一种身份证信息提取方法与流程
本发明涉及信息提取技术领域,尤其是一种身份证信息提取方法。
背景技术:
随着信息时代的飞速发展,作为人口信息行之有效的管理工具——身份证,已经深入到了社会生活的方方面面。身份证是我国居民身份的象征。目前身份证登记大多采用人工录入的方式。这不但耗时,而且效率非常低下。因此,如何利用计算机技术,高速、有效、完整地录入个人信息,并进行相应的管理和验证成为许多信息系统中急需解决的问题。
身份证信息提取系统,在服务型行业、交通与公安系统有着很大需求,它可以加速完成身份证编号及个人信息快速有效的输入,并通过相应的信息管理系统进行查询,验证等操作,同时还可以联网将信息上传到公安部,便于掌握流动人口的动向,进一步统计查询和管理。这一切都将有利于推动相关部门的办公信息化与网络化。
身份证信息提取过程中,如何提取身份证的文本位置并识别其中的文本是关键,常用的特征提取方法有基于重心、粗网络、投影、笔画穿越密度、文字轮廓等,但是这些提取方法的存在抗干扰能力差的特点,对畸形移位变换不敏感。
身份证信息提取技术中,对于图片的预处理是一个相当重要的步骤,影响最终的识别效果,预处理最重要的过程是对身份证图像的旋转矫正,矫正不正确会大大影响后面的文本提取与识别。
身份证信息提取技术中,对提取出的文本区域进行识别的方法一般是把该区域进行单字分割,进而识别单个字符,但是单子分割过程中会出现分割出的字符增多或减少,导致后面的文本识别结果不准确。
技术实现要素:
有鉴于此,本发明的目的是在于提供一种身份证识别方法,可以解决现有技术中图片旋转不准确,单字分割成功率不高和抗干扰能力差的问题。
本发明的技术方案为:
一种身份证信息提取方法,包括如下步骤:
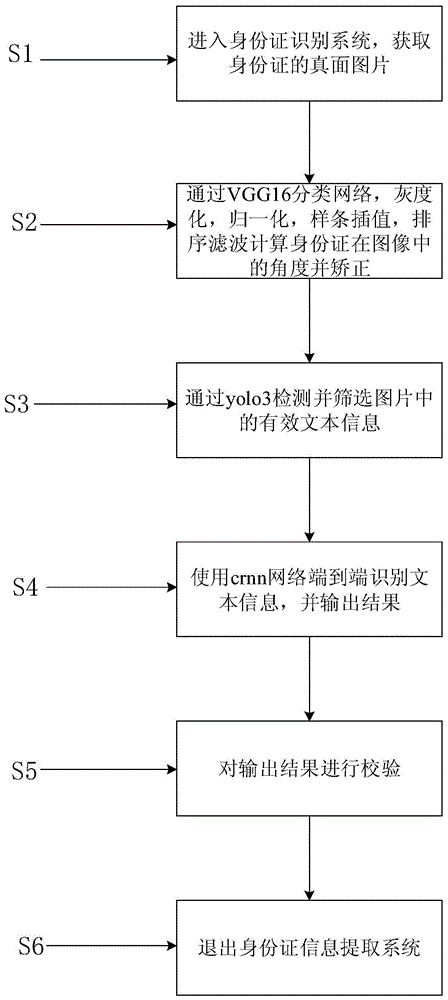
s1:进入身份证识别系统,获取身份证的真面图片;
s2:通过vgg16分类网络,灰度化,归一化,样条插值,排序滤波计算身份证在图像中的角度并矫正;
s3:通过yolo3检测并筛选图片中的有效文本信息;
s4:使用crnn网络端到端识别文本信息,并输出结果;
s5:对输出结果进行校验;
s6:退出身份证信息提取系统。
进一步,所述步骤s1的操作过程为:
s11:使用摄像头拍摄身份证的正面图片;
s12:把图片通过网络上传至云端接口。
再进一步,所述步骤s2的操作过程为:
s21:通过训练vgg16四分类模型粗略矫正图片模型,角度分类:0°,90°,180°,270°;
s22:对输入的rgb图像进行灰度化得到灰度图,计算公式如下:
gray(i,j)=[r(i,j)+g(i,j)+b(i,j)]/3(1)
s23:对灰度化图片的像素采用min-max归一化,xnew=(xold-min)/(max-min),其中xnew表示归一化之后的数据,xold表示归一化之前的数据,min表示该数据的一列特征中的最小值,max表示一列特征中的最大值;
s24:通过样条插值对图像进行相应比例的缩放,可以在不失去图片像素特征的前提下减小图片的大小;
s25:通过排序滤波器对图片提取出背景像素,通过像素的减法减去背景区域,最后图片中只剩下文本像素;
s26:在-15°~15°范围内每个整数度数取值,分别以此角度进行旋转,对旋转后的二维的图片矩阵以第二维度为轴求均值,得到一维的均值数组,对一维均值求其方差得到最后的值,记录每个角度对应的方差值,方差最大的就是图片所需要旋转的角度;
二维数组求均值公式如下,a[m][n]为m行n列的数组,b[m][1]为m行1列的数组:
b[m][1]=mean(a[m][n])(2)
一维数组求方差公式如下,b[m][1]为m行1列的数组,c[1]为1行1列的常数:
c[1]=var(b[m][1])(3)。
更进一步,所述步骤s3的操作过程为:
s31:通过网上收集图片,并用ctpn算法检测出的文本信息作为训练集训练yolo3文本检测模型;
s32:通过yolo3模型可以粗略定位图片中的文本位置,得到文本区域位置信息与可信度信息;
s33:设置置信区间阈值,删除低于此阈值的文本区域,过滤重复的文本区域,合并左右相邻的文本行,最后过滤低于最小文本长度的文本区域,输出剩余的文本结果。
优选地,所述步骤s4的操作过程为:
s41:收集身份证识别所需要的文本库,作为训练标签;
s42:网上收集不同环境下的文本图片作为训练集,训练得到yolo3的文本端到端识别模型;
s43:输入s4得到的文本,得到输出结果。
本发明中,本身份证信息提取系统,使用yolo3的目标检测方法检测文本可以很好地解决抗干扰能力差、对畸形移位变换不敏感的问题。
