一种基于社交媒体突发事件的信息获取方法及系统与流程
本发明涉及数据挖掘技术领域,特别是一种基于社交媒体突发事件的信息获取方法及系统。
背景技术:
传统的突发事件应急信息是由官方或权威机构采集、整理、发布的。其缺点主要表现在:采集过程缺乏大众的参与和反馈,信息来源比较单一;采集时效性低,甚至在突发事件发生后一段时间内不能及时获取事件的任何信息,如重大自然灾害;信息传播方向为官方至大众,呈单向流动,缺少反馈和沟通。这些不足使得传统的突发事件应急信息难以满足及时、有效、合理处置突发事件的需求。
社交媒体越来越多地被看作是随人群移动的传感器,感知着发生在周边的事件以及远处的其他突发事件,并在网络中互相共享和沟通。一旦某地有突发事件发生,事发地的人们会第一时间通过文字、图片以及视频向互联网广播事件的状态。与此同时,处在事发地外围的人们在社交网络上看到相关报道或讲述后,会纷纷作出及时的响应,最后与事件相关的信息就会很快充斥着整个社交网络。突发事件信息以社交媒体数据的形式在社交网络中广泛传播。
综上所述,社交媒体具有的自发性、及时性、广泛参与性、内容多样性正好弥补了传统突发事件应急信息的不足。面对海量的社交媒体数据,如何快速、及时、准确地从中挖掘出突发事件应急信息是需要研究的关键问题。
2015年学者白华在《基于中文短文本分类的社交媒体灾害事件检测系统研究》论文中提出基于支持向量机进行突发地震信息的提取,并且将最终结果的结果在地图上进行可视化,由于没有对算法进行改进,仅选取文本特征组合和几种分类方法中效果较好的支持向量机分类算法,分类结果勉强能接受。
学者吴新华在2017年文中《吴新华与栾翠菊,基于微博文本分类的突发地震事件检测方法》提出基于关键词过滤和时间关系识别的方法进行提高分类结果,使得f1指标上升了5.3%,但是时间关系识别的方法引入了大量的正则关系表达式,忽略了文本的语义关系,使得该模型在正则表达式规则之外的结果就不能精确识别,有一定的局限性。
技术实现要素:
本发明的目的是提供一种基于社交媒体突发事件的信息获取方法及系统,旨在解决现有技术中文本分类结果精度低的问题,实现了分类精度的提升,有助于为突发事件决策的制定提供依据。
为达到上述技术目的,本发明提供了一种基于社交媒体突发事件的信息获取方法,所述方法包括以下步骤:
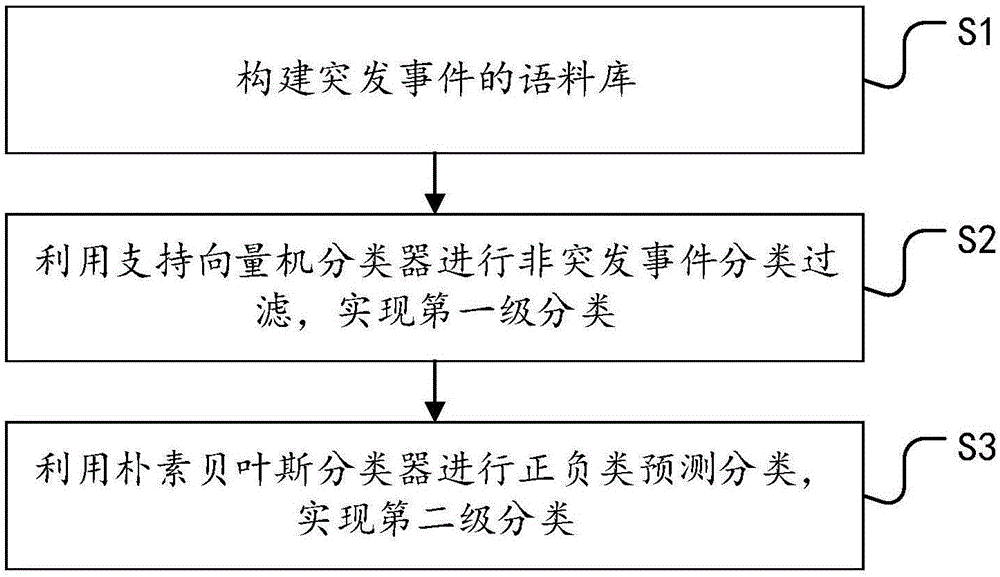
s1、构建突发事件的语料库;
s2、利用支持向量机分类器进行非突发事件分类过滤,实现第一级分类;
s3、利用朴素贝叶斯分类器进行正负类预测分类,实现第二级分类。
优选地,所述步骤s1具体包括以下操作:
对爬虫获取的数据进行文本去重、去主题无关词、去停用词以及文本分词处理;
构建向量空间,用向量表示每个文本。
优选地,所述文本去重具体为:
在爬虫爬行过程中设置社交媒体的参数,对社交媒体内容完全一样或是转发的认定为重复。
优选地,所述去主题无关词具体为:
利用正则表达式以及人工删除的方式来进行与主题无关的词语删除工作。
优选地,所述构建向量空间具体操作为:
将字符转化到向量空间模型当中,将训练语料库中的所有词汇转化到统一的向量空间模型中,每个文本都可以用向量来表示;所述向量空间的构建采用数据挖掘软件weka的转词向量工具。
本发明还提供了一种基于社交媒体突发事件的信息获取系统,所述系统包括:
语料库构建模块,用于构建突发事件的语料库;
非突发事件分类过滤模块,用于利用支持向量机分类器进行非突发事件分类过滤,实现第一级分类;
正负类预测分类模块,用于利用朴素贝叶斯分类器进行正负类预测分类,实现第二级分类。
优选地,所述语料库构建模块包括:
去重单元,用于对文本去重;
去主题无关词单元,用于去除与主题无关的词;
去停用词单元,用于去除停用词;
文本分词单元,用于进行文本分词;
向量空间构建单元,用于构建向量空间,用向量表示每个文本。
优选地,所述向量空间的构建采用数据挖掘软件weka的转词向量工具。
发明内容中提供的效果仅仅是实施例的效果,而不是发明所有的全部效果,上述技术方案中的一个技术方案具有如下优点或有益效果:
与现有技术相比,本发明通过爬虫对社交媒体进行相关关键词的语料库获取,通过去重、去主题无关词、去停用词以及文本分词对语料库进行处理获得最终地震语料库,利用支持向量机分类器进行非突发事件分类过滤,实现第一级分类,利用朴素贝叶斯分类器进行正负类预测分类,实现第二级分类,实现信息分类精度相对于没有经过非即时地震信息筛选的结果提高2.9%,f-measure的值提高2.6%,解决了现有技术中文本分类结果精度低的问题,实现了分类精度的提升,有助于决策者对于灾害事件的掌控,为决策的制定提供依据。
附图说明
图1为本发明实施例中所提供的一种基于社交媒体突发事件的信息获取方法流程图;
图2为本发明实施例中所提供的一种利用支持向量机分类器进行非突发事件分类过滤后的模型精度图;
图3为本发明实施例中所提供的一种基于社交媒体突发事件的信息获取系统结构框图。
具体实施方式
为了能清楚说明本方案的技术特点,下面通过具体实施方式,并结合其附图,对本发明进行详细阐述。下文的公开提供了许多不同的实施例或例子用来实现本发明的不同结构。为了简化本发明的公开,下文中对特定例子的部件和设置进行描述。此外,本发明可以在不同例子中重复参考数字和/或字母。这种重复是为了简化和清楚的目的,其本身不指示所讨论各种实施例和/或设置之间的关系。应当注意,在附图中所图示的部件不一定按比例绘制。本发明省略了对公知组件和处理技术及工艺的描述以避免不必要地限制本发明。
下面结合附图对本发明实施例所提供的一种基于社交媒体突发事件的信息获取方法及系统进行详细说明。
如图1所示,本发明实施例公开了一种基于社交媒体突发事件的信息获取方法,所述方法包括以下步骤:
s1、构建突发事件的语料库;
s2、利用支持向量机分类器进行非突发事件分类过滤,实现第一级分类;
s3、利用朴素贝叶斯分类器进行正负类预测分类,实现第二级分类。
本发明实施例以“地震”作为关键词,通过新浪微博爬虫,基于新浪微博高级查询页面,自定义事件以及关键词进行地震语料库获取。数据由爬虫脚本获取,爬取到数据之后以csv格式文件存储在excel里面,但是在weka中需要以txt文本的形式进行处理。利用python遍历每条微博,然后保存为txt格式。
通过进行微博文本去重、去主题无关词、去停用词处理以及文本分词处理来完成地震事件的语料库。主题无关词可以是“分享来自秒拍”、“该微博由移动微博客户端发送”等与主题无关的词语。停用词可以是“你”、“我”、“哼”、“呀”等实际意义不大,对主题贡献小的词语。
所述去重操作具体为在爬虫爬行过程中设置一个新浪微博的参数,对微博内容完全一样或是转发的认定为重复,从而实现去重处理。
所述去主题无关词操作具体为利用正则表达式以及人工删除的方式来进行。去除无关结构词如“#美国空袭叙利亚#”,其中标题包含在“#”之间,可以定义正则表达式“#.*#”识别所有的标题。例如附加的超链接“(新京报我们视频)”,这个信息包含在一对括号里面,可以采用“(.*)”来匹配括号和括号里面的内容。而对于无法采用正则表达式方法来识别的,则采用人工删除的方式来去除与主题无关的词语。
