一种基于单目标区域分割的舌体图像分割方法与流程
本发明涉及一种基于深度学习方法的舌体图像分割方法,具体涉及一种基于单目标区域分割的舌体图像分割方法,属于医学图像分析领域。
背景技术:
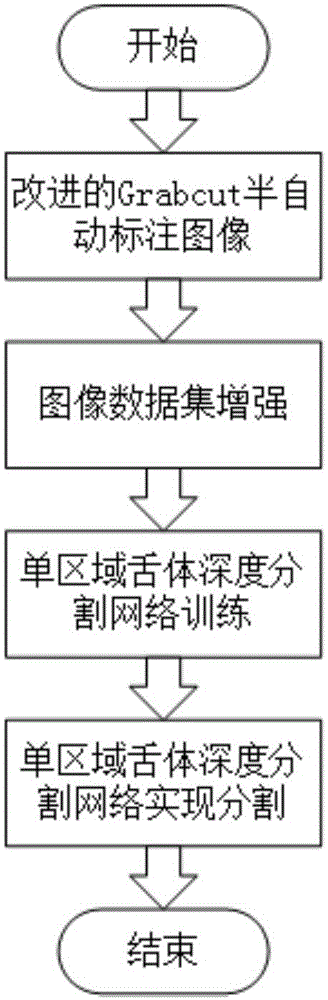
:随着舌头包含着大量有关人体体质的信息,现阶段只有通过丰富的中医专家经验才能诊断出准确的结果。为了对病症诊断进行辅助,并形成全面的计算机舌诊系统,获得准确、高精度的舌体图像是有意义的研究工作。目前已有较多研究工作将面部图像中的舌体分割出来,然而由于舌质与皮肤颜色相近、舌苔颜色多变以及舌体存在变形等干扰,舌体分割效果不佳。舌体图像分割是舌体目标检测与舌体语义分割的总和,是计算机舌诊中舌体特征提取和分析的重要前提。通常采用的方法有阈值分类、边缘检测、轮廓跟踪、区域生长等方法,如分水岭分割,分裂—合并分割,主动轮廓模型分割,这些方法对固定摄像设备采集的图像下表现良好,然而对非标准仪器如智能手机等拍摄的多样性图像,效果不佳,泛化性不能保证。为弥补上述不足,本文提出的基于深度学习的舌图像分割方法,在学习舌体图像掩模的同时,学习到舌体的区域位置信息。该方法对于未统一大小的舌拍摄图像,即自由摄像设备采集的舌图像也可以得到较好结果,并且该方法对数据增强,弥补了采集的舌图像存在变形或倾斜带来的影响。近几年来,深度学习由于其强大的特征表示和学习能力,在计算机视觉领域取得杰出的成果。卷积神经网络提出后,深度学习的一些模型,如vgg、rcnn、fcn、u-net等能较好地解决图像分类、目标检测、图像分割等问题。但目前还没有一些深度学习方法是专用于舌体图像等单体目标语义分割的情况。技术实现要素:针对上述现有技术的不足,本发明的目的在于,针对舌体图像分析给出一种基于单目标区域分割的舌体图像分割方法,该方法可快速有效,准确地对舌体图像进行分割,可极大方便医师对病人疾病的诊断。本发明提供一种基于单目标区域分割的舌体图像分割方法,该方法采用单目标区域约束深度网络来实现对现有图像的标注、分割、学习生成掩模图像,在与原图像合成形成舌体分割图。根据本发明的实施方案,提供一种基于单目标区域分割的舌体图像分割方法。一种基于单目标区域分割的舌体图像分割方法,该方法包括以下步骤:(1)原图像获取:通过图像采集模块采集舌体原图像;(2)图像标注:通过图像标注模块,采用超像素改进的grabcut算法对采集的每一张舌体原图像进行人工标注,获得与每一张舌体原图像对应的标注图像;(3)图像制作:通过图像制作模块,将进行人工标注后的图像与对应的舌体原图像组成图像对;为提高模型泛化性,随机将原图像对作为训练集图像,剩余图像对作为测试集图像;(4)训练神经网络:通过训练集图像,对单目标语义分割神经网络进行训练;(5)测试神经网络:利用训练好的的单目标语义分割神经网络对舌体图像进行分割,通过测试集图像对单目标语义分割神经网络进行测试。作为优选,步骤(1)具体为:舌体原图像来自于智能移动设备及未固定的摄像机设备。作为优选,步骤(2)中所述人工标注的步骤具体为:①、对所采集的图像进行归一化处理;②、利用分水岭算法对归一化处理后的图像进行超像素分割;③、将超像素分割后的图像,通过grabcut算法实现对图像的半自动分割;④、最后对grabcut算法所得的图像结果微调,得到所需的人工标注图。在本申请中,图像的归一化处理,即是对图像进行了一系列标准的处理变换,使之变换为一固定标准形式的过程,该标准图像称作归一化图像。在本申请中,分水岭分割方法,是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。在本申请中,在运用基于分水岭的超像素算法过程中,为获得足够的超像素,其执行过程如下:①、根据大小为n*m的图像均匀地初始化20*20个标记点,即每个标记点都在图像行列的11等分线上,若11等分点非整数,则向上取整。