在该身份证信息提取系统中,通过vgg16模型进行角度的粗矫正,再通过灰度化,归一化,样条插值,排序滤波对身份证图像进行精准的矫正,可以很好地解决无法矫正图片和校正精度不高的问题。
在该身份证信息提取系统中,采用卷积网络与递归网络结合的模型可以实现端到端的识别字符,减少了分割字符的操作,提高了准确率。
与现有技术相比,本发明提供的一种身份证信息提取方法,具有如下有益效果:
(1)通过vgg16四分类模型进行粗角度矫正,对粗矫正的图片进行灰度化,归一化,样条插值,排序滤波的操作可以进行精准的角度矫正,可以很好地的解决无法对歪斜图片进行矫正并提取信息的问题。
(2)通过yolo3模型可以在复杂背景下提取身份证的信息区域,解决字符位置定位的抗干扰能力差,普适性低的问题;
(3)通过crnn模型可以减少对文本区域进行单字分割的步骤,提高文本识别结果的准确率。
附图说明
图1为本发明的方法流程图。
具体实施方式
下面结合附图和具体实施方式,对本发明做进一步说明。
参照图1,一种身份证信息提取方法,以身份证公安部门进行身份证信息提取为例,包括如下步骤:
s1:进入身份证识别系统,获取身份证的真面图片;
其中步骤s1的操作过程为:
s11:使用摄像头拍摄身份证的正面图片;
s12:把图片通过网络上传至云端接口;
s2:通过vgg16分类网络,灰度化,归一化,样条插值,排序滤波器计算身份证在图像中的角度并矫正;
其中步骤s2的操作过程为:
s21:通过训练vgg16四分类模型粗略矫正图片模型,角度分类:0°,90°,180°,270°;
s22:对输入的rgb图像进行灰度化得到灰度图,计算公式如下:
gray(i,j)=[r(i,j)+g(i,j)+b(i,j)]/3(1)
s23:对灰度化图片的像素采用min-max归一化,xnew=(xold-min)/(max-min),其中xnew表示归一化之后的数据,xold表示归一化之前的数据,min表示该数据的一列特征中的最小值,max表示一列特征中的最大值;
s24:通过样条插值对图像进行相应比例的缩放,可以在不失去图片像素特征的前提下减小图片的大小;
s25:通过排序滤波器对图片提取出背景像素,通过像素的减法减去背景区域,最后图片中只剩下文本像素;
s26:在-15°~15°范围内每个整数度数取值,分别以此角度进行旋转,对旋转后的二维的图片矩阵以第二维度为轴求均值,得到一维的均值数组,对一维均值求其方差得到最后的值,记录每个角度对应的方差值,方差最大的就是图片所需要旋转的角度;
二维数组求均值公式如下,a[m][n]为m行n列的数组,b[m][1]为m行1列的数组:
b[m][1]=mean(a[m][n])(2)
一维数组求方差公式如下,b[m][1]为m行1列的数组,c[1]为1行1列的常数:
c[1]=var(b[m][1])(3)
s3:通过yolo3检测并筛选图片中的有效文本信息;
其中步骤s3的操作过程为:
s31:通过网上收集图片,并用ctpn算法检测出的文本信息作为训练集训练yolo3文本检测模型;
s32:通过yolo3模型可以粗略定位图片中的文本位置,得到文本区域位置信息与可信度信息;
s33:设置置信区间阈值,删除低于此阈值的文本区域,过滤重复的文本区域,合并左右相邻的文本行,最后过滤低于最小文本长度的文本区域,输出剩余的文本结果;
s4:使用crnn网络端到端识别文本信息,并输出结果;
其中步骤s4的操作过程为:
s41:收集身份证识别所需要的文本库,作为训练标签;
s42:网上收集不同环境下的文本图片作为训练集,训练得到yolo3的文本端到端识别模型;
s43:输入s4得到的文本,得到输出结果;
s5:对输出结果进行校验;
s6:退出身份证信息提取系统。
本发明提供一种身份证信息提取方法,通过摄像头拍摄身份证正面图片,上传至云端,通过vgg16四分类模型对图片进行角度的粗矫正,然后使用灰度化,归一化,样条插值,排序滤波的方法对图片进行精准的角度矫正,有效地解决图片的矫正不成功或矫正精度低的问题。通过yolo3模型可以准确定位出文本的位置,对于复杂的背景图片也有很高的准确率,可以解决文本位置提取的抗干扰能力差,普适性低的问题。通过crnn模型可以实现端到端的文字识别功能,免去单字切割的步骤,可以解决因为需要单字切割造成的识别结果下降的问题。对最后的输出结果做调整并输出,该方案很好地提高了身份证信息提取的准确率。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!