一种基于mongodb的海量数据存储方法与流程
本发明涉及一种海量数据存储方法,具体来讲是一种基于mongodb的海量数据存储方法,也可以适用其它数据库。
背景技术:
目前,mongodb数据库本身是一款设计用来存储信息的非关系型数据库,但是在实际使用过程中会有一下问题:
1、单数据集群支持的数据量还是有限,使用分片技术也会有类似问题;
2、要加快查询就需要加索引,加索引响应速度就会变慢;
3、即使是使用多集群来存储海量数据,如果没有好的存储方案,还是会有性能瓶颈问题,因为多集群意味着数据处理也会很复杂,在多集群的架构下,数据的调配就需要集中统一处理,同时需要相应的解决方案。
例:当mongodb的存储数据超过千亿的时候,必然是靠分集群分表分库来解决数据的存储和查询,那么如何对数据实施分集群分表分库,这就需要选择合适的分配方案才能达到理想的结果。
技术实现要素:
因此,为了解决上述不足,本发明在此提供一种基于mongodb的海量数据存储方法(本发明也适用其它数据库);本发明主要是用来处理大数据的存储方案。例:经过多次试验结果表明,当数据以亿为数量级以后,对唯一关键字加密后得到的md5关键字,根据上文规则拆分,基本可以平均分配到每个集群的每个库的每张表,每张表的数据量之间的悬殊不会很大。
本发明是这样实现的,构造一种基于mongodb的海量数据存储方法,其特征在于:按照如下实施;
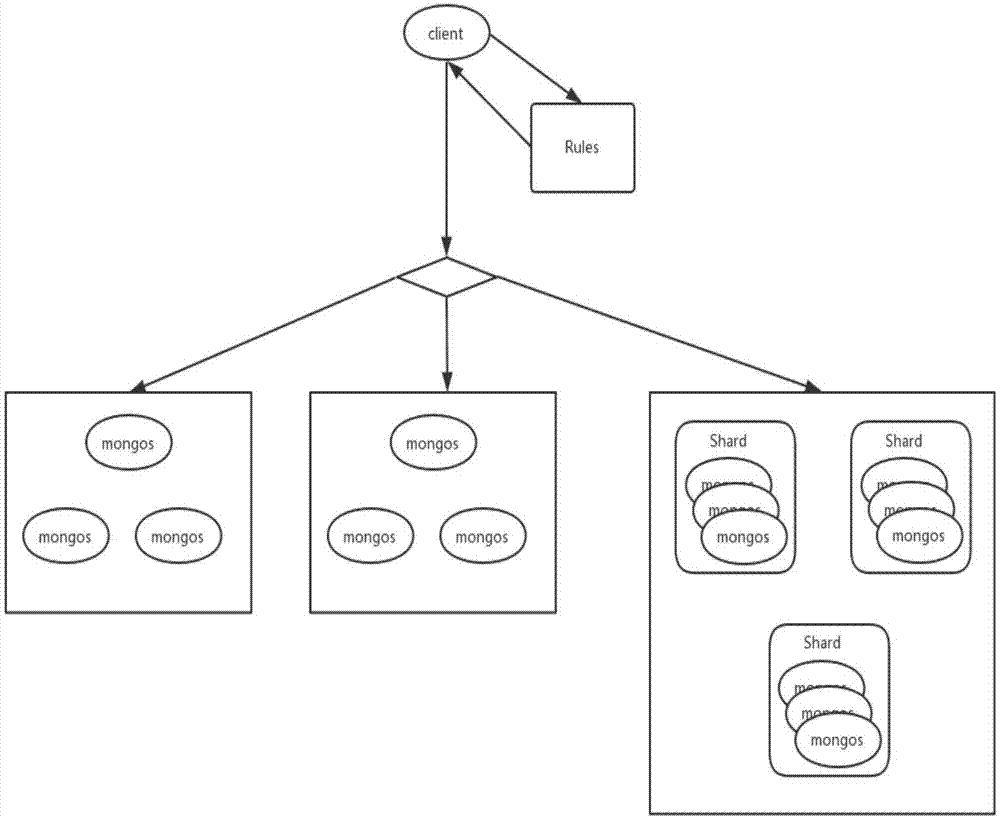
1)数据存储位置请求:
在数据存储和用户请求之间,加上一个数据逻辑分布处理中心,该处理中心根据规则处理数据存储的发布;数据终端的第一步就是向规则中心请求该条数据所处的节点;
例:终端提交的数据为该数据的关键字,处理中心对关键字进行md5处理后,得到的一个32位的字符串,该字符有一个特点即是一个16进制的表示方法,即:字符串由0到9以及a,b,c,d,e,f组成;
2)数据分集群规则:在处理大数据的时候需要分集群,分库,分表;那么针对海量的数据,根据md5关键字来进行拆分,比如以字符串的第一个字符来进行拆分,那么可以将整个数据拆分到16个集群,以字符串的前二个字符来进行拆分则可以将所有数据拆分到256个集群;
3)数据分库规则:与分集群同理,依据md5关键字,取字符串的第2到第4个来进行分库;库名以取值的字符串命名;
4)数据分表规则:与分库同理,依据md5关键字,取字符串的第5到第6个来进行分表,表名以取值的字符串命名;
5)存储:当一条数据想处理中心请求到该数据所处位置时,根据返回的位置数据以及规则,就知道它应该存放在那个集群,那个库,那张表,即可以存储在对应的位置即可;
6)单一数据取值:当根据条件去获取单一数据时,向处理中心传入所需参数,处理中心返回该条数据所处位置,根据数据中心返回的位置信息和规则可以知道该数据存放在那个集群,那个库,那张表,然后去对应的位置取值即可。
7)多数据查询:根据条件利用mapreduce去各集群取值即可。