初始化i=0;②、计算输入图像的每个像素点的梯度;③、将标记点依梯度大小升序排序,得数组index;④、计算index[i]周围各点梯度与index[i]梯度的差值,找到最小一阈值使得有n*m/100-1个未标记的连通点的差值小于该阈值,以这些像素点及index[i]点分割为一超像素,并标记;⑤、i=i+1,重复4,直到所有像素点标记完。在本申请中,在采用grabcut算法对超像素图进行半自动分割时,对属于同一个超像素的图像,采用参数共享的方式处理,能很好地提升grabcut算法的计算速度,和减少精度的变化。在本申请中,的grabcut算法对超像素图进行半自动分割,首先人工用鼠标确定一矩形框,舌体在其框内,将框内所有点标记为1,框外点标记为0;然后grabcut算法需对3通道图像进行高斯混合建模。使用每个超像素图的像素均值作为其像素值生成新图像,并计算各像素块的标记值的均值作为新图像各点的标记值,由于新图像属于多通道的彩色图像,所以该方案利用混合高斯建模对新图像建模。最后grabcut算法中,对上述所得的高斯混合模型采用mincut方法迭代计算出最优分割方案,将该方案中前景点对应的超像素块在原始图像中作为前景,背景点对应的超像素块在原始图像中作为背景。将原始图像前景点置1,背景点置0,即得到所需的标记图。利用opencv计算标记图前景所处的最小矩形区域框(x10,y10,x20,y20)。在本申请中,对grabcut算法所得的图像进行微调,即将标注图像的边界映射到原图像中,并在该边界一定范围内寻找原图像中最大梯度边界线,再将该最大梯度边界线作为标注图像的边界,更新标注图像,得到更精确地分割标注图。作为优选,步骤(3)中所述图像制作的步骤包括:数据集增强和随机分配;具体为:对进行人工标注后的图像与对应的舌体原图像进行数据集增强处理,然后将处理后的经过标注后的图像与对应的舌体原图像组成图像对,将图像对随机分为训练图像对集和测试图像对集,获得训练图像对集和测试图像对集。在本申请中,的数据集增强使得模型有更强的泛化性,包括对图像进行旋转以及将数据采用直接压缩、填充后压缩为448*448。作为优选,步骤(4)中所述单目标语义分割神经网络包括:特征提取卷积神经网络、定位框预测神经网络以及掩模预测全卷积神经网络。在本申请中,单目标语义分割神经网络还包括:输入层和输出层;输入层接受图像尺寸不要求一致的舌图像;特征提取网络获取输入层的图像,对其进行卷积操作,用以获取图像深层特征;定位框预测网络接受特征提取网络的输出计算获取舌体定位区域,通过卷积操作将特征映射为长方形坐标信息(x1,y1,x2,y2),其中(x1,y1)及(x2,y2)对应于所在框的对角顶点坐标;掩模预测网络接收特征提取网络提取的特征信息和定位框预测网络得到的定位区域信息,通过反卷积定位框内像素的特征,得到舌体预测的一个二值掩模;输出层输出二值掩模及舌体前景图像。优选的是,特征提取网络采用5层卷积层组成,前两层卷积核大小为7*7,后三层卷积核大小都为3*3,每层输出特征数分别为32、64、128、256和512,并且每层卷积层包括一次卷积操作,一次池化操作以及一次激活操作。其中卷积操作是将前层输出与卷积核做卷积操作,相当于两层神经元之间采用局部连接以及权值共享,极大减小参数量。激活操作采用relu(rectifiedlinearunits)函数,给网络加入非线性因素。池化操作采用最大值池化,池化核大小为2*2。经过这5层卷积层的特征提取,每张舌图像可得到512张特征图,将其作为定位框预测网络及掩模预测网络的输入。特征提取网络详细设计如表1所示:层名称参数输入大小conv17*7,32,stride=2,padding=3448*448conv27*7,64,stride=2,padding=3224*224conv33*3,128,stride=2,padding=1112*112conv43*3,256,stride=2,padding=156*56conv53*3,512,stride=2,padding=128*28优选的是,定位框预测网络主要实现舌体所在框位置的回归,减少fcn网络抠图忽略相对位置带来的误差。