一种终端辅助SWOT指标体系的构建方法与流程
本发明涉及终端集中存储领域,具体为一种终端辅助swot指标体系的构建方法。
背景技术:
swot分析方法(其中strengths:内部优势因素,weakness:内部弱势因素,opportunities:外部机遇因素,threats:外部威胁因素)是一种经典的竞争情报分析工具,由哈佛商学院的k.j.安德鲁斯于1971年在其《公司战略概念》一书中提出。该方法的主要内容是围绕着分析目标进行广泛地调查与信息收集,然后对收集到的信息予以分析,判断影响目标的外部机遇及外部威胁,目标实施的内部优势和劣势四方面因素。swot分析方法既可以进行简单的初步分析,定性地了解分析目标的总体概况,同时也可以实现目标的战略策略形成,实施或控制决策。
由于swot分析方法从分析目标总体出发,可以清晰地列出影响目标实施的优势、劣势、机会和威胁因素,并加以综合分析,将影响目标实施的复杂因素明朗化,决策者可以清楚地掌握目标实施中可能存在的风险与机遇,从而提高决策的准确性。因此swot分析方法现已成为现代政府部门、企业在管理与决策中最为常用的分析工具,得到了广泛的应用与研究。
基于上述技术问题需要设计一种新的终端辅助swot指标体系的构建方法。
技术实现要素:
本发明的目的是提供一种终端辅助swot指标体系的构建方法。
为了解决上述技术问题,本发明提供了一种终端辅助swot指标体系的构建方法,包括:
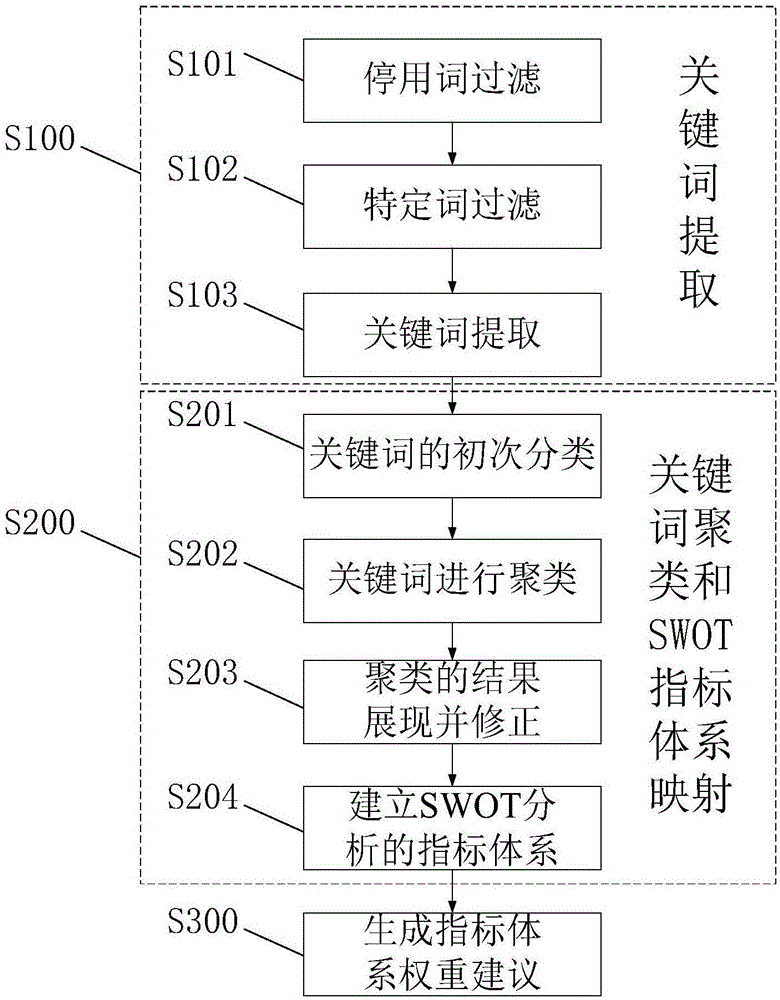
步骤s100,对文本数据集的关键词提取;
步骤s200,关键词聚类和swot指标体系映射;以及
步骤s300,生成指标体系权重建议。
进一步,所述步骤s100中对文本数据集的关键词提取的方法包括:
步骤s101,停用词过滤,对采集的文本数据集进行中文分词之后,通过积累挑选形成的停用词表,过滤文本数据中的停用词;
步骤s102,特定词过滤,通过搜索引擎对词进行搜索,对于搜索结果少于阈值的词,判断其为特定词,然后将特定词过滤;
步骤s103,关键词提取,通过改进的tf/idf算法进行关键词提取。
进一步,所述改进的tf/idf算法为:
式1
式2wi={w|tf/idf(wi)>η};
式3w=∪wi;
式4
式中,tf/idf(wi)为标号为i的文本数据中词w的tf/idf权值;tf(wi)为词w在标号为i的文本数据中出现的频数;n为文本数据集包含的文本数据数;d为包含词w的文本数据数;
所述通过改进的tf/idf算法进行关键词提取的方法包括:
通过式1计算出文本数据集中每个文本数据中包含的关键词的tf/idf权值;
根据各文本数据中关键词的tf/idf权值按大小进行排序;
提取权值大于阈值η的关键词形成标号为i的文本数据的关键词集合wi,所有文本数据的wi集合汇总为文本数据集的关键词w集合;
针对w集合中的关键词两两配对,计算比值c;
式4中tfsum(wa)指某关键词a在w集合中出现的频数累加和,tfsum(wb)是指某关键词b在w集合中出现的频数累加和,g(wa)是指该关键词a在搜索引擎中获取的检索页面结果数;g(wb)是指该关键词b在搜索引擎中获取的检索页面结果数;比值c为一对关键词a和b的tfsum值与g值的乘积的比值,并且按比值的结果对w集合中的关键词排序,并按顺序显示以对关键词加以修正。
进一步,所述步骤s200中关键词聚类和swot指标体系映射的方法包括:
步骤s201,依据中国分类主题词表,实现对关键词的初次分类,对照中国分类主题词表,将当前文本数据集中提取出的关键词进行分类,建立初始的关键词分类结构;
步骤s202,针对初步分类后,剩余的在中国分类主题词表中无法对应分类的关键词,依据词的近义程度作为词与词的距离度量,采用k_means聚类方法对剩余关键词进行聚类;
步骤s203,在终端辅助聚类完成之后,再将聚类后的关键词分类展现并修正;
步骤s204,经过对关键词聚类的重复迭代以及对聚类后的关键词分类修正后,根据聚类后的词类的分类信息,将词类映射成对应地指标,即
建立swot分析的指标体系。
进一步,所述步骤s300中生成指标体系权重建议的方法包括:选择影响指标体系权重判断的因素;
