一种基于数据驱动的工业生产过程故障诊断方法与流程
本发明属于工业生产过程诊断领域,更具体地,涉及一种基于数据驱动的工业生产过程故障诊断方法。
背景技术:
工业生产过程系统越来越复杂,各个流程工序相互关联、相互影响,一旦其中任何一个过程出现故障,会导致系统功能失效,影响正常生产,造成企业重大经济损失,严重时还会造成人员安全事故,给国家和人民带来损失。因此,从安全生产和企业经济效益的角度来说,通过对工业生产过程数据的分析进行故障诊断是十分必要的。
现有的故障诊断方法可以分为基于机理模型的方法、基于知识的方法、基于信号处理的方法和基于人工智能的方法。基于机理模型的方法具有良好诊断效果的前提是建立精确的模型,随着生产制造系统的集成化与复杂化,构建这些系统的精确机理模型是很困难的,基于机理模型的方法在实际应用中很难起到良好的诊断效果。基于知识的方法是将故障诊断相关的专家经验知识进行处理,模拟人的决策方式,实现复杂系统的智能化诊断。这种方法构建的模型大部分不具有自我学习能力,不能满足需求。基于信号处理的方法是对信号进行处理和特征提取来进行故障诊断,但是没有固定的特征提取方案,不同类型数据的特征提取方式不近相同。近年来,基于人工智能的方法逐渐兴起,提高了诊断效率和识别率。但在使用人工智能方法对工业生产过程数据进行故障诊断时,人工智能算法的模型和模型参数往往需要优化,如果优化效果不好,则会降低故障诊断的准确率,诊断结果与实际偏差较大。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于数据驱动的工业生产过程故障诊断方法,由此解决现有的故障诊断方法诊断结果偏差大,以及诊断算法的参数优化效率低的技术问题。
为实现上述目的,本发明提供了一种基于数据驱动的工业生产过程故障诊断方法,包括:
(1)计算工业生产过程中的多维数据的平均偏差和方差,以对工业生产过程中的多维数据进行特征提取,得到特征数据,由所述特征数据构建原始输入样本集;
(2)利用原始输入样本集,使用训练好的随机森林模型,对待诊断工业生产过程进行故障诊断,得到诊断结果;
(3)根据诊断结果是否有故障,以及故障类型,对待诊断工业生产过程故障产生的原因进行分析和解决。
优选地,步骤(1)包括:
选取工业生产过程中的变量ak从t时刻开始的连续h个值,计算这h个值与该变量ak的偏差,然后将这些偏差的平均值作为特征值et,k,另外再计算这h个值与该变量ak的方差,并将这些方差的平均值作为另一个特征值
优选地,所述步骤(2)的训练好的随机森林rf模型,训练过程包括:
(2.1)计算经过标记的工业生产过程中的多维数据的平均偏差和方差,以对工业生产过程中的多维数据进行特征提取,得到特征数据,由所述特征数据构建原始输入样本集;
(2.2)采用粒子群算法优化所述随机森林模型的参数,将利用所述原始输入样本集得到的分类正确率最高的随机森林模型参数作为所述随机森林模型的最优参数组合,得到训练好的随机森林模型,以通过训练好的rf模型对待诊断工业生产过程进行故障诊断,其中,所述随机森林模型中的参数包括决策树棵数n和特征子集大小κ。
优选地,标记的工业生产过程中的多维数据是指已知生产过程状态是正常状态的数据还是故障状态的数据,以及是属于哪一种故障状态。
优选地,步骤(2.2)包括:
(2.2.1)初始化参数,随机为粒子种群中的每个粒子指定初始位置和速度参数,预设最大迭代次数、粒子位置的限定范围、粒子速度的限定范围及粒子种群规模,其中,以空间向量(n,κ)作为所述粒子种群中的粒子,空间向量(n,κ)是由rf的2个关键参数:决策树棵树n和特征集大小κ组成,粒子i的位置为(xi,n,xi,κ),xi,n代表随机森林决策树棵树,xi,κ代表随机森林特征子集大小,粒子i的速度为(vi,n,vi,κ);
