一种面向时间序列型地表水质大数据的预测与评估模型构建方法与流程
本发明涉及水质大数据预测与评估模型构建技术领域,是一种面向时间序列型地表水质大数据的预测与评估模型构建方法,特别涉及一种基于马氏距离改进的kmeans++聚类和z分数计算的异常值检测方法、基于粒子群优化算法改进的支持向量回归的空缺值填补方法、基于随机森林算法的重要度分析方法、基于粒子群优化算法改进的lstm模型的时间序列预测方法以及基于mapreduce的并行化计算方法的水质大数据预测与评估模型构建方法。
背景技术:
影响水质的物理,化学,生物因素广泛,生物处理仍然表现出受各种已知和未知参数影响的时变和高度非线性特征,传统的基于线性关系的预测方法不足以解决这一问题。由于这些复杂的特征,许多先前的研究通过使用数学模型评估地表水的水质。其中,机器学习模型已被证明是一种有用的工具,因为它具有处理复杂系统的相对高的精度。此外,这些模型预测地表水质的关键优势在于,这些模型只能在训练和验证步骤之后直接预测输入值的输出。人工神经网络(ann)和支持向量机(svm)是代表性的机器学习技术。但是大多数研究人员只关注某一单因素指数的预测,很少关注综合水质。由于影响水质的化学、生物和物理参数众多,单因素指数和综合水质的预测相结合的综合评估体系是未来水质大数据分析领域的重点研究对象。完善的水质多维评价体系可以为今后水务决策做出重要的判断。随着水资源大数据研究的快速发展,出现了数据量巨大的海量数据集和以超大规模特征为特征的高维数据集。如何有效地从高位数据中提取或选择出有用的特征信息已成为水质大数据分析所面临的基本问题。特征选择是指从原始数据集中选择某种评估标准最优的子集,以使在该最优特征子集上所构建的分类或回归模型达到与特征选择前近似甚至更好的预测精度。同时机器学习算法普遍具有较高的时间复杂度和空间复杂度,使得基于单一节点计算的水质大数据分析变得十分困难。大数据技术的出现为这类问题提供了新的并行化解决方案。例如在hadoop平台上实现mapreduce对于提升数据处理算法的效率有非常重大的意义。
技术实现要素:
鉴于上述现有技术的不足,本发明的目的在于提供一种面向时间序列型地表水质大数据的预测与评估模型构建方法,旨在解决水质数据分析的问题,并实现统一的、自动化的“水质数据清洗-水质数据预测-水质评估”流程,并建立最终的水质大数据分析体系。
本发明解决其技术问题所采取的技术方案是:一种面向时间序列型地表水质大数据的预测与评估模型构建方法,该方法主要包括如下步骤:
步骤1:使用数据清洗算法对地表水质数据进行异常值检测和空缺值填补。
步骤2:使用随机森林算法对水质指标进行重要特征提取,选取重要度高的指标用于水质整体状态的评估。
步骤3:基于对每一时间点的水质评估,使用时间序列预测算法进行水质整体状态的预测。
步骤4:基于hadoop平台的mapreduce编程实现程序的并行化执行,得到最终的时间序列型地表水质大数据的预测与评估模型。
进一步的,本发明步骤1所述的数据清洗算法对地表水质数据进行异常值检测和空缺值填补的方法,其步骤具体包括:
步骤1-1:使用python从水质数据库中读取数据并清除明显违反常识的数值。
步骤1-2:使用python编程,根据存在空缺值的时间点上的所有数据找到与其马氏距离最近的时间点,并用这个时间点上的数据来填补空缺值。
步骤1-3:使用python实现马氏距离改进的kmeans++聚类算法和z分数检测算法分别从每一时间点数据的整体状态和单因素指标的数据分布状态来检测水质数据中的异常值。
步骤1-4:使用python实现粒子群优化算法优化的支持向量回归算法填补第三步中检测出来的异常值。
步骤2所述重要度分析的方法,其步骤具体包括:
步骤2-1:基于gb3838-2002地表水质评价标准将每一时间点上的水质整体状态分类。
步骤2-2:使用python机器学习算法工具包scikit-learn实现随机森林算法,从而实现水质指标的重要特征提取,选取重要度高的指标用于水质整体状态的评估。
步骤3所述的时间序列预测的方法,其步骤具体包括:
步骤3-1:获取每一时间点的历史水质整体状态评估数据。
步骤3-2:将历史水质整体状态评估数据作为使用python机器学习算法工具包tensorflow实现基于粒子群优化算法优化的lstm模型的输入,并进行预测。
步骤4所述的使用mapreduce实现并行化计算的方法,其步骤具体包括:
步骤4-1:基于hadoop搭建分布式集群模型。
步骤4-2:集群中分配不同主机对不同指标进行错误数据清除,实现程序并行化。
步骤4-3:集群中分配不同主机对同一数据集执行kmeans++算法,从中选取最优初始中心,实现程序并行化。
步骤4-4:集群中分配不同主机对不同指标进行z分数计算,实现程序并行化。
步骤4-5:集群中分配不同主机对粒子群优化算法的粒子进行更新,实现程序并行化。
步骤4-6:集群中分配不同主机在同一数据集对不同时间段数据计算整体状态分类,实现程序并行化。
步骤1-3所述的用马氏距离改进的kmeans++聚类算法和z分数检测算法检测异常值的方法,其步骤具体包括:
步骤1-3-1:从检测某一时间点水质整体状态的思路出发,使用马氏距离改进的kmeans++聚类算法将水质数据分为两类,类别占比大的是非异常数据,占比小的是异常数据。
步骤1-3-2:使用z分数检测算法检测各个单因素指标的异常值情况。
步骤1-3-3:在kmeans++聚类算法和z分数检测算法中都被标记为异常的数值被认定为异常值,并被标记为null。
步骤1-3-4:使用python实现粒子群优化算法优化的支持向量回归算法将上一步检测出来的null值填补。
步骤3-2所述的运用基于粒子群优化算法优化的lstm模型根据历史水质整体状态预测未来水质整体状态的方法,其步骤具体包括:
步骤3-2-1:使用python机器学习算法工具包tensorflow构建基本的lstm模型,其中模型的两个参数:步长和学习率由人为设置,分别代表lstm记忆的时间段和每一次梯度下降的间隔。
步骤3-2-2:使用python编程构建粒子群,粒子群中每一个粒子的位置是一个二维变量,代表lstm模型的学习率和步长,初始化值由人为给出。
