一种基于信息熵的食品安全事件聚类分析方法与流程
本发明涉及大数据分析技术与食品安全管理领域,具体涉及一种基于信息熵的食品安全事件聚类分析方法。
背景技术:
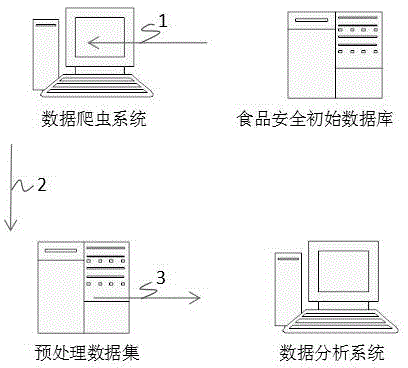
:目前,我国的食品安全危机主要集中在以下几个方面:食品的源头遭受污染。例如,农产品的种植畜养环境不够天然,非法添加化学制剂,农药严重等。食品制造企业缺乏诚信与质量安全意识,生产流通环节卫生状况差。我国食品安全标准还不够完善,需要提高科学性与实用性,以便于检验参考。监管队伍需要进一步提高专业水平,需要加强打击食品犯罪的力度。因此在智能信息化时代背景下,急需建立一个“互联网+”食品安全监管项目,推进食品安全监管大数据资源共享和应用,提高监管效能。技术实现要素:有鉴于此,本发明的目的在于提供一种基于信息熵的食品安全事件分析方法,分析出食品安全事件发生的规律,为各地区在食品安全的监控管理方面提供决策支持。为实现上述目的,本发明采用如下技术方案:一种基于信息熵的食品安全事件分析方法,包括以下步骤:步骤s1:采集食品安全网站上的数据,并清洗整理生成待分析视食品安全事件数据集;步骤s2:构建改进聚类分析算法;步骤s3:根据得到的改进聚类分析算法对待分析视食品安全事件数据集进行分析,得到聚类结果。进一步的,所述步骤s1具体为:步骤s11:搭建页面抓取框架scrapy,设置目标网站url,设置食品安全事件信息起始url;步骤s12:创建爬虫文件,并写入将要读取的url和爬行域名范围;步骤s13:发起http请求,获取目标网站网页信息,页面抓取框架把目标网站url封装成一个请求传给下载器,下载器把资源下载下来,并封装成应答包,爬虫再解析response;步骤s14:爬虫根据url_token提取目标网站网页信息,并保存在mongodb中,并将数据输出在csv中;步骤s15:若页面抓取框架中的调度器传来下一个url,爬虫会接着处理响应请求并返回项目,再将新的数据请求发送给引擎,即返回步骤s12,否则,信息爬取完成,步骤结束。进一步的,所述改进聚类分析算法具体为:步骤s21:设定输入目标的初始聚类中心数k,k≥1;步骤s22:根据下式计算属性总集合a的信息熵e(a)e(a)表示整体的信息熵,即所有的属性将数据集u划分的情况。其中,a将数据集u划分成了一个新的的集合c,c={a1,a2,a3,……,ap},对于c中的任意一个元素ai表示数据集u中与bi的属性值完全相等的数据集子集,所以且|a1|+|a2|+|a3|+……+|ap|=|u|,所以|ai|/|u|即是表示属性值与ai完全相等的元素在数据集u中出现的概率;步骤s23:计算属性总集合中缺少每个属性后的信息熵e(a-{a});其中e(a-{a})表示去掉a属性后,剩余的属性对u的划分情况,计算公式与e(a)相同;步骤s24:根据步骤s21和步骤2s2获取的结果,计算每个属性的权值sig(a),若属性a对数据集u毫无影响则e(a)=e(a-{a}),说明a对数据集u的划分没有起到作用,即sig(a)=0,说明a的属性重要性为0;反之若属性a对数据集u影响越大,则少了a属性的e(a-{a})与e(a)就相差越大;步骤s25:遍历数据集u计算每个属性的平均密度:其中,densa(x)表示对于a中的任意元素a,对象x在属性a上的平均密度计算方法如下:步骤s26:对于数据集u中的每一个对象x,计算其加权密度wdens(x):步骤s27:选取所有对象中加权密度wdens(x)最大的一个,将其设为第一个初始聚类中心,加入聚类中心集合z;步骤s28:遍历数据集u中已经选取为聚类中心以外的每个对象x,保存对象的加权密度wdens(x),计算公式与上述步骤s26所述相同;步骤s29:采用0-1相异度度量方法计算对象x与每个已分配好的初始聚类中心的距离之和d(x):其中,xi,al与xj,al分别表示数据集中xi和xj两个对象在对应属性上的属性值,如果相等则当前属性间的距离赋值为0,如果不想等则赋值为1,累加所有属性的属性间距离,最后得出两个对象之间的距离,即差异度;;步骤s210:对每一个对象x,计算m(x)=wdens(x)+d(x)。