所述影响指标体系权重判断的因素包括:
词类包含的关键词的词量:通过分析关键词聚类过程中生成的各词类所包含的关键词数量,以判断该词类所映射生成指标权重,即关键词数量越多的词类其对应的指标权重越大;
词类包含的关键词的词频:为词类中包含的所有关键词在文本数据集中出现的频次累计和;以及
词类包含的关键词的时效性:为一个词类包含的关键词在时间维度上的词频统计显示出该关键词在时间维度上被关注的程度。
进一步,所述步骤s300中生成指标体系权重建议的方法还包括:基于影响指标体系权重判断的因素构建指标体系权重建议的生成公式,即
式中,r(w)为一个词类对应的指标权重建议;i从1到k为该词类中包含的关键词数,依次对该类中所有关键词进行计算;j从1到d为包括该词类中某个词w的文本数据,依次对包含该词w的所有文本数据进行计算;遍历包含词w的文本数据,分别计算第j个包含词w的时间衰减函数;tf(wj)为词w在文本数据j中出现的频次;e-μ(t-tc)为时间衰减函数;μ为衰减常数;t为该文本数据出现的时间;tc为当前时刻;
计算各词类的r(w)权重建议值之后生成指标权重建议。
本发明的有益效果是,本发明基于终端对文本数据集的关键词提取,并且将关键词聚类和swot指标体系映射;以及生成指标体系权重建议,实现了关键词的自动提取和聚类。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明所涉及的终端辅助swot指标体系的构建方法的流程图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
实施例1
图1是本发明所涉及的终端辅助swot指标体系的构建方法的流程图。
如图1所示,本实施例提供了一种终端辅助swot指标体系的构建方法,包括:
步骤s100,基于终端对文本数据集的关键词提取;
步骤s200,关键词聚类和swot指标体系映射;以及
步骤s300,生成指标体系权重建议;
在本实施中,终端可以但不限于采用计算机,以对swot指标体系的构建进行辅助;关键词的自动提取和聚类,有效节省了专家人力资源,并在一定程度上避免了swot体系构建过程中人为干扰因素的影响。
在本实施例中,所述步骤s100,基于终端对文本数据集的关键词提取的方法包括:步骤s101,停用词过滤,对终端采集的文本数据集进行中文分词之后,通过积累挑选形成的停用词表,过滤文本数据中的停用词,所述停用词一般是语气助词、虚词以及数量词等;步骤s102,特定词过滤,通过搜索引擎对词进行搜索,对于搜索结果少于阈值的词,判断其为特定词,然后将特定词过滤,所述特定词一般为地名、人名等指向性很强的特定词;不同于停用词,特定词难以通过定制词表来进行过滤,在相关的研究工作中,很多实用词分类推理来实现特定词的归类,判断词是否是地名、人名等,但是这种推断存在一定的不可靠性;使用搜索引擎,如google、百度等,来判断特定词;例如google每次搜索时都会显示搜索的结果数,使用特定词进行搜索会得到较少的搜索页面数,因此对于搜索结果少于一定阈值的词,可以判断其为特定词,予以过滤;google的检索特定词可以通过google的算法来自动完成;步骤s103,关键词提取,通过改进的tf/idf算法进行关键词提取;tf/idf算法是目前主流的关键词提取算法,tf(termfrequency:词频),指的是某个词在某个文本中出现的次数,idf(inversedocumentfrequency:逆文档频率)。
在本实施例中,所需要实现的是面向整个文本数据集提取出该集合中的关键词,传统的tf/idf算法是针对某一个文档来提取该文档中的关键词,因此对传统tf/idf算法进行改进;所述改进的tf/idf算法为:
式1
式2wi={w|tf/idf(wi)>η};
式3w=∪wi;
式4
式中,tf/idf(wi)为标号为i的文本数据中词w的tf/idf权值;tf(wi)为词w在标号为i的文本数据中出现的频数;n为文本数据集包含的文本数据数;d为包含词w的文本数据数;