该网络采用两层连接层,每层连接包括权重相乘及激活操作,激活操作同样采用relu函数。第一层为局部连接层,将获取的每个特征图通过权重局部连接到一个神经元,共得到512个神经元。第二层为全连接层,权重数为512*4,输出对应4个神经元,其值对应定位框的一组顶点坐标。在本申请中,本实施案例采用掩模预测网络与特征提取网络结构相对称,通过反卷积操作、激活操作及上采样将定位框内像素对应特征解码为二值掩模信息。优选的是,特征提取网络获取的特征输入掩模预测网络之前先通过roi池化,得到定位框内像素对应特征,其中roi池化另一输入为定位框预测网络输出的框的坐标。该掩模预测网络包括5层结构,每层包括一次反卷积操作、一次上采样操作、一次激活操作,核大小及数目等于相对应特征提取网络的层内结构,该网络采用fcn-8s的方式实现,将第一层反卷积结果与特征提取第四层输出合并,作为第二层反卷积的输入。同样地,将第二层反卷积结果与特征提取第三层输出合并,作为第三层反卷积的输入,以此来获取更多的细节信息。掩模预测网络详细设计如下:层名称参数输入大小deconv13*3,32,stride=2,padding=114*14deconv23*3,64,stride=2,padding=128*28deconv33*3,128,stride=2,padding=156*56deconv47*7,256,stride=2,padding=3112*112deconv57*7,512,stride=2,padding=3224*224作为优选,步骤(4)具体为:采用sgd优化训练单目标语义分割神经网络;sgd中的损失函数为目标检测损失加图像分割损失以及权值正则化损失,损失函数losstotal为:losstotal=lossroi+αlossfcn+β||w||(1);其中:lossroi为定位框预测网络的误差,lossroi=1-iouroi;iouroi由式(2)计算:iouroi表示真实值和预测值得交并比squarepre为预测的定位框,squarereal为实际的定位框;squarepre∩squarereal表示实际区域被正确分类的个数;squarepre∩squarereal表示实际区域及预测出区域的像素点总个数;其中:lossfcn为掩模预测误差,lossfcn=1-ioufcn;ioufcn由式(3)计算:ioufcn表示真实值和预测值的交并比areapre表示预测的舌体区域,areareal表示实际的舌体区域;areapre∩areareal表示实际掩模被正确分类的像素个数areapre∪areareal表示实际掩模及预测出掩模的像素点总个数通过损失函数分别计算预测值与给定真实值之间的误差,利用反向传播算法将误差层层回传,再通过随机梯度下降法对每层的参数进行调整和更新,更新公式如下所示,使得网络的预测值更接近真实值:网络的权重变量w为:w由(4)计算:式中,w为更新后的参数值,w′为更新前的参数值,其采用标准正态分布来初始化值;losstotal为式(1)中,通过损失函数计算得到的误差值,可简要表示为losstotal=f(w|i,iy),其中i为原始图像,iy为掩模标签图像,故w与losstotal相互迭代更新;θ为学习率,θ=1.0e-iter/5000-5,θ根据迭代次数iter的增加而减小。其中:α为第一自定义权重、β为第二自定义权重,反应训练过程中各类误差所占比重;在模型学习中,掩模误差应该占较大比重,所以设置α∈(1,20),β∈(0.1,1.2),β||w||是权重正则化损失,总损失增加β||w||,使得网络能够自动削弱不重要的特征,有效减少过拟合风险。