所述去停用词和分词处理是同时处理的,由于自然语言处理的最小单元是词语,因此需要将文本分解为词语单元,进行概率计算。采用jieba分词工具进行分词处理,通过调用该工具提供的python接口进行精确分词,将句子变成词语为单元的内容,利用哈工大停用词表进行停用词处理。
在通过去重、去无关词、去停用词以及文本分词操作后,获得地震语料库,通过构建向量空间来用向量表示每个文本。
由于为了能够让计算机对每一文本进行数学计算并进行统计分析,使文本文件具有可计算性,需要将字符转化到向量空间模型当中,将训练语料库中的所有词汇转化到统一的向量空间模型中,每个文本都可以用向量来表示。所述向量空间的构建采用数据挖掘软件weka的转词向量工具。
在获取语料库后,对语料库进行第一次分类,将语料精确的划分为即时突发地震、历史事件、虚拟情况、修辞手法、地震相关作品、灾害预测及应对、其它类七类,对非突发事件进行分类过滤。历史事件、虚拟情况、修辞手法、地震相关作品、灾害预测及应对、其它类为噪音事件。
非即时的突发地震微博信息即为噪音事件,机器区分噪音事件的方法是利用机器学习当中的支持向量机方法,该方法需要两种语料库,第一个是必须通过人工训练的训练语料库,包括根据人为经验而对微博数据进行分类得到的6类噪音类别的语料库;第二个语料库是测试语料库,机器预测通过上述训练语料库学习得到特征函数以及参数,并且对测试数据集采用该函数及参数,进行概率计算,选出概率最大的一个类别就是机器判断类别的方法。
在本发明实施例中,从新浪微博爬取从2014年-2018年的以“地震”为关键词的微博,经过人工筛选分类,语料库中即时突发地震类170条,历史事件类179条,其它类147条,灾害预测及应对类168条,修辞手法类175条,虚拟情况类160条,地震相关作品类144条,并且在本文中分别记为positive,history,none,predict,rhetoric,virtual,work类。对上述训练语料库创建文件夹,子文件夹为各个噪音文件的文本文件,并在weka操作界面通过以下命令行将文件转化为arff格式的文件:
javaweka.core.converters.textdirectoryloader-dire:/negative>e:/negative.arff
然后导入到weka界面,之后将其转化到词向量空间,最后选择分类器为支持向量机,进行10倍交叉验证,得到的模型精度如图2所示。
将成功分类为“历史事件”、“虚拟情况”、“修辞手法”、“地震相关作品”、“灾害预测及应对”5类的非即时突发地震信息从语料库中剔除,对剩下的样本输入到第二级分类器中进行预测分类。“其他类”由于模型精度以及规律性较差,将其保留,进入下一级正负类预测分类。
所述正负类预测分类可视为二分类问题,即一个样本不是即时突发地震信息就是非即时突发地震信息,利用机器学习当中的朴素贝叶斯方法,基于人工构建的训练数据集,利用贝叶斯公式:p(y|x)=p(x|y)p(y)/p(x)来进行分类。
基于朴素贝叶斯的文本分类方法包括以下过程:
准备阶段:将文本当中的每一个词语作为其特征属性,并对每一个文本进行人工标注,即将文本进行二次分类,将文本分类突发地震类和非突发地震类;
分类器训练阶段:利用训练样本计算该模型的先验概率;
应用阶段:根据测试样本,计算条件概率,计算出该文本对于不同类的后验概率,找出最大概率的一类即为所预测的类。对数据集进行人工筛选,记地震即时消息为正类,非即时消息为负类。在本发明实施例中为了使正负样本数量一致,设置数据集正类为218条,负类文本为218条。
对于第二级分类所采用的构建模型的方法为利用weka数据挖掘软件进行模型构建,所采用的分类器选择的是朴素贝叶斯分类器。分类结果如表1所示。
