一种负面舆情判断方法和装置与流程
本申请涉及数据处理领域,特别是涉及一种负面舆情判断方法和装置。
背景技术:
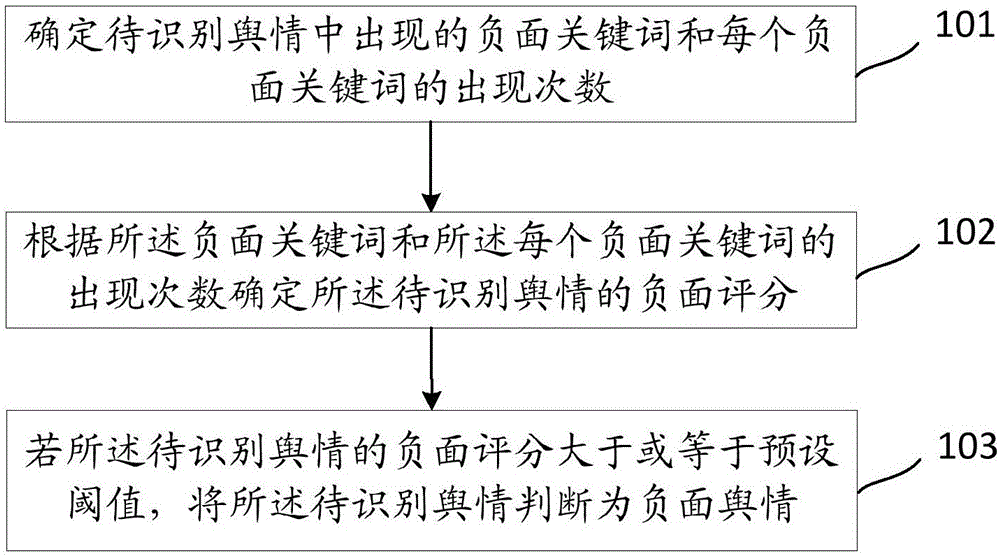
:舆情,是“舆论情况”的简称,是民众对某一企业、个人、社会机构等组织围绕着某一社会事件所表达的态度、意见、言论的总和。随着互联网的发展,网民对某一事件的观点表达通过网络媒体传播形成了网络舆情,由于网络信息的发布成本极低,传播渠道多、传播速度快、传播范围广,并伴随着谣言与非理性的声音,网络舆情已成为舆情的主流模式,一旦未有效处理,容易形成强大的意见声势,成为引发公司或政府的公众事件的导火索。金融行业本质上经营的是“信任”,相比较于其他行业,打造良好的企业形象对于金融行业从业者及公司机构而言更加重要。然而一些金融企业会通过散布“正面舆情”误导用户以此获利,例如很多p2p机构在暴雷前会有组织的通过网络媒体制造“正面舆情”,如散布某某平台经营业绩增长,未来发展势头良好等新闻,并组织大量媒体转载,吸引投资者投资后卷款跑路,最终引发了群体性事件。故此,舆情是金融监管机构信息获取的核心要素,需要对网络上的舆情进行准确的判断识别,尤其是需要判断出负面舆情,从而可以通过负面舆情准确的识别金融企业的实际运营状况,并以此判断舆情传播渠道中是否散布针对金融企业的虚假消息,在确定时第一时间干预辟谣,有效避免风险的进一步恶化。当前主流的判断舆情的手段主要以人工检查为主,即由专人负责,以人工的方式定期查看相关的新闻信息,结合业务的理解人工判断负面舆情。随着网络媒体特别是自媒体的快速发展,现有舆情监测手段难以满足业务需求。具体体现在:人工效率较低,缺乏对舆情的全面评估。以人工查看为主需要人工逐一浏览每一媒体上的舆情,判断是否为负面舆情,这首先需要投入大量的人力资源;其次受限于每一个人的行业经验差异,每个人对舆情的影响力、传播度的判断衡量标准有差异,影响到对舆情的综合分析;第三人工统计舆情数据也增加了操作风险,如遗漏某个重要的舆情。技术实现要素:为了解决上述技术问题,本申请提供了本申请实施例公开了如下技术方案:第一方面,本申请实施例提供了一种负面舆情判断方法,所述方法包括:确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数;根据所述负面关键词和所述每个负面关键词的出现次数确定所述待识别舆情的负面评分;若所述待识别舆情的负面评分大于或等于预设阈值,将所述待识别舆情判断为负面舆情。可选的,针对所述负面关键词中任意一个目标关键词,所述根据所述负面关键词和所述出现次数确定所述待识别舆情的负面评分,包括:根据所述目标关键词的负面权重分和所述目标关键词的出现次数确定所述目标关键词对所述待识别舆情的子负面评分;根据每个负面关键词的子负面评分计算所述待识别舆情的负面评分。可选的,所述目标关键词的负面权重分根据如下方式确定:根据所述目标关键词与第一样本集进行匹配,所述第一样本集包括已识别的多个负面舆情和多个非负舆情;根据所述第一样本集中出现了所述目标关键词的负面舆情的后验条件概率,以及所述第一样本集中负面舆情的先验概率确定所述目标关键词的负面权重分。可选的,所述预设阈值根据如下方式确定:获取第二样本集,所述第二样本集包括已识别的多个负面舆情和多个非负舆情,以及所述多个负面舆情和多个非负舆情的负面评分;根据标注模型,采用不同的识别阈值对第二样本集中的舆情进行负面舆情的识别;若目标识别阈值下的识别结果与所述第二样本集的实际结果间的符合度满足预设条件,将目标识别阈值作为所述预设阈值。可选的,在所述确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数之前,所述方法还包括:获取包括多个待定舆情的舆情集合;根据所述多个待定舆情的标题对所述舆情集合进行舆情过滤;将过滤后的任意一个待定舆情作为所述待识别舆情。