一种基于ST-Unet的视频异常检测方法与流程
本发明属于计算机视觉和模式识别领域,涉及一种st-unet网络的视频异常检测方法。
背景技术:
随着社会的不断进步,平安城市的概念逐步成为人们最为关注的话题之一。其中,完善的监控系统是建设平安城市非常重要的一环,视频监控技术成为目前最重要的安防监控的手段和方法。目前,普遍的监控视频处理方法都还是较为初级的监控方式,即利用监控摄像头拍摄画面并提供实时显示,由监管人员实时观察监控视频,根据经验来判断是否有异常事件发生。这种监控方式不仅需要管理人员对监控视频画面时刻观察,耗费大量劳动力,且专人观察易疲劳,注意力不可能长时间集中在监控视频上,易出现漏检现象。因此,智能的高精度的视频异常检测系统成为监控管理的迫切需求。视频异常检测系统可以实时检测监控画面,当异常出现时给予管理人员警示,这不仅减少人力资源的投入,还使得实时处理所有拍摄摄像头传回的大量的视频数据成为可能,更好的维护社会治安,建设平安城市。
由于日常监控视频数据中大多为正常事件,异常事件很少发生且异常事件类型多种多样、难以预测,故现有的异常检测算法均基于非监督和半监督的方法,且非监督的异常检测算法种大多基于自编码器的结构。针对视频数据强时空相关性的特点,部分算法又在自编码器中加入lstm结构来增强算法在时间上的建模能力,但这种提取特征后再进行时间上建模的方法仍忽略了许多时候视频数据的时空特征。
技术实现要素:
针对现有算法的不足,本发明提出一个高精度的基于st-unet网络的视频异常检测算法。在unet网络中加入convlstm结构,即利用了unet网络对输入数据多尺度建模的特点,又加入convlstm加强对输入数据时间上的建模。相较于现有算法,本发明提出的st-unet网络对视频类具有强时空相关性的数据有很好的建模作用,在视频异常检测问题方面有较高的准确率。
本发明提供一种高精度基于st-unet网络的视频异常检测算法,包括以下步骤:
1、预处理
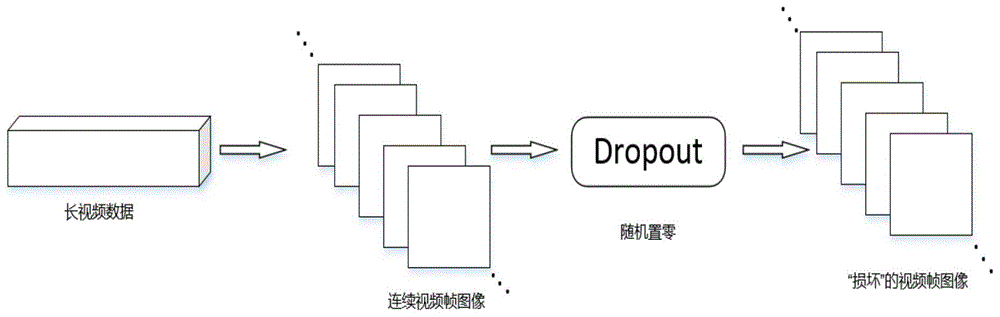
首先,将原始的长视频数据切分成单帧的视频帧图像。其次,对切分好的视频帧利用dropout层进行“损坏”处理,即随意使输入的视频帧的某些值置零。
2、构造st-unet网络
本发明所构建的网络结构为:
输入层,两层卷积层(c1、c2),第一次下采样(p1),两层卷积层(c3、c4),第二次下采样(p2),两层卷积层(c5、c6),第三次下采样(p3);三层convlstm层(l1、l2、l3);第一次上采样(u1),两层卷积层(c6、c7),第二次上采样(u2),两层卷积层(c8、c9),第三次上采样(u3),两层卷积层(c10、c11),输出层。形成一个前后对称的且加有长短时记忆的u型深度网络构架,st-unet。
3、利用st-unet网络实现基于重构和预测的视频异常检测算法
训练过程:
对训练集中的原始长视频切分成单帧视频帧,并做“损坏”预处理。将预处理后的连续四帧视频帧输入到st-unet网络中,分别训练得到重构st-unet网络和预测st-unet网络。通过最小化输入的视频帧图像与重构图像、预测未来帧图像与真正未来帧图像之间的差值来进行网络优化。并利用生成对抗模型,将重构图像、预测未来帧图像与对应的groundtruth同时输入到判别模型中让判别网络进行判别。st-unet网络与判别模型共同训练,最终使得判别模型无法辨别输入的是(重构、预测)生成的图像还是原始groundtruth,进一步优化st-unet网络,提高准确性。
测试过程:
将测试集中的原始长视频切分成单帧视频帧,然后直接输入到训练好的重构st-unet网络和预测st-unet网络中,分别得到重构图像、预测图像。通过比较输入图像与重构图像得到重构误差。通过比较输入图像与预测图像得到预测误差。
为进一步提高算法准确率,本算法对得到的重构误差和预测误差进行加权处理,计算得最终的异常分数。通过比较异常分数与所设阈值之间的差异,来判定该输入的视频帧是否属于异常。
有益效果
1、本发明对输入的视频帧数据采用“损坏”预处理