步骤s211:比较所有的m(x),选取m(x)最大的那个对象作为新的初始聚类中心,加入聚类中心集合z;步骤s212:判断聚类中心数是否达到k个,即|z|>k是否成立,若成立跳转到步骤s13,若不成立则跳转到步骤s8,继续选择新的初始聚类中心;步骤s213:根据步骤s24得到的sig(a)计算每个属性的权值weight(a):步骤s214:用改进的相异度度量方法计算相异度矩阵:wd(xi,xj)=∑a∈aweight(a)×δa(xi,xj)步骤s215:计算隶属度矩阵wl×n其中,k表示当前数据集划分为k个簇,即存在k个聚类中心,zi表示当前第i个类的聚类中心,zh表示其它类的聚类中心;步骤s216:根据隶属度更新聚类中心集合z,采用属性众数作为聚类中心的新的属性值。即遍历每一个类簇,计算类簇里每一个属性的每一个属性值的总数,用总数最高的属性值替换当前该类簇的聚类中心;步骤s217:回到步骤s15重新计算隶属度,根据每个样本的最大隶属度重新归类;如果隶属度没有变化,那么k类的聚类已经完成,跳转至步骤s18;步骤s218:根据当前隶属度矩阵与相异度矩阵计算聚类准则函数,聚类准则函数为:其中,n是聚类对象的数量;zl=[zl1,zl2,...,zlm]代表聚类l的向量,即聚类中心;wi,l∈[0,1]是隶属度矩阵wl×n的一个元素,它表示对象xi划分到聚类l中的隶属度,wd是改进后的相异度(距离),α>1是加权指数。步骤s219:聚类数量k递增1,并回到步骤s21,直到为止,聚类准则函数最小的那一轮聚类为最后的聚类结果。本发明与现有技术相比具有以下有益效果:1、本发明采用的聚类分析算法采用信息熵理论对初始聚类中心进行优选,并对每个聚类对象的属性重要性进行重新计算聚类的准确率进一步提高。2、本发明基于改进聚类分析算法和大数据,可发现不同时不同地区食品安全事件发生的规律,这些潜藏在数据中的知识可以辅助决策,进一步加强食品行业的监管,对食品安全管理人员以及广大消费者提供信息参考。附图说明图1是本发明一实施例中系统架构图;图2是本发明一实施例中数据爬取流程图;图3是本发明一实施例中改进的聚类分析算法流程图。具体实施方式下面结合附图及实施例对本发明做进一步说明。请参照图1,本发明提供一种基于信息熵的食品安全事件分析方法,包括以下步骤:步骤s1:采集食品安全网站上的数据,并清洗整理生成待分析视食品安全事件数据集;步骤s2:构建改进聚类分析算法;步骤s3:根据得到的改进聚类分析算法对待分析视食品安全事件数据集进行分析,得到聚类结果。如图1所示的食品安全事件数据分析系统架构图中,在过程1中完成数据收集,获取对建立算法和数据模型有关的数据,具体操作即是由数据爬虫系统从“掷出窗外”网站(网址:http://www.zccw.info/)上爬取截止到2018年2月的合计3517条食品安全事件数据。一般原始数据都会有大量的无关项,而筛选的标准则是有助于构建规律挖掘模型,所以需要完成特征选择与特征工程的相关工作,如所述的过程2所示。在过程1中获取到的数据记录中确实存在不统一的属性标签,属性值也有缺失,因此需要将这些属性标签统一化做数据集的预处理,将多余属性排除,将残缺数据补全。