可选的,针对所述负面关键词中任意一个目标关键词,所述确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数,包括:根据所述目标关键词在所述待识别舆情中匹配到文本位置,确定包括所述目标关键词的上下文信息;识别所述上下文信息的语义表达倾向;若所述语义表达倾向为正向,确定在所述文本位置未匹配到所述目标关键词。第二方面,本申请实施例提供了一种负面舆情判断装置,所述装置包括确定单元、计算单元和判断单元:所述确定单元,用于确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数;所述计算单元,用于根据所述负面关键词和所述每个负面关键词的出现次数确定所述待识别舆情的负面评分;所述判断单元,用于若所述待识别舆情的负面评分大于或等于预设阈值,将所述待识别舆情判断为负面舆情。可选的,针对所述负面关键词中任意一个目标关键词,所述计算单元还用于:根据所述目标关键词的负面权重分和所述目标关键词的出现次数确定所述目标关键词对所述待识别舆情的子负面评分;根据每个负面关键词的子负面评分计算所述待识别舆情的负面评分。可选的,所述计算单元还用于根据如下方式确定所述目标关键词的负面权重分:根据所述目标关键词与第一样本集进行匹配,所述第一样本集包括已识别的多个负面舆情和多个非负舆情;根据所述第一样本集中出现了所述目标关键词的负面舆情的后验条件概率,以及所述第一样本集中负面舆情的先验概率确定所述目标关键词的负面权重分。可选的,所述计算单元还用于根据如下方式确定所述预设阈值:获取第二样本集,所述第二样本集包括已识别的多个负面舆情和多个非负舆情,以及所述多个负面舆情和多个非负舆情的负面评分;根据标注模型,采用不同的识别阈值对第二样本集中的舆情进行负面舆情的识别;若目标识别阈值下的识别结果与所述第二样本集的实际结果间的符合度满足预设条件,将目标识别阈值作为所述预设阈值。可选的,所述装置还包括过滤单元,所述过滤单元用于:获取包括多个待定舆情的舆情集合;根据所述多个待定舆情的标题对所述舆情集合进行舆情过滤;将过滤后的任意一个待定舆情作为所述待识别舆情。可选的,针对所述负面关键词中任意一个目标关键词,所述确定单元还用于:根据所述目标关键词在所述待识别舆情中匹配到文本位置,确定包括所述目标关键词的上下文信息;识别所述上下文信息的语义表达倾向;若所述语义表达倾向为正向,确定在所述文本位置未匹配到所述目标关键词。由上述技术方案可以看出,首先通过处理设备确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数,根据所述负面关键词和所述每个负面关键词的出现次数可以确定出所述待识别舆情的负面评分,若所述待识别舆情的负面评分大于或等于预设阈值,将所述待识别舆情判断为负面舆情。从而实现了通过负面关键词匹配的方式自动识别舆情是否为负面舆情,避免了人为因素的影响,提高了识别效率和稳定性。附图说明为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。图1为本申请实施例提供的一种负面舆情判断方法的方法流程图;图2为本申请实施例提供的一种负面舆情判断装置的装置结构图。具体实施方式下面结合附图,对本申请的实施例进行描述。目前网络舆情是金融监管机构信息获取的核心要素,以2018年以来诸多p2p暴雷为例,很多p2p机构在暴雷前会有组织的通过网络媒体制造“正面舆情”,如散布某某平台经营业绩增长,未来发展势头良好等新闻,并组织大量媒体转载,吸引投资者投资后卷款跑路,最终引发了群体性事件。