为提高网络的泛华能力,使其提取最为重要的数据特征,本发明对输入的视频帧图像进行“损坏”处理。通过训练,使得网络不仅可以对输入的完整视频帧进行处理,当输入“受损”、“含噪”的视频帧时,它亦可以提取出关键的重要的特征进行处理,提高算法的准确性。
2、本发明提出st-unet网络
unet网络的特点在于其在上采样的过程中,每上采样一次就和特征提取部分(即下采样过程)对应的相同尺度的输出进行融合,故unet网络在空间上对输入图像有很好的建模效果,但对于视频异常检测这类输入数据具有强时间相关性的问题,本发明提出的st-unet网络,在unet网络中加入convlstm层来加强对输入数据时间上特征的提取,更适合处理该类问题。
3、本发明利用st-uet网络实现基于重构和预测的视频异常检测算法
现有视频异常检测的重构算法均基于卷积自编码器来实现(即卷积提取特征后再反卷积进行重构),其中也包括在卷积层最后加入convlstm来加强时间上特征联系的方法,但这种提取特征后进行时间建模的方法仍丢失了部分时空特征信息。本发明提出利用st-unet网络进行视频帧重构,该方法比自编码器利用更多尺度的空间特征信息进行重构,且在时间上也较强的特征提取能力。
目前已有利用unet网络进行预测未来帧,并通过预测误差来进行视频异常检测的算法,但该算法只注重了对于输入视频数据空间上特征的提取,忽略了输入视频数据在时间上的强相关性。本发明利用提出的st-unet网络进一步改进基于预测的视频异常检测算法,提高视频异常检测的精度。
4、基于重构和预测的视频异常联合检测算法
为进一步提高准确率,本发明在分别得到重构误差及预测误差后,进行两误差值的加权平均处理,将取平均后的值作为最后的异常分数值。该处理综合考虑了重构算法及预测算法所得结果,除预测未来帧外又进行了当前帧的重构,联合判别,进一步提高了算法的准确率。
附图说明:
图1为本发明预处理网络图。
图2为本发明st-unet网络图。
图3为本发明利用st-unet实现重构算法的训练流程图。
图4为本发明利用st-unet实现预测算法的训练流程。
图5为本发明算法测试流程图。
具体实施方法
下面结合附图对本发明的具体实施方法进行详细说明。
1、预处理
将连续的长视频切分成单一的视频帧图像,并将切分好的视频帧图像输入到由单一dropout层构成的预处理网络中,得到预处理后的“损坏”视频帧图像数据。具体网络结构如图1所示,其中dropout层的keep_prob设置为0.8。
2、构建st-unet网络
如图2所示。本发明所构造的st-unet网络的各层具体参数如下:
①、c1、c2两卷积层:输入尺寸为256×256,输入通道数为3,卷积核为3×3,步长为1,边缘填充方式为‘valid’,激活函数为relu,输出尺寸为256×256,输出通道数为64。
②、p1下采样层:输入尺寸为256×256,输入通道数为64,池化核为2×2,步长为1,边缘填充方式为‘same’,输出尺寸为128×128。
③、c3、c4两卷积层:输入尺寸为128×128,输入通道数为64,卷积核为3×3,步长为1,边缘填充方式为‘valid’,激活函数为relu,输出尺寸为128×128,输出通道数为128。
④、p2下采样层:输入尺寸为128×128,输入通道数为128,池化核为2×2,步长为1,边缘填充方式为‘same’,输出尺寸为64×64,
⑤、c5、c6两卷积层:输入尺寸为64×64,输入通道数为128,卷积核为3×3,步长为1,边缘填充方式为‘valid’,激活函数为relu,输出尺寸为64×64,输出通道数为256。
⑥、p3下采样层:输入尺寸为64×64,输入通道数为256,池化核为2×2,步长为1,边缘填充方式为‘same’,输出尺寸为32×32。
⑦、l1convlstm层:输入尺寸为32×32,输入通道数为256,卷积核为3×3,输出尺寸为32×32,输出通道数为512。
⑧、l2、l3两convlstm层:输入尺寸为32×32,输入通道数为512,卷积核为3×3,输出尺寸为32×32,输出通道数为512。
⑨、u1反卷积层:输入尺寸为32×32,输入通道数为512,卷积核为2×2,步长为2,边缘填充方式为‘same’,输出尺寸为64×64。
⑩、将u1反卷积后的结果与对应尺寸的c6卷积的结果进行拼接,拼接维度为3。