(2.2.2)利用bootstrap抽样方法,对步骤(2.1)所述原始输入样本集进行m次有放回的抽取操作,得到与原始输入样本集具有相同样本数m的训练输入样本集,重复xi,n次bootstrap抽取操作,得到xi,n个训练输入样本集,用得到的xi,n个训练输入样本集依次训练xi,n个决策树,并在决策树节点分裂时,随机从特征集m中选择大小为xi,κ的特征子集,根据计算的xi,κ种分裂情况下的信息增益、信息增益率或者gini指标,选择最佳分裂特征对应的随机森林结构,得到当前粒子(xi,n,xi,κ)对应的临时随机森林模型,其中,特征集m表示原始输入样本集中的样本属性的集合,属性是指2*r个平均偏差和方差所代表的含义;
(2.2.3)利用原始输入样本集,使用当前粒子(xi,n,xi,κ)对应的临时随机森林模型,进行工业生产过程故障分类,与经过标记的工业生产过程中的多维数据对应的故障类别对比,计算粒子对于经过标记的数据样本的分类正确率,以分类正确率作为当前粒子的适应度值;
(2.2.4)更新各粒子的速度和位置,若粒子位置及速度超出了各自的限定范围,则取边界值,限制粒子速度和位置,对于更新后的每个粒子,若该粒子当前位置对应的适应度高于其历史最佳位置对应的适应度,则将当前位置作为该粒子的最佳位置;
(2.2.5)更新种群位置,将每个粒子的当前最佳位置对应的适应度与种群历史最佳位置对应的适应度进行比较,若某个粒子当前最佳位置对应的适应度值更高,则将该粒子当前最佳位置作为种群最佳位置;
(2.2.6)若迭代次数小于预设最大迭代次数,且种群的最佳适应度值小于预设阈值,则返回步骤(2.2.2)继续迭代,否则结束迭代,将得到的种群最佳位置作为随机森林模型的决策树棵树和特征子集大小的最优组合。
进一步地,步骤(3):
工业生产过程状态包括生产过程运行正常状态和生产过程处于异常故障状态,如果生产过程处于异常故障状态,根据诊断结果的异常故障类型,进行异常故障产生的原因分析,进行有针对性地解决。当某类异常故障发生次数较多时,及时反映给工业生产部门,杜绝或减少这类异常故障的发生,提高工业生产的稳定性和产品生产的质量,减少生产经营损失。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
(1)本发明可以实现基于数据驱动的工业生产过程数据的故障诊断,采用粒子群优化(particleswarmoptimization,pso)算法优化随机森林(randomforest,rf)模型关键参数,利用随机森林模型,根据工业生产过程数据,进行工业生产过程故障诊断,提高了诊断准确率。
(2)影响随机森林算法性能的关键参数有决策树棵树n和特征子集大小κ,这两个参数具体的影响随着数据的不同而有差异,为了让随机森林算法进行故障诊断时对不同的数据能自动调节参数,本发明采用了基于粒子群优化随机森林模型参数的方法,达到了在不同数据情况下,随机森林模型能自动匹配出最佳的训练参数的目的,提高了随机森林诊断算法的适应性。
(3)本发明使用粒子群算法对随机森林模型的2个关键参数:决策树棵树n和特征集大小κ进行优化,同时得到最优的2个关键参数,而不是逐个参数进行优化,提高了优化效率。
附图说明
图1是本发明实施例提供的一种基于数据驱动的工业生产过程故障诊断方法的流程示意图;
图2是本发明实施例1提供的动态平均偏差与方差处理流程示意图;
图3是本发明实施例1提供的随机森林模型的决策树示意图;
图4是本发明实施例1提供的基于粒子群算法进行随机森林模型参数的优化流程示意图;
图5是本发明实施例1提供的一种基于数据驱动的工业生产过程故障诊断方法结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