如果能够在早期识别该类舆情属于不实消息,或者传播舆情的渠道经常散布虚假消息,第一时间干预辟谣,则可有效避免风险的进一步恶化。故需要有效的舆情识别方案,当前主流的判断舆情的手段主要以人工检查为主,效率较低,受限于每一个人的行业经验差异,容易出现遗漏。为此,本申请实施例提供了一种负面舆情判断方法,该方法可以应用于具有数据处理能力的处理设备中,该处理设备可以是计算机、服务器等。针对需要识别的舆情(例如待识别舆情),通过处理设备确定待识别舆情中出现的负面关键词和每个负面关键词的出现次。根据所述负面关键词和所述每个负面关键词的出现次数可以确定出所述待识别舆情的负面评分,若所述待识别舆情的负面评分大于或等于预设阈值,将所述待识别舆情判断为负面舆情。从而实现了通过负面关键词匹配的方式自动识别舆情是否为负面舆情,避免了人为因素的影响,提高了识别效率和稳定性。图1为本申请实施例提供的一种负面舆情判断方法的方法流程图,所述方法包括:101:确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数。负面关键词可以是根据识别需求预先设置的,针对不同领域的舆情可以有不同的负面关键词。在金融领域中,预先设置的负面关键词用于标识企业或个人的运营状态中的不良特征,例如金融领域中的负面关键词可以包括“违约踩雷老鼠仓暴跌暴涨腰斩跌停巨亏闹剧暴赚爆仓惊爆缩水过山车退市延期兑付套路下折分级保本接盘坐庄内幕交易窝案叫停下挫挤兑跑路清盘平仓爆雷逾期平仓债务危机巨额赎回迷你基金流动性危机定制利益输送”等。舆情在网络上的形式可以是文章、新闻、朋友圈、博客、邮件、聊天信息等。处理设备可以根据预置的负面关键词与待识别舆情进行匹配,以确定待识别舆情中出现了多少个负面关键词,以及每个负面关键词出现的次数。例如,待识别舆情为一篇网页文章a,针对a进行负面关键词的匹配结果可以如表1所示:表1通过表1可知,a的内容中出现了三个负面关键词,分别为“暴雷”、“跌停”、“退市”。其中,“暴雷”在a中出现次数为2,“跌停”、“退市”在a中出现次数均为1。需要注意的是,舆情中匹配到负面关键词所在的上下文信息的语义表达倾向有可能并不是负向的,例如在上下文信息“公司董事长辟谣:我公司自上市以来从未发生过暴雷风险”中,虽然出现了“暴雷”这一负面关键词,但是整个上下文信息的语义表达倾向实际是正向的,并未表达出企业具有不良特征。故为了提高负面关键词的匹配精度,以负面关键词中任意一个作为目标关键词,通过目标关键词举例说明如何解决上述问题。在一种可选的实现方式中,步骤101可以包括:根据所述目标关键词在所述待识别舆情中匹配到文本位置,确定包括所述目标关键词的上下文信息。识别所述上下文信息的语义表达倾向。若所述语义表达倾向为正向,确定在所述文本位置未匹配到所述目标关键词。判断语义表达倾向是否为正向的方式可以有多种,本申请实施例提供了一种可选的方式,即通过负面关键词在上下文信息中的词组结构确定,例如“没有【负面词汇】、停止【负面词汇】、不存在【负面词汇】、无重大违法违规行为、无违约情形、不存在虚假记载、误导性陈述或重大遗漏、逾期90天以上占比”等。通过确定上下文信息的语义表达倾向,可以提高负面关键词的匹配精度,例如上述网页文章a的例子中,通过确定负面关键词所在上下文信息的语义表达倾向,得到的负面关键词的匹配结果可以如表2所示:负面词命中次数命中位置暴雷1位置一:“xxx该公司受限于债务违约以及监管违规存在暴雷风险xxx”跌停1位置一:“xxx已连续10个交易日股票跌停”退市1位置一:“xxx存在退市风险”表2通过表1可知,a的内容中出现了三个负面关键词,分别为“暴雷”、“跌停”、“退市”。其中,“暴雷”、“跌停”、“退市”在a中出现次数均为1。