表1
将第一层分类得到的结果输入到第二层,结果精度、召回以及f-measure相较于没有经过第一层分类器过滤的分类结果得到了部分提升。
本发明实施例通过爬虫对社交媒体进行相关关键词的语料库获取,通过去重、去主题无关词、去停用词以及文本分词对语料库进行处理获得最终地震语料库,利用支持向量机分类器进行非突发事件分类过滤,实现第一级分类,利用朴素贝叶斯分类器进行正负类预测分类,实现第二级分类,实现信息分类精度相对于没有经过非即时地震信息筛选的结果提高2.9%,f-measure的值提高2.6%,解决了现有技术中文本分类结果精度低的问题,实现了分类精度的提升,有助于决策者对于灾害事件的掌控,为决策的制定提供依据。
如图3所示,本发明还公开了一种基于社交媒体突发事件的信息获取系统,所述系统包括:
语料库构建模块,用于构建突发事件的语料库;
非突发事件分类过滤模块,用于利用支持向量机分类器进行非突发事件分类过滤,实现第一级分类;
正负类预测分类模块,用于利用朴素贝叶斯分类器进行正负类预测分类,实现第二级分类。
所述语料库构建模块包括:
去重单元,用于对文本去重;
去主题无关词单元,用于去除与主题无关的词;
去停用词单元,用于去除停用词;
文本分词单元,用于进行文本分词;
向量空间构建单元,用于构建向量空间,用向量表示每个文本。
所述去重操作具体为在爬虫爬行过程中设置一个新浪微博的参数,对微博内容完全一样或是转发的认定为重复,从而实现去重处理。
所述去主题无关词操作具体为利用正则表达式以及人工删除的方式来进行。去除无关结构词如“#美国空袭叙利亚#”,其中标题包含在“#”之间,可以定义正则表达式“#.*#”识别所有的标题。例如附加的超链接“(新京报我们视频)”,这个信息包含在一对括号里面,可以采用“(.*)”来匹配括号和括号里面的内容。而对于无法采用正则表达式方法来识别的,则采用人工删除的方式来去除与主题无关的词语。
所述去停用词和分词处理是同时处理的,由于自然语言处理的最小单元是词语,因此需要将文本分解为词语单元,进行概率计算。采用jieba分词工具进行分词处理,通过调用该工具提供的python接口进行精确分词,将句子变成词语为单元的内容,利用哈工大停用词表进行停用词处理。
由于为了能够让计算机对每一文本进行数学计算并进行统计分析,使文本文件具有可计算性,需要将字符转化到向量空间模型当中,将训练语料库中的所有词汇转化到统一的向量空间模型中,每个文本都可以用向量来表示。所述向量空间的构建采用数据挖掘软件weka的转词向量工具。
非即时的突发地震微博信息即为噪音事件,机器区分噪音事件的方法是利用机器学习当中的支持向量机方法,该方法需要两种语料库,第一个是必须通过人工训练的训练语料库,包括根据人为经验而对微博数据进行分类得到的6类噪音类别的语料库;第二个语料库是测试语料库,机器预测通过上述训练语料库学习得到特征函数以及参数,并且对测试数据集采用该函数及参数,进行概率计算,选出概率最大的一个类别就是机器判断类别的方法。在weka数据挖掘软件中,将其转化到词向量空间,最后选择分类器为支持向量机分类器。
所述正负类预测分类可视为二分类问题,即一个样本不是即时突发地震信息就是非即时突发地震信息,利用机器学习当中的朴素贝叶斯方法,基于人工构建的训练数据集,利用贝叶斯公式:p(y|x)=p(x|y)p(y)/p(x)来进行分类。对于第二级分类所采用的构建模型的方法为利用weka数据挖掘软件进行模型构建,所采用的分类器选择的是朴素贝叶斯分类器。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!