作为优选,α∈(2,15),β∈(0.2,1.0)作为优选,α∈(2,10),β∈(0.2,0.8)在本申请中,本实施案例采用随机梯度下降法优化训练过程,该网络的训练过程可分为四步,具体步骤如下:step1:定位框预测网络的预训练。该过程目的是粗略生成候选区域,结构即前文特征提取五层网络,及定位框预测网络的两层网络,通过输入待训练图像以及标注的区域位置信息(x1,y1,x2,y2)训练该网络。该过程采用均方误差函数作为损失函数:step2:掩模预测网络法的预训练。在预训练掩模预测网络过程中,固定第一步训练定位框预测网络,将其输出的定位框作为模型初步分割需要的定位框。本案例中固定定位框网络的权重参数为step1的训练结果,不训练定位框预测网络的两层网络,通过iou误差,迭代优化网络中的权其他重参数。该过程损失函数可表示为:式中areapre及areareal分别表示图像各像素点是否属于预测的舌体区域以及实际的舌体区域的二值矩阵。step3:单区域舌体深度分割网络的微调。使用step2得到网络参数重新训练网络,在此过程中合并三个网络进行联合训练。采用最小目标检测损失、图像分割损失以及权值正则化损失之和为优化目标,更新特征提取网络及掩模预测网络,采用lossroi更新定位框预测网络。训练相关参数表:其中iter为当前迭代次数。作为优选,步骤(5)具体为:采用步骤(4)训练好的单区域舌体深度分割网络计算输入的图像的二值掩模图像,将掩模图像与原图像相乘得到分割后并截取定位框位置的图像作为舌体分割结果。需要进一步说明的是,二值图像是指在图像中,灰度等级只有两种,也就是说,图像中的任何像素不是0就是1,再无其他过渡的灰度值。图像掩模是用选定的图像、图形或物体、对待处理的图像(全部或局部)进行遮挡来控制图像处理的区域或处理过程。在本申请中,原始舌体图像通过采用了步骤(4)训练好的单区域舌体深度分割网络计算,得到了附有舌体分割特征信息的二值掩模图像;该二值掩模图像通过与原始舌体图像相乘(即二值掩模图像覆盖在原始图像上),得到了附有舌体分割特征信息的新舌体图像。作为优选,步骤(3)中将图像对随机分为训练图像对集和测试图像对集,其中训练图像对集与测试图像对集的数量比为1-10:1,优选为2-8:1,更优选为3-6:1。在本申请中,训练图像对集与测试图像对集的数量比为4:1.作为优选,数据集增强包括图像的旋转、填充及裁剪。在本申请中,通过对输入的图像进行数据集增强处理,提高单目标语义分割神经网络对训练图像对集和测试图像对集的像素处理能力,使得单目标语义分割神经系统能够更充分的学习到对舌体的分割。与现有技术相比,本发明具有以下有益效果:1、能够快速实现人工标注大图像的工作,而且只需划取舌体目标框及标注部分点就能标注高精度图像,减少操作工作量;2、该方法采用深度神经网络学习数据深层特诊,能有效提高较大图像分割速率,提升分割精度;3、对小目标舌体也能有较好分割效果,而且不需对初始图像进行变形或裁剪,减小舌诊后续操作的误差。4、该方法对数据进行了增强,减少了舌图像变形或倾斜带来的分割难度,进一步提高模型泛化性。附图说明图1为基于深度学习的舌体分割方法总流程图;图2为基于改进的grabcut算法标注舌体图像流程图;图3为单区域舌体深度分割网络模型图。具体实施方式根据本发明的实施方案,提供一种基于单目标区域分割的舌体图像分割方法:一种基于单目标区域分割的舌体图像分割方法,该方法包括以下步骤:(1)原图像获取:通过图像采集模块采集舌体原图像;(2)图像标注:通过图像标注模块,采用超像素改进的grabcut算法对采集的每一张舌体原图像进行人工标注,获得与每一张舌体原图像对应的标注图像;(3)图像制作:通过图像制作模块,将进行人工标注后的图像与对应的舌体原图像组成图像对;为提高模型泛化性,随机将原图像对作为训练集图像,剩余图像对作为测试集图像;(4)训练神经网络:通过训练集图像,对单目标语义分割神经网络进行训练;(5)测试神经网络:利用训练好的的单目标语义分割神经网络对舌体图像进行分割,通过测试集图像对单目标语义分割神经网络进行测试。