需要注意的是,由于网络上每天新出现的舆情数量非常多,而其中有一些可能明显不属于负面舆情,为了提高识别舆情的效率,可选的,可以通过舆情的标题进行初步筛选,剔除明显不属于负面的舆情。在一种可能的实现方式中,在执行步骤101之前,可以通过舆情标题进行初步筛选,具体方式如下:获取包括多个待定舆情的舆情集合。根据所述多个待定舆情的标题对所述舆情集合进行舆情过滤。将过滤后的任意一个待定舆情作为所述待识别舆情。其中,舆情集合可以是预先从网络上爬取的,或者预先获取的各类待定舆情的集合,待定舆情属于尚未识别是否为负面的舆情。这时可以针对舆情集合进行初步筛查,将明显属于非负面的舆情过滤掉。例如,在金融领域中,过滤的标准可以检测文章标题是否有冒号“:”,如有直接将该条信息标注为非负,停止后续环节。如“长信利盈混合:更新招募说明书摘要(2018年第2号)”。过滤的标准还可以是检测文章标题中是否有“要闻回顾”,由于该类文章更多为聚合类新闻列表,不纳入负面舆情的监测范围,如命中直接标注该文章为非负,如“【周末要闻回顾】贸易战升级中国600亿如何应对美国2000亿?”。过滤的标准除了上述例子外,还可以根据应用场景的不同个性化设置,用户可以基于特定需求的理解设置规则,如滤除掉包含“公告精选”的标题文章,系统实现层面将生成相应的正则表达式,作为一条规则匹配每一篇文章。102:根据所述负面关键词和所述每个负面关键词的出现次数确定所述待识别舆情的负面评分。一篇舆情中出现不同负面关键词的个数,每个负面关键词出现的次数均会对该舆情的负面评分产生影响。一般来说,当一篇舆情中出现不同负面关键词的个数越多,或者每个负面关键词出现的次数越多,相当于这篇舆情提供了所涉及企业的不良特征越多,所表达的内容更倾向于负面,从而会增加这篇舆情的负面评分。本申请中并不限定如何根据不同负面关键词的个数和灭个关键词的出现次数确定负面评分。不过,本申请实施例提供了一种可能的实现方式。在这一实现方式中,以待识别舆情所匹配到的负面关键词中的任意一个作为目标关键词为例进行说明。针对目标关键词,在步骤102中,根据所述目标关键词的负面权重分和所述目标关键词的出现次数确定所述目标关键词对所述待识别舆情的子负面评分。也就是说,目标关键词本身和目标关键词的出现次数均会对负面评分造成影响,这一影响可以通过子负面评分表示。一般来说,不同目标关键词的负面权重分可以不同,一个目标关键词出现的次数越多,得到的子负面评分越高。在确定了待识别舆情中出现的各个目标关键词的子负面评分后,可以通过计算得到所述待识别舆情的负面评分。以前述网页文章a为例,a的内容中出现了三个负面关键词,分别为“暴雷”、“跌停”、“退市”。其中,“暴雷”、“跌停”、“退市”在a中出现次数均为1。“暴雷”对应的负面权重分为0.257;“跌停”对应的负面权重分为0.911;“退市”对应的负面权重分为0.42。计算a的负面评分的问题为计算每一个命中的负面关键词的负面权重分*命中的次数基础上的求和问题,具体可以参见公式(1):p(a)=∑p(n)*c(n)(1)在公式(1)中,p(a)为a的负面评分,n为a中所出现不同负面关键词的个数,p(n)表示目标关键词的负面权重分,c(n)表示目标关键词的出现次数,在上例中p(a)为1.588。上述不同负面关键词的负面权重分可以通过不同方式确定得到,本申请实施例提供了一种可选的的计算方式,以目标关键词为例,目标关键词的负面权重分根据如下方式确定:根据所述目标关键词与第一样本集进行匹配,所述第一样本集包括已识别的多个负面舆情和多个非负舆情;根据所述第一样本集中出现了所述目标关键词的负面舆情的后验条件概率,以及所述第一样本集中负面舆情的先验概率确定所述目标关键词的负面权重分。上述方式的一种可能的实现方式属于应用贝叶斯定律进行条件概率求和的问题,下面通过举例进行说明:①将已识别为负面或非负面的舆情作为第一样本集,识别方式例如可以通过人工标注。