所述通过改进的tf/idf算法进行关键词提取的方法包括:通过式1计算出文本数据集中每个文本数据中包含的关键词的tf/idf权值;根据各文本数据中关键词的tf/idf权值按大小进行排序;提取权值大于阈值η的关键词形成标号为i的文本数据的关键词集合wi,所有文本数据的wi集合汇总为文本数据集的关键词w集合;针对w集合中的关键词两两配对,计算比值c;式4中wfsum(wa)指某关键词a在w集合中出现的频数累加和,wfsum(wb)是指某关键词b在w集合中出现的频数累加和,g(wa)是指该关键词a在搜索引擎中获取的检索页面结果数;g(wb)是指该关键词b在搜索引擎中获取的检索页面结果数;比值c为一对关键词a和b的tfsum值与g值(g值与tfsum的表现形式一样,指的是一对关键词在搜索引擎中获取的检索页面结果数)的乘积的比值,并且按比值的结果对w集合中的关键词排序,并按顺序显示以对关键词加以修正。
在本实施例中,所述步骤s200中关键词聚类和swot指标体系映射的方法包括:步骤s201,依据中国分类主题词表,实现对关键词的初次分类,对照中国分类主题词表,将当前文本数据集中提取出的关键词进行分类,建立初始的关键词分类结构;步骤s202,针对初步分类后,剩余的在中国分类主题词表中无法对应分类的关键词,依据词的近义程度作为词与词的距离度量,采用kmeans聚类方法对剩余关键词进行聚类;步骤s203,在终端辅助聚类完成之后,再将聚类后的关键词分类展现并修正,所述修正的方法可以但不限于通过人工进行修正;步骤s204,经过关键词聚类的重复迭代以及对聚类后的关键词分类修正后,根据聚类后的词类的分类信息,将词类映射成对应地指标,即建立swot分析的指标体系。
在本实施例中,所述步骤s300,生成指标体系权重建议的方法包括:选择影响指标体系权重判断的因素;指标体系中各指标对于分析结果的支持度是不一样,即有些指标是主要因素,而有些指标则为次要因素,本实施例通过三个影响指标体系权重判断的因素来生成权重建议;所述影响指标体系权重判断的因素包括:
词类包含的关键词的词量:通过分析关键词聚类过程中生成的各词类所包含的关键词数量,来判断该词类所映射生成指标权重,即关键词数量越多的词类其对应的指标权重越大;
词类包含的关键词的词频:除了关键词数量之外,词类所包含的关键词词频也是该词类映射的指标的权重判断依据,词类包含的关键词词频即该词类中包含的所有关键词在文本数据集中出现的频次累计和;
词类包含的关键词的时效性:关键词在某个时间段中出现的频率,通过开源数据采集到的文本数据集都带有时间属性,文本数据中的词也附加有该文本数据的时间属性,在分析与提取关键词的时候并未考察词的时间属性,而一个词类包含的关键词在时间维度上的词频统计显示出该关键词在时间维度上被关注的程度,即该词类包含的关键词的时效性也是判断其对应指标权重的要素。
在本实施例中,所述步骤s300,生成指标体系权重建议的方法还包括:基于影响指标体系权重判断的因素构建指标体系权重建议的生成公式,即
式中,r(w)为一个词类对应的指标权重建议;i从1到k为该词类中包含的关键词数,依次对该类中所有关键词进行计算;j从1到d为包括该词类中某个词w的文本数据,依次对包含该词w的所有文本数据进行计算;遍历包含词w的文本数据,分别计算第j个包含词w的时间衰减函数;tf(wj)为词w在文本数据j中出现的频次;e-μ(t-tc)为时间衰减函数;μ为衰减常数;t为该文本数据出现的时间;tc为当前时刻;计算各词类的r(w)权重建议值之后生成指标权重建议。
综上所述,本发明通过对文本数据集的关键词提取,以关键词聚类和swot指标体系映射,最后生成指标体系权重建议,实现了关键词的自动提取和聚类,有效节省了专家人力资源,并在一定程度上避免了swot体系构建过程中人为干扰因素的影响;并且本发明还可以有效地节省情报分析人员的工作量,以及在一定程度上可以减少swot指标体系构建过程中的干扰因素,这对于swot分析的应用也具有促进意义。
通过第一次迭代用以获取swot分析目标相关的关键词并对关键词进行聚类,第二次迭代的目标将关键词类映射成swot的评估指标,最后一部分,在swot评估指标生成之后,通过算法生成swot指标权重的建议。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 还没有人留言评论。精彩留言会获得点赞!