作为优选,步骤(1)具体为:舌体原图像来自于智能移动设备及未固定的摄像机设备。作为优选,步骤(2)中所述人工标注具体为:①、对所采集的图像进行归一化处理;②、利用分水岭算法对采集的图像进行超像素分割;③、将超像素分割后的图像,通过grabcut算法实现半自动分割;④、最后对grabcut算法所得的图像结果微调,得到所需的人工标注图。作为优选,步骤(3)中所述图像制作的步骤包括:数据集增强和随机分配;具体为:对进行人工标注后的图像与对应的舌体原图像进行数据集增强处理,然后将处理后的经过标注后的图像与对应的舌体原图像组成图像对,将图像对随机分为训练图像对集和测试图像对集,获得训练图像对集和测试图像对集。作为优选,步骤(4)中所述单目标语义分割神经网络包括特征提取卷积神经网络、定位框预测神经网络以及掩模预测全卷积神经网络。作为优选,步骤(4)具体为:采用sgd优化训练单目标语义分割神经网络;sgd中的损失函数为目标检测损失加图像分割损失以及权值正则化损失,损失函数losstotal为:losstotal=lossroi+αlossfcn+β||w||(1);其中:lossroi为定位框预测网络的误差,lossroi=1-iouroi;定位框真实值和预测值得交并比iouroi为:iouroi由式(2)计算:squarepre为预测的定位框,squarereal为实际的定位框;squarepre∩squarereal为实际区域被正确分类的像素个数;squarepre∪squarereal为实际区域及预测出区域的像素点总像素个数;其中:lossfcn为掩模预测误差,lossfcn=1-ioufcn;掩模真实值和预测值的交并比ioufcn为:ioufcn由式(3)计算:areapre表示预测的舌体区域,areareal表示实际的舌体区域;areapre∩areareal为实际掩模被正确分类的像素个数areapre∪areareal为实际掩模及预测出掩模的像素点总个数通过损失函数分别计算预测值与给定真实值之间的误差,利用反向传播算法将误差层层回传,再通过随机梯度下降法对每层的参数进行调整和更新,更新公式如下所示,使得网络的预测值更接近真实值:网络的权重变量w为:w由(4)计算:式中,w为更新后的参数值,w′为更新前的参数值,其采用标准正态分布来初始化值;losstotal为式(1)中,通过损失函数计算得到的误差值,可简要表示为losstotal=f(w|i,iy),其中i为原始图像,iy为掩模标签图像,故w与losstotal相互迭代更新;θ为学习率,θ=1.0e-iter/5000-5,θ根据迭代次数iter的增加而减小。其中:α为第一自定义权重、β为第二自定义权重,反应训练过程中各类误差所占比重;在模型学习中,掩模误差应该占较大比重,所以设置α∈(1,20),β∈(0.1,1.2),β||w||是权重正则化损失,总损失增加β||w||,使得网络能够自动削弱不重要的特征,有效减少过拟合风险。作为优选,步骤(5)具体为:采用步骤(4)训练好的单区域舌体深度分割网络计算输入的图像的二值掩模图像,将掩模图像与原图像相乘得到分割后并截取定位框位置的图像作为舌体分割结果。作为优选,步骤(3)中将图像对随机分为训练图像对集和测试图像对集,其中训练图像对集与测试图像对集的数量比为1-10:1,优选为2-8:1,更优选为3-6:1。作为优选,数据集增强包括图像的旋转、填充及裁剪。实施例1一种基于单目标区域分割的舌体图像分割方法,该方法包括以下步骤:(1)原图像获取:通过图像采集模块采集舌体原图像;(2)图像标注:通过图像标注模块,采用超像素改进的grabcut算法对采集的每一张舌体原图像进行人工标注,获得与每一张舌体原图像对应的标注图像;(3)图像制作:通过图像制作模块,将进行人工标注后的图像与对应的舌体原图像组成图像对;为提高模型泛化性,随机将原图像对作为训练集图像,剩余图像对作为测试集图像;(4)训练神经网络:通过训练集图像,对单目标语义分割神经网络进行训练;(5)测试神经网络:利用训练好的的单目标语义分割神经网络对舌体图像进行分割,通过测试集图像对单目标语义分割神经网络进行测试。