例如第一样本集中的舆情共计10000条,其中6000条为负面的舆情,4000条为非负面的舆情。②将目标关键词例如“暴雷”与6000条负面舆情进行匹配,统计匹配上该词的舆情数,如4800条匹配上“暴雷”,1200条未匹配上。③将“暴雷”与4000条非负面舆情进行匹配,统计匹配上该词的舆情数,如800条匹配上,3200条未匹配上。至此构建的表3如下所示:“暴雷”负面舆情非负舆情匹配上的4800800未匹配上的12003200总计60004000表3将匹配上“暴雷”作为事件o,文章为负面舆情作为事件m,则按照贝叶斯定律,计算“暴雷”对应的负面权重分转化为出现“暴雷”后且为负面舆情的后验条件概率减负面舆情先验概率数学问题:其中,p(m)为负面舆情先验概率,p(m|o)为出现“暴雷”后且为负面舆情的后验条件概率。p(o∩m)=4800/10000=48%;p(o)=(4800+800)/10000=56%;p(m)=6000/10000=60%;则p(m|o)-p(m)=48%/56%-60%=0.257。从而确定“暴雷”的负面权重分为0.257。在步骤102中,若所述待识别舆情的负面评分大于或等于预设阈值,执行步骤103。103:将所述待识别舆情判断为负面舆情。例如待识别舆情共有100篇,分别确定出的负面评分如表4所示:文章编号情绪分1st文章a9.12nd文章b3.2…99th文章y-0.3100th文章z-7.2表4按照系统计算好的预设阈值将待识别舆情做区分,如阈值定为-0.2,则负面评分大于等于-0.2的均判定为负面舆情,负面评分小于-0.2的均判定为非负舆情。其中,预设阈值可以根据不同方式确定,例如可以根据不同场景下的识别精度要求进行设置。本申请实施例提供了一种计算预设阈值的方式,属于最优化求解的运筹学的问题。可选的,所述预设阈值根据如下方式确定:获取第二样本集,所述第二样本集包括已识别的多个负面舆情和多个非负舆情,以及所述多个负面舆情和多个非负舆情的负面评分。根据标注模型,采用不同的识别阈值对第二样本集中的舆情进行负面舆情的识别。若目标识别阈值下的识别结果与所述第二样本集的实际结果间的符合度满足预设条件,将目标识别阈值作为所述预设阈值。在一种可能的实现方式中,可以将识别阈值先调到较大的数值,然后每次计算依次减少,以便根据结果从中确定出作为预设阈值的识别阈值。①计算第二样本集中10000篇舆情已识别舆情的负面评分,将其按照由高到底的顺序排列。这10000篇舆情中6000条为负面的舆情,4000条为非负面的舆情。②将识别阈值设置为比负面评分最高分之上,如负面评分最高的分为13,则将识别阈值设置为13.1,即按照识别阈值判定第二样本集中所有的舆情均为非负舆情。③计算按照该识别阈值划分的负面舆情与第二样本集中舆情的实际识别结果一致的比值,即相对准确率(符合度)=(实际与机器标注为负面舆情数+实际与机器均标注为非负面舆情数)/舆情总数。在识别阈值为13.1下的识别结果与第二样本集的实际结果间的符合度=(0+4000)/10000=40%。表5示出了识别阈值为13.1的识别结果和第二样本集的实际结果:表5④按照步长0.1,逐步下调识别阈值,一直下调至第二样本集中负面评分最低的舆情,每次调整后重新计算机器划分负面舆情的相对准确率即符合度,最终取相对准确率最高的识别阈值作为预设阈值,在上例中识别阈值为-0.2时,符合度最高,具体为98.2%,故可以将预设阈值确定为-0.2。表6示出了识别阈值设置为-0.2的识别结果和第二样本集的实际结果:表6根据上述实施例可以看出,首先通过处理设备确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数,根据所述负面关键词和所述每个负面关键词的出现次数可以确定出所述待识别舆情的负面评分,若所述待识别舆情的负面评分大于或等于预设阈值,将所述待识别舆情判断为负面舆情。