步骤3-2-3:将所有粒子平均分配到集群中去根据rmse更新局部最优值和全局最优值。当达到最大迭代次数之后,粒子群的全局最优值就是lstm模型最优的步长和学习率。
所用的z分数检测算法具体步骤为:
第一步,设对被测量进行等精度测量,独立得到x1,x2,...,xn,算出其算术平均值
第二步,按贝塞尔公式算出标准误差
z分数:
其中xb表示每一个被测量的具体值。
第三步,若|zb|>3则认为xb是含有粗大误差值的坏值,为水质异常值。
所用的随机森林算法计算变量重要度的具体步骤为:
第一步,假设有bootstrap样本b=1,2,3,.....,b,b表示训练样本的个数。首先设置b=1,在训练样本上创建决策树tb,并将袋外数据标记为
第二步,在袋外数据上使用tb对
第三步,对于特征xj(j=1,2,3….,n),对
第四步,对于b=2,3,…….,b,重复步骤(1)~(3)。特征xj的变量重要性度量
重要度:
所用的粒子群优化算法的具体步骤为:
第一步,假设在d维空间中有n个粒子。
每个粒子的位置可以描述为xi=(xi1,xi2,xi3,xi4,...,xid)。每个粒子的速度被描述为vi=(vi1,vi2,vi3,vi4,...,vid)。每个粒子的适应值由优化问题的目标函数决定,并且知道到目前为止它的最佳位置(pbest)和它的当前位置(xi),这可以看作粒子自己的飞行经验。同时,由于粒子伴侣的经验,每个粒子也知道迄今为止对于整个群体(gbest)的最佳位置,这是pbest的最佳值。速度更新如下:
更新速度:
第二步,
第三步,位置的更新如下:
更新速度:
其中
本发明能够应用于水质大数据的预测与评估模型的构建。
有益效果:
1.本发明在水质数据清洗阶段,面对大量时间序列型水质数据,能够高效准确的填补空缺值和检测异常值,为水质整体状态的评估和预测提供科学完备的数据集。并且利用粒子群优化算法优化了支持向量回归算法对于惩罚因子和系统误差两个参数的选择,从而提升模型的预测性能。
2.本发明在水质数据预测阶段,利用随机森林算法从水质数据的多维特征中选取较少的指标表征整体水质状况,提高数据质量容忍度。同时降低水质研究工作量,对于维度更大的数据集,只用关注重要指标的量即可。并且利用粒子群优化算法优化了lstm算法对于步长和学习率两个参数的选择,从而提升模型的预测性能。
3.本发明在程序并行化模型构建阶段,利用hadoop搭建的分布式多机机群实现mapreduce编程,从而实现各个算法的并行化执行,提高各个算法的执行效率,提高模型的整体计算能力。
附图说明
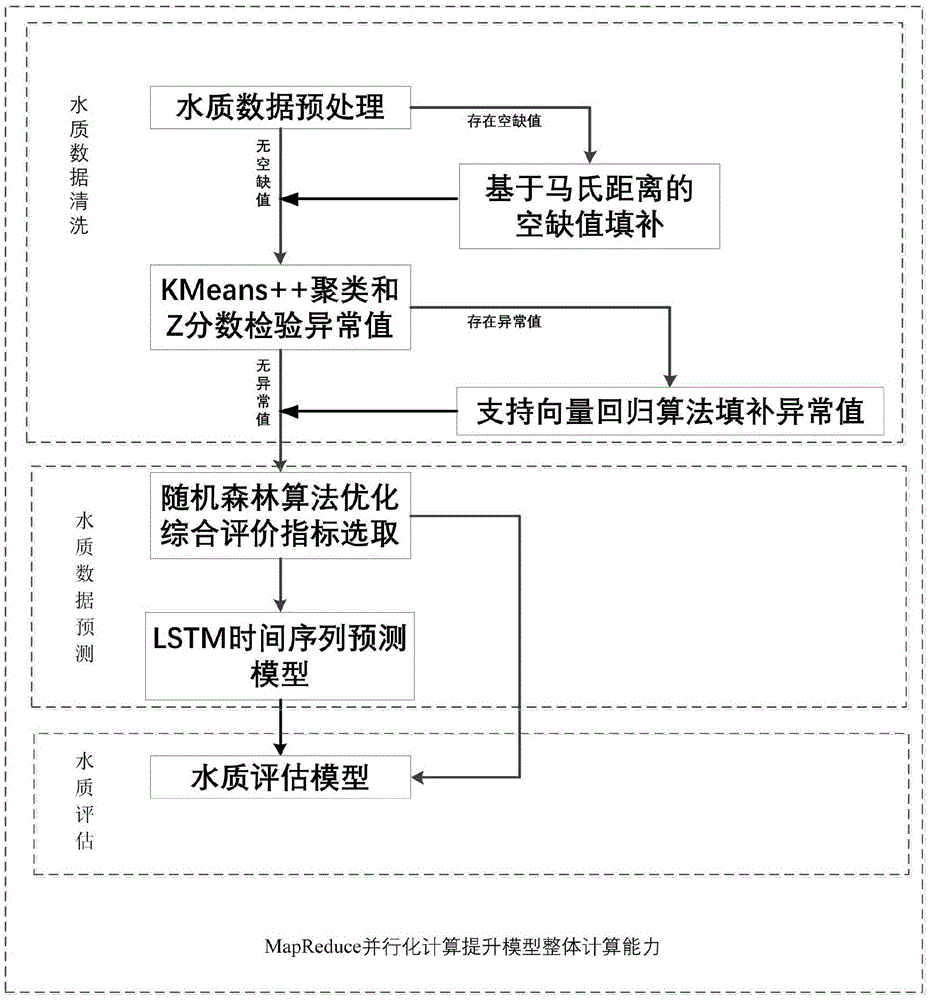
图1为本发明一种面向时间序列型地表水质大数据的预测与评估模型构建方法的流程图。
图2为步骤1-4中的粒子群优化算法优化支持向量回归(svr)算法的具体流程图。
图3为步骤3-2中的粒子群优化算法优化lstm模型的具体流程图。
图4为搭建的分布式集群图。
图5为空缺值填补时各种算法预测性能对比表。
图6为数据清洗前后异常值统计情况对比图。
