化数据转换为rdf格式的数据。
所述步骤4)为:
5.1数据存储
本发明采用免费开源的java语义网和链接数据框架jena作为rdf数据存储和查询的后端;利用jena提供的原生高性能三元组存储组件tdb持久化rdf数据;使用jena提供的命令行工具tdbloader为rdf数据建立索引和存储。
5.2查询服务
利用jena提供的fuseki组件来查询rdf数据;将构建的本体文件放置在fuseki服务对应的配置文件目录下;通过脚本fuseki-server启动fuseki服务。
所述步骤5)为:
6.1基于正则与规则的方法
此方法将用户查询中的每个词作为一个对象;该对象拥有两个基本属性:词汇与词性;利用开源工具refo定义一系列匹配规则;当拥有特定词汇或词性的组合出现时,一条规则匹配成功,执行预设的函数;针对每条用户查询,首先利用开源分词工具jieba对用户查询进行分词和词性标注,得到一个对象列表;其次与预定义的规则逐一匹配;匹配成功,则执行对应的函数;匹配失败,则失败错误代码;
6.2基于神经网络的方法
此方法将用户查询语义解析分解为两个子问题:命名实体识别与短文本分类;本发明采用bilstm+crf网络结构来解决命名实体识别问题;lstm每个单元的具体实现如下:
it=σ(wxixt+whiht-1+bi)
ft=σ(wxfxt+whfht-1+bf)
ot=σ(wxoxt+whoht-1+bo)
ct=ftct-1+ittanh(wxcxt+whcht-1+bc)
ht=ottanh(ct)
其中σ代表sigmoid函数;i,f,o,c分别代表输入门、遗忘门、输出门和记忆单元,大小与隐藏单元一致;带下标的w与b是每个门对应的参数;xt代表当前时刻的输入;ht-1代表上一个时刻的隐藏单元;利用双向lstm结构获取当前时刻之前和之后的特征;经过lstm抽取的特征作为crf模型的输入,解码得到当前时刻字符的标签;
本发明采用textcnn模型进行短文本分类;用户查询作为模型的输入,查询对应的属性作为输出;假设
一个卷积操作的卷积核大小为
ci=f(w·xi:i+h-1+b)
其中ci是每次卷积操作得到的特征,f是一种非线性函数;该卷积应用于一系列可能的查询子序列{x1:h,x2:h+1,……,xn-h+1:n},最后得到如下特征图:
c=[c1,c2,……,cn-h+1]
其中c是长度为n-h+1的向量,即
采用卷积核大小分别为3,4,5的卷积核各100个,将每个卷积核得到的特征值进行拼接,最终得到一个长度为300的特征向量;对该特征向量进行全接连操作,加上softmax函数求得每个属性的概率。
所述步骤6)为:
7.1构建sparql查询
针对基于正则和规则的方法,本发明为每一条规则构造对应的sparql查询模板;当用户查询与某条规则匹配时,将匹配的实体和属性填入到相应的sparql模板当中;针对基于神经网络的方法,本发明结合bilstm+crf模型识别的实体名和textcnn模型得到的属性类别构造sparql查询;在sparql查询中加入了简单的筛选机制解决实体重名的情况:优先返回属性更多的实体所对应的结果;
7.2搜索返回结果
通过第三方库sparqlwrapper向fuseki终端发送查询请求;解析返回的查询结果;若存在多个答案,将其进行拼接;将最终答案返回给用户;若语义解析失败或者查询返回结果为空,随机选取一条预定义的回答返回给用户。
所述步骤7)为:
8.1日志反馈收集
利用mongodb数据库存储用户使用日志;根据语义解析返回的处理状态,将使用日志分别存储在表示查询成功、无对应结果、解析失败三个表中;将用户反馈的查询存入表示结果错误的表中;
8.2模型迭代训练
表示查询成功的表所存储的数据作为正确的标注数据;存储的字段包含用户id、用户查询、解析的sparql语句、答案、解析方式、查询包含的实体、查询所指属性;设定阈值,每当新增的数据超过该阈值则重新训练bilstm+crf与textcnn两个神经网络模型。
实施例
下面结合本技术的方法详细说明实施该实例的具体步骤,如下:
1.根据问答系统涉及的领域设计关系型数据库mysql的er图;er图包含了人物、地点、作品、职位、人物之间非亲属关系、人物与地点关系、人物和作品关系、人物和除授关系等20个表;人物表包含了id、人名、姓氏、名字、性别、过世年龄、民族、郡望、朝代、出生年份、去世年份、出生月份、去世月份、出生日、过世日等27个字段;对中国历代人物传记数据库(cbdb)中的结构化数据进行筛选、清理、繁简转化等操作;将整理的数据一一对应导入到已创建好schema的mysql数据库中。
2.根据问答系统涉及的领域和已创建好的er图,利用开源软件protégé建立文学编年史本体结构;该本体包含人物、地点、作品等14个主类,亲属关系、非亲属关系等24个主对象属性,姓名、朝代等39个主数据属性,如图1所示;导出本体文件。
3.按照开源软件d2rq配置文件规范,编写映射文件;将mysql数据库的每个表映射到本体结构对应的类别下;其次,针对每个表的每个字段,编写映射代码将其映射到本体结构中对应的属性;使用d2rq提供的dump-rdf工具将mysql数据库中的结构化数据转换为rdf格式。
4.利用jena的工具tdbloader对第3步中得到的rdf数据文件建立索引并存储;将保存的本体文件复制一份放置在jenafuseki配置文件目录下;执行fuseki-server脚本启动sparql终端查询服务。
5.利用基于正则和规则的语义解析方法解析用户查询;如果解析成功,通过预定义的sparql模板进行查询;存在对应答案,则返回给用户,否则返回预定义的回复;如果解析失败,利用基于神经网络的方法继续解析用户查询;bilstm+crf网络得到查询中的实体,textcnn网络得到查询涉及的关系;如果解析成功,通过sparql进行查询;存在对应答案,则返回给用户,否则返回预定义的回复。
6.问答系统的整体架构如图2所示,用户查询流程图如图3所示;网页端的用户交互界面如图4所示,图5展示了用户通过微信端公众号和系统交互的过程。
7.用户使用系统过程中,后台持续收集日志和反馈,迭代训练神经网络语义解析模型。
- 还没有人留言评论。精彩留言会获得点赞!