从而实现了通过负面关键词匹配的方式自动识别舆情是否为负面舆情,避免了人为因素的影响,提高了识别效率和稳定性。图2为本申请实施例提供了一种负面舆情判断装置的装置结构图,所述装置包括确定单元201、计算单元202和判断单元203:所述确定单元201,用于确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数;所述计算单元202,用于根据所述负面关键词和所述每个负面关键词的出现次数确定所述待识别舆情的负面评分;所述判断单元203,用于若所述待识别舆情的负面评分大于或等于预设阈值,将所述待识别舆情判断为负面舆情。可选的,针对所述负面关键词中任意一个目标关键词,所述计算单元还用于:根据所述目标关键词的负面权重分和所述目标关键词的出现次数确定所述目标关键词对所述待识别舆情的子负面评分;根据每个负面关键词的子负面评分计算所述待识别舆情的负面评分。可选的,所述计算单元还用于根据如下方式确定所述目标关键词的负面权重分:根据所述目标关键词与第一样本集进行匹配,所述第一样本集包括已识别的多个负面舆情和多个非负舆情;根据所述第一样本集中出现了所述目标关键词的负面舆情的后验条件概率,以及所述第一样本集中负面舆情的先验概率确定所述目标关键词的负面权重分。可选的,所述计算单元还用于根据如下方式确定所述预设阈值:获取第二样本集,所述第二样本集包括已识别的多个负面舆情和多个非负舆情,以及所述多个负面舆情和多个非负舆情的负面评分;根据标注模型,采用不同的识别阈值对第二样本集中的舆情进行负面舆情的识别;若目标识别阈值下的识别结果与所述第二样本集的实际结果间的符合度满足预设条件,将目标识别阈值作为所述预设阈值。可选的,所述装置还包括过滤单元,所述过滤单元用于:获取包括多个待定舆情的舆情集合;根据所述多个待定舆情的标题对所述舆情集合进行舆情过滤;将过滤后的任意一个待定舆情作为所述待识别舆情。可选的,针对所述负面关键词中任意一个目标关键词,所述确定单元还用于:根据所述目标关键词在所述待识别舆情中匹配到文本位置,确定包括所述目标关键词的上下文信息;识别所述上下文信息的语义表达倾向;若所述语义表达倾向为正向,确定在所述文本位置未匹配到所述目标关键词。根据上述实施例可以看出,首先通过处理设备确定待识别舆情中出现的负面关键词和每个负面关键词的出现次数,根据所述负面关键词和所述每个负面关键词的出现次数可以确定出所述待识别舆情的负面评分,若所述待识别舆情的负面评分大于或等于预设阈值,将所述待识别舆情判断为负面舆情。从而实现了通过负面关键词匹配的方式自动识别舆情是否为负面舆情,避免了人为因素的影响,提高了识别效率和稳定性。本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质可以是下述介质中的至少一种:只读存储器(英文:read-onlymemory,缩写:rom)、ram、磁碟或者光盘等各种可以存储程序代码的介质。需要说明的是,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于设备及系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的设备及系统实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。以上所述,仅为本申请的一种具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1