图7为重要度分析的结果图。
图8为时间序列预测时各种算法预测性能对比表。
图9为粒子群优化算法优化lstm模型的串行执行和并行执行时间对比表。
图10为粒子群优化算法优化lstm模型的利用前16天的数据预测后10天数据的模型性能情况表。
图11为gb3838-2002地表水质评价标准示例。
具体实施方式
本发明提供一种面向时间序列型地表水质大数据的预测与评估模型构建方法,为使本发明的目的、技术方案及效果更加清楚、明确,以下对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
请参阅图1。图1为本发明一种面向时间序列型地表水质大数据的预测与评估模型构建方法较佳实施例的流程图,如图所示,其实施步骤,包括如下:
第一步,从水质数据库中读取某一监测站的水质数据并清除明显违反常识的数值。
第二步,根据存在空缺值的时间点上的所有数据找到与其马氏距离最近的时间点,并用这个时间点上的数据来填补空缺值,从而得到完整数据集。
第三步,实现马氏距离改进的kmeans++聚类算法和z分数检测算法分别从每一时间点数据的整体状态和单因素指标的数据分布状态来检测水质数据中的异常值。
第四步,实现粒子群优化算法优化的支持向量回归算法填补第三步中检测出来的异常值。
第五步,基于gb3838-2002地表水质评价标准将每一时间点上的水质整体状态分类。
第六步,实现随机森林算法,从而实现水质指标的重要特征提取,选取重要度高的指标用于水质整体状态的评估。
第七步,实现基于粒子群优化算法优化的lstm模型,并结合水质评价标准和第六步选出的重要指标进行水质整体状态的预测。
第八步,基于hadoop平台的mapreduce编程实现程序的并行化执行,提高各个算法的执行效率。
在图2中,r2表示决定系数。决定系数的定义如下:
决定系数:
qm(i),q0(i),
均方根误差:
其中oi和xi分别代表观测值和预测值。均方根误差越接近0,预测模型越准确。由图5可以看出,基于粒子群优化算法优化的支持向量回归的预测性能是最好的。图6以高碑店水质监测站的水质数据为例,可以看出,在进行了数据清洗之后,异常值明显减少,有利于后续的数据挖掘工作。由图7可以看出,在使用随机森林算法进行重要度分析后,选取重要度大于50的指标评估水质整体状态,对于后续预测模型的输入降维有重要意义。由图8可以看出,基于粒子群优化算法优化的lstm模型的预测性能是最好的。由图9可以看出,再用mapreduce实现了程序的并行化之后,模型的计算效率明显提升。由图10可以看出,在确定了lstm步长为16之后,其预测后5天的数据的rmse基本可以保持在0.09以下,预测性能良好。图11为gb3838-2002地表水质评价,实际评价过程中也可以根据需要自行设置水质指标对于分类。所以以上结果可以看出本发明提出的面向时间序列型水质大数据的预测与评估模型对于水质大数据分析体系的建立具有较好的效果。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!