作为优选,步骤(1)具体为:舌体原图像来自于智能移动设备及未固定的摄像机设备。作为优选,步骤(2)中所述人工标注具体为:①、对所采集的图像进行归一化处理;②、利用分水岭算法对采集的图像进行超像素分割;③、将超像素分割后的图像,通过grabcut算法实现半自动分割;④、最后对grabcut算法所得的图像结果微调,得到所需的人工标注图。作为优选,步骤(3)中所述图像制作的步骤包括:数据集增强和随机分配;具体为:对进行人工标注后的图像与对应的舌体原图像进行数据集增强处理,然后将处理后的经过标注后的图像与对应的舌体原图像组成图像对,将图像对随机分为训练图像对集和测试图像对集,获得训练图像对集和测试图像对集。作为优选,步骤(4)中所述单目标语义分割神经网络包括特征提取卷积神经网络、定位框预测神经网络以及掩模预测全卷积神经网络。作为优选,步骤(4)具体为:采用sgd优化训练单目标语义分割神经网络;sgd中的损失函数为目标检测损失加图像分割损失以及权值正则化损失,损失函数losstotal为:losstotal=lossroi+αlossfcn+β||w||(1);其中:lossroi为定位框预测网络的误差,lossroi=1-iouroi;定位框真实值和预测值得交并比iouroi为:iouroi由式(2)计算:squarepre为预测的定位框,squarereal为实际的定位框;squarepre∩squarereal为实际区域被正确分类的像素个数;squarepre∪squarereal为实际区域及预测出区域的像素点总像素个数;其中:lossfcn为掩模预测误差,lossfcn=1-ioufcn;掩模真实值和预测值的交并比ioufcn为:ioufcn由式(3)计算:areapre表示预测的舌体区域,areareal表示实际的舌体区域;areapre∩areareal为实际掩模被正确分类的像素个数;areapre∪areareal为实际掩模及预测出掩模的像素点总个数;通过损失函数分别计算预测值与给定真实值之间的误差,利用反向传播算法将误差层层回传,再通过随机梯度下降法对每层的参数进行调整和更新,更新公式如下所示,使得网络的预测值更接近真实值:网络的权重变量w为:w由(4)计算:式中,w为更新后的参数值,w′为更新前的参数值,其采用标准正态分布来初始化值;losstotal为式(1)中,通过损失函数计算得到的误差值,可简要表示为losstotal=f(w|i,iy),其中i为原始图像,iy为掩模标签图像,故w与losstotal相互迭代更新;θ为学习率,θ=1.0e-iter/5000-5,θ根据迭代次数iter的增加而减小。其中:α为第一自定义权重、β为第二自定义权重,反应训练过程中各类误差所占比重;在模型学习中,掩模误差应该占较大比重,所以设置α=2,β=0.5,β||w||是权重正则化损失,总损失增加β||w||,使得网络能够自动削弱不重要的特征,有效减少过拟合风险。作为优选,步骤(5)具体为:采用步骤(4)训练好的单区域舌体深度分割网络计算输入的图像的二值掩模图像,将掩模图像与原图像相乘得到分割后并截取定位框位置的图像作为舌体分割结果。只是作为优选,步骤(3)中将图像对随机分为训练图像对集和测试图像对集,其中训练图像对集与测试图像对集的数量比为4:1。实施例2重复实施例1,只是α=4,β=0.7;训练图像对集与测试图像对集的数量比为5:1。实施例3重复实施例1,只是α=5,β=1.0;训练图像对集与测试图像对集的数量比为6:1。实施例4重复实施例1,只是α=3,β=1.0;训练图像对集与测试图像对集的数量比为3:1。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1