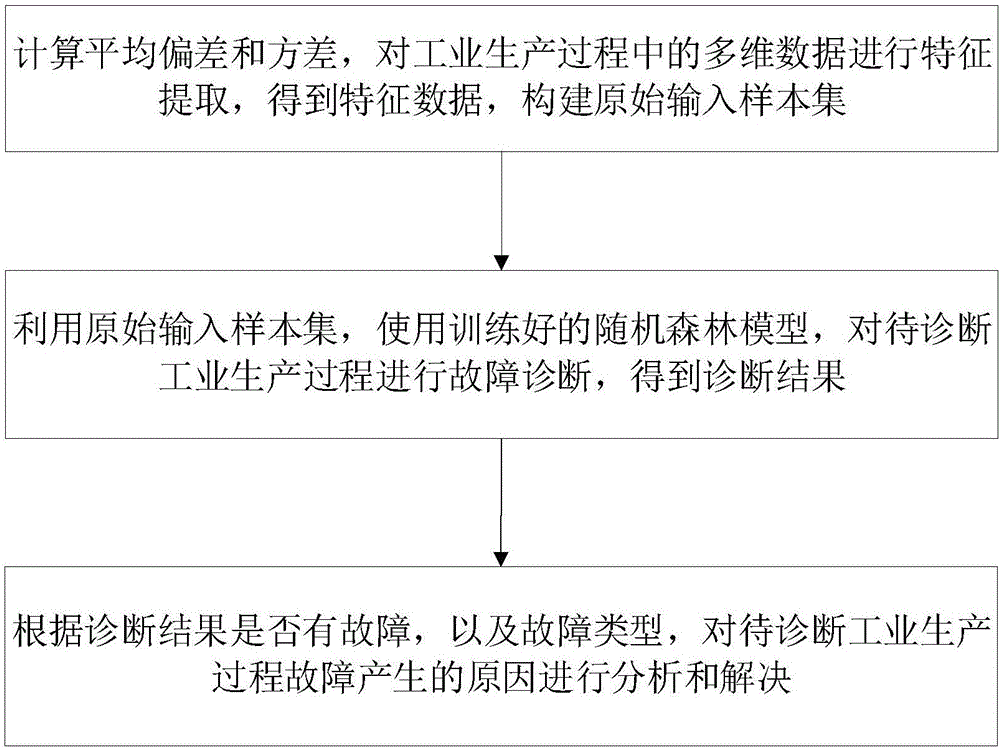
如图1所示,一种基于数据驱动的工业生产过程故障诊断方法,包括:
(1)计算工业生产过程中的多维数据的平均偏差和方差,以对工业生产过程中的多维数据进行特征提取,得到特征数据,由特征数据构建原始输入样本集;
(2)利用原始输入样本集,使用训练好的随机森林模型,对待诊断工业生产过程进行故障诊断,得到诊断结果;
(3)根据诊断结果是否有故障,以及故障类型,对待诊断工业生产过程故障产生的原因进行分析和解决。
实施例1
本发明实施例1的数据集来自流程工业的某化工公司工业生产过程数据,经过以下步骤,进行工业生产过程故障诊断:
步骤(1)计算平均偏差和方差,对工业生产过程中的多维数据进行特征提取,得到特征数据,构建原始输入样本集。图2给出了动态平均偏差与方差方法的处理流程图。具体包括以下步骤:
(1.1)首先计算正常状态时的样本均值与方差,计算公式如下所示:
其中,mk和sk分别代表工业生产过程中的第k个变量的均值和方差,vi,k代表第i个样本的第k个变量值,n代表样本总数,经过计算得到正常状态时的样本均值与方差fnormal=(m1,m2,...,s1,s2,...)。
(1.2)假设t时刻样本的数据为dt=(vt,1,vt,2,...,vt,52),窗口为n时的连续样本依次是dt-1,dt-2,...,dt-n,计算这些数据与正常状态时的平均偏差和方差,计算公式如下所示:
其中,et,k代表变量ak从t时刻开始的连续n个样本值与正常状态时的变量ak均值的平均偏差,
进一步地,对于变量ak,经过上述处理后得到2个特征值:et,k和
(1.3)为了将不同量纲的变量归一化,将(1.2)中得到的ft与(1.1)中正常状态时的样本特征fnormal进行比值处理,最终得到处理后t时刻的特征量:
将特征向量fft作为原始输入样本集ps。
步骤(2)是使用训练好的随机森林模型对工业生产过程进行故障诊断,训练过程包括:
(2.1)计算经过标记的工业生产过程中的多维数据的平均偏差和方差,以对工业生产过程中的多维数据进行特征提取,得到特征数据,由特征数据构建原始输入样本集;
(2.2)采用粒子群算法优化所述随机森林模型的参数,将利用原始输入样本集得到的分类正确率最高的随机森林模型参数作为随机森林模型的最优参数组合,得到训练好的随机森林模型,以通过训练好的rf模型对待诊断工业生产过程进行故障诊断,其中,随机森林模型中的参数包括决策树棵数n和特征子集大小κ。
进一步地,标记的工业生产过程中的多维数据是指已知生产过程状态是正常状态的数据还是故障状态的数据,以及是属于哪一种故障状态。
进一步地,用粒子群算法对随机森林rf模型的关键参数进行优化的流程如图4所示,具体步骤如下:
s1:初始化参数,设定最大迭代次数gmax,粒子位置、速度的限定范围分别为[xmin,n,xmax,n][xmin,κ,xmax,κ]和[-vmax,n,vmax,n][-vmax,κ,vmax,κ],粒子种群规模n,随机为粒子种群中的每个粒子指定初始位置和速度参数,其中,以空间向量(n,κ)作为所述粒子种群中的粒子,空间向量(n,κ)是由rf的2个关键参数:决策树棵树n和特征集大小κ组成,粒子i的位置为(xi,n,xi,κ),其中xi,n代表随机森林决策树棵树,xi,κ代表随机森林特征子集大小,粒子i的速度为(vi,n,vi,κ),vi,n表示粒子i的决策树棵树n分量的飞行速度矢量,vi,κ粒子i的特征子集大小κ分量的飞行速度矢量;