3、基于st-unet的视频异常检测算法
1)、st-unet重构算法的训练过程
如图3所示,本发明利用st-unet网络实现基于重构的视频异常检测算法具体训练过程如下:
①、随机选取预处理后的连续四帧图像作为输入,并选取四帧中最后一帧图像所对应的原始帧图像作为真值(groundtruth)。
②、将四帧图像分别输入到st-unet网络中,四帧图像在网络中最后一次下采样部分结束后得到四个特征图,接着将这四个特征图作为网络中convlstm部分的输入,之后得到包括之前四帧信息的一个特征图,对该特征图进行网络中全部反卷积操作,得到最终的输出结果-重构图像。
③、比较重构图像与原始真值图像(groundtruth)之间的差异。本发明采用灰度损失函数(intensity_loss)、梯度损失函数(gradient_loss)来比较重构图像与原值真值图像之间的差异,并在训练过程中通过最小化全局损失函数值(global_loss)对网络参数进行调整。具体计算公式如下:
global_loss=lint*intensity_loss+lgra*gradient_loss(3)
公式(1)(2)中,i*为重构得到的图像,i为原始真值图像。
公式(2)中,i,j分别为空间上水平与垂直方向索引。
公式(3)中,lint、lgra分别为intensity_loss和gradient_loss在全局损失函数(global_loss)中所占权重。本发明取lint=2、lgra=1。
④、为进一步优化网络参数,引入判别模型。将重构图像与原始真值图像输入到同一判别模型中,由判别模型进行特征提取并判断其输入为重构图像还是原始真值图像。将判别模型与st-unet重构模型一同训练,目的是使判别模型无法分辨st-unet重构得到的图像与原始真值图像,从而进一步提高st-unet重构算法的准确性。
判别模型由四层卷积层以及一输出层组成,其训练过程损失函数计算公式如下:
公式(4)中,i,j为空间方向索引,d(i)为判别网络输出,lmes为均方误差,定义如下:
lmes(y*,y)=(y*-y)2(5)
2)、st-unet预测算法的训练过程
如图4所示,本发明利用st-unet网络实现基于预测的视频异常检测算法具体训练过程如下:
①、不同于重构算法,预测算法中需随机选取预处理后的连续五帧图像,前连续的四帧图像作为输入,并最后一帧图像所对应的原始帧图像作为真值(groundtruth)。
②、余下训练过程同重构训练算法1)中的步骤②③④。
3)、基于st-unet异常检测算法的测试过程
如图5所示,本发明利用st-unet网络实现基于重构和预测的视频异常检测算法具体测试过程如下:
①、将测试集中的长视频切分成单一的视频帧图像。
②、对于测试帧it,将it帧与之前的连续三帧(it-1、it-2、it-3)合并成四帧图像输入到训练好的st-unet重构网络中,得到重构图像
峰值信噪比(psnrs)与异常分数值(scores)的具体计算公式如下:
公式(7)中,it为输入的第t帧图像,
③、对于测试帧it,将it帧与it-1、it-2、it-3三帧以及it+1合并为连续的五帧输入到训练好的st-unet预测网络中,得到预测的未来帧
④、为进一步提高异常检测的准确率,本发明将重构算法结果与预测算法结果进行联合判别,取重构异常分数值和预测异常分数值加权作为最终的异常分数(anomal_scores),具体计算公式如下:
anomal_scores=lpre*scores_pre+lres*scores_res(8)
公式(8)中,lpre、lres为预测异常分数和重构异常分数的加权值。本发明取lpre=0.5、lres=0.5。
⑤、求得测试帧it的异常分数(anomal_scores)后,将该值与设置的阈值(threshold)进行比较。若anomal_scores≥threshold,测试帧it为异常视频帧。anomal_scores<threshold,测试帧it为正常视频帧。本发明取threshold=0.679
⑥、对所有切分好的单一视频帧重复步骤②③④⑤,将测试视频中所有的异常帧检测出来,实现视频异常检测。
- 还没有人留言评论。精彩留言会获得点赞!