最后,如所述的过程3所示,将标准化的数据集发送给数据分析系统接受聚类算法分析,分析的结果将有助于食品安全监督部门与普通消费者了解近几年我们国家食品安全事件发生的规律,对于监督管理工作提供决策性参考。聚类分析模型必须从食品安全网站上获取所要分析的数据集。如图2所示,设置所要爬取的目标网站,该网站的事件数据集存放在其“资料库”板块中,该板块的每个页面存放50条事件记录,可翻页显示下一个50条,每条记录包含新闻标题、新闻日期、事件发生地区、事件主题、相关食品、品牌、不安全因素等多个标签,但是标签类别不统一,所以需要后续的数据集预处理工作。“资料库”板块首页的url为http://www.zccw.info/index,因此将其设置为起始url,根据网站url的命名规律,下一页url构造策略为http://www.zccw.info/index/page/{id},以id递增的方式发起http请求并获得当前网页信息。数据信息提取后输出在.csv格式的文件中留待处理。在本实施例中,每一个食品安全事件都是一个数据样本,这些数据样本的所有属性值都是文本型数据,各属性的取值范围如表1所示。表1在数据存储方面,采用excel工具以csv纯文本形式存取数据。文件内容中的每一行表示一条食品安全事件,每一列表示其中一种属性。在本实施例中,经过上述预处理后得到的食品安全事件数据表如表2所示(因篇幅所限,此处仅提供数据表片段)。表5日期地区食品品牌食品种类不安全因素2017年未知未知品牌中药不合格2017年未知三只松鼠饮品添加剂2017年陕西未知品牌饮品大肠菌2016年多地区未知品牌肉类淋巴肉…………………………对于离散型的文本型数据,在本发明中采用改进的模糊k-modes算法实现聚类。传统的模糊k-modes算法采用了简单的0-1匹配方法作为计算两个对象在同一属性下面的属性值之间的相异度。这个算法的理念是对文本型的数据集进行划分归类,如对于一个由n个对象构成的非空集合u={x1,x2,…,xn},首先随机选取k个对象作为k个初始聚类中心,然后通过0-1匹配的方法计算相异度矩阵,再根据相异度矩阵计算隶属度矩阵,而后通过隶属度矩阵将n个对象划分到最近的初始聚类中心中,形成k个聚类簇,完成一次聚类,然后计算收敛函数,再通过更新聚类中心的方法在每个聚类簇中重新定义一个新的中心,重复之前的内容计算相异度矩阵、隶属度矩阵、分配对象,形成新的k个聚类簇,计算收敛函数,比较两次的收敛函数。多次迭代这样的过程,当收敛函数的值不再改变时,即聚类中心不再发生偏移时,算法结束。但是,该算法具有一些缺点,例如:算法收敛太慢、算法仅能达到局部最优结果而不能达到全局最优结果、算法采用简单的0-1匹配方法来计算对象之间的距离则不能够很好的表现出对象与类之间的相异度、算法结果会受到数据集的输入顺序和初始聚类中心的影响。参考图3,在本实施例中,所述改进聚类分析算法具体为:步骤s21:设定输入目标的初始聚类中心数k,k≥1;步骤s22:根据下式计算属性总集合a的信息熵e(a)e(a)表示整体的信息熵,即所有的属性将数据集u划分的情况。其中,a将数据集u划分成了一个新的的集合c,c={a1,a2,a3,……,ap},对于c中的任意一个元素ai表示数据集u中与bi的属性值完全相等的数据集子集,所以且|a1|+|a2|+|a3|+……+|ap|=|u|,所以|ai|/|u|即是表示属性值与ai完全相等的元素在数据集u中出现的概率;步骤s23:计算属性总集合中缺少每个属性后的信息熵e(a-{a})其中e(a-{a})表示去掉a属性后,剩余的属性对u的划分情况,计算公式与