s2:利用bootstrap抽样方法,对步骤(2.1)原始输入样本集进行m次有放回的抽取操作,得到与原始输入样本集具有相同样本数m的训练输入样本集,重复xi,n次bootstrap抽取操作,得到xi,n个训练输入样本集,用得到的xi,n个训练输入样本集依次训练xi,n个决策树,并在决策树节点分裂时,随机从特征集m中选择大小为xi,κ的特征子集,根据计算的xi,κ种分裂情况下的信息增益、信息增益率或者gini指标,选择最佳分裂特征对应的随机森林结构,得到当前粒子(xi,n,xi,κ)对应的临时随机森林模型,其中,特征集m表示原始输入样本集中的样本属性的集合,属性是指2*r个平均偏差和方差所代表的含义。
本发明实施例中,采用gini指标。
具体地,属性是指工业生产过程第1个变量平均偏差的名称,…,第r个变量平均偏差的名称,第1个变量方差的名称,…,第r个变量方差的名称。
s3:利用原始输入样本集,使用当前粒子(xi,n,xi,κ)对应的临时随机森林模型,进行工业生产过程故障分类,与经过标记的工业生产过程中的多维数据对应的故障类别对比,计算粒子对于经过标记的数据样本的分类正确率,以分类正确率作为当前粒子的适应度值;
s4:更新各粒子的速度和位置,若粒子位置及速度超出了各自的限定范围,则取边界值,限制粒子速度和位置,对于更新后的每个粒子,若该粒子当前位置对应的适应度高于其历史最佳位置对应的适应度,则将当前位置作为该粒子的最佳位置;
具体地,粒子i的最佳位置pbesti=(pi,n,pi,κ),pbesti用于记录粒子i的适应度值最高的位置信息;
使用如下公式更新粒子的速度和位置:vi与xi,假如粒子位置、速度超出了设定区间,则取边界值,限制粒子速度和位置;
其中,
s5:更新种群位置,将每个粒子的当前最佳位置对应的适应度与种群历史最佳位置对应的适应度进行比较,若某个粒子当前最佳位置对应的适应度值更高,则将该粒子当前最佳位置作为种群最佳位置;
具体地,种群的最佳位置gbest=(gn,gκ),gbest用于记录群体所有粒子在迭代过程中的最高适应度值的位置信息;
s6:若迭代次数k小于预设最大迭代次数gmax,即k<gmax,且最佳适应度值小于给定阈值,则返回步骤s2继续迭代,否则结束迭代,将得到的种群最佳位置作为随机森林模型的决策树棵树和特征子集大小的最优组合。
训练完成后,数据集分类正确率最高的种群最佳位置即是所述rf模型的最优参数解,包含决策树棵树n和特征子集大小κ最优组合。本实施例中,训练完成后的最优参数:决策树棵树n=20,特征子集大小κ=14。
进一步地,bootstrap抽样方法是以原始数据为基础,分析数据的统计分布特征,适用于难以用常规方法导出对参数的区间估计、假设检验等问题。基本思想是:在原始数据的范围内作有放回的再抽样,样本容量与原始数据容量相同,原始数据中每个观察单位每次被抽到的概率相等,所得样本称为bootstrap样本。
步骤(3):工业生产过程状态包括生产过程运行正常状态和生产过程处于异常故障状态,如果生产过程处于异常故障状态,根据诊断结果的异常故障类型,进行异常故障产生的原因分析,进行有针对性地解决。当某类异常故障发生次数较多时,及时反映给工业生产部门,杜绝或减少这类异常故障的发生,提高工业生产的稳定性和产品生产的质量,减少生产经营损失。
图5是本发明所述一种基于数据驱动的工业生产过程故障诊断方法的结构图,实现基于数据驱动的工业生产过程故障诊断。首先对工业生产过程数据进行动态平均偏差与方差处理,构建成原始输入样本集,然后利用原始输入样本集,运用训练好的随机森林模型进行工业生产过程故障诊断。
利用pso算法,同时优化随机森林模型的2个关键参数,得到训练好的随机森林模型,为随机森林参数的优化提供了一种可行、高效的方法,提高了利用随机森林算法进行工业生产过程故障诊断的准确性。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!