本发明在此提供一种基于mongodb的海量数据存储方法,按照如下实施;1)数据存储请求:在数据存储和用户请求之间,加上一个数据逻辑分布处理中心;每条数据在进行存储之前,必须向处理中心发起请求,传入所需参数。处理中心根据传入参数生成一个md5值,该md5值为全局唯一值。然后处理中心根据规则,依据md5值来生成该数据所处的集群,库,表并返回位置数据(例:取字符串的第1个字符来进行集群拆分,可以将所有数据拆分到16个集群(如果根据前2个字符来进行拆分,可以将字符拆分为256个集群,一般情况下不建议超过256个集群);取字符串的第2到第4个来进行分库;取字符串的第5到第6个来进行分表;);2)数据集群存储:根据返回的存储信息找到对应的集群就行存储;3)数据分库存储:根据返回的存储信息找到对应的集群下的对应库就行存储;4)数据分表存储:根据返回的存储信息找到对应的表就行最终数据存储;;5)取值:当查询一条数据时,需要去分布处理中心取得该数据的位置信息,即:传入所需参数,中心再根据存储的同一规则得到该条数据的位置信息并返回。查询再根据返回的位置信息去查找该条数据。
备注:当数据超过千亿数据量级以后,对唯一关键字加密后得到的md5关键字,根据上文规则拆分,基本可以平均分配到每张表,每张表之间的数据量基本相等。
本发明具有如下优点:本发明在此提供一种基于mongodb的海量数据存储方法;主要是用来处理大数据的存储方案。根据长期的测试,当数据超过千亿数据量级以后,对唯一关键字加密后得到的md5关键字,根据上文规则拆分,基本可以平均分配到每张表,每张表之间的悬殊不会特别大。
附图说明
图1是本发明对应的数据存储流程图示意图。
具体实施方式
下面将结合附图1对本发明进行详细说明,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明通过改进在此提供一种基于mongodb的海量数据存储方法,按照如下实施;
1)数据存储位置请求:
在数据存储和用户请求之间,加上一个数据逻辑分布处理中心,该处理中心根据规则处理数据存储的发布;数据终端的第一步就是向规则中心请求该条数据所处的节点;
例:终端提交的数据为该数据的关键字,处理中心对关键字进行md5处理后,得到的一个32位的字符串,该字符有一个特点即是一个16进制的表示方法,即:字符串由0到9以及a,b,c,d,e,f组成;
2)数据分集群规则:在处理大数据的时候需要分集群,分库,分表;那么针对海量的数据,根据md5关键字来进行拆分,比如以字符串的第一个字符来进行拆分,那么可以将整个数据拆分到16个集群,以字符串的前二个字符来进行拆分则可以将所有数据拆分到256个集群;
3)数据分库规则:与分集群同理,依据md5关键字,取字符串的第2到第4个来进行分库;库名以取值的字符串命名;
4)数据分表规则:与分库同理,依据md5关键字,取字符串的第5到第6个来进行分表,表名以取值的字符串命名;
5)存储:当一条数据想处理中心请求到该数据所处位置时,根据返回的位置数据以及规则,就知道它应该存放在那个集群,那个库,那张表,即可以存储在对应的位置即可;
6)单一数据取值:当根据条件去获取单一数据时,向处理中心传入所需参数,处理中心返回该条数据所处位置,根据数据中心返回的位置信息和规则可以知道该数据存放在那个集群,那个库,那张表,然后去对应的位置取值即可。
7)多数据查询:根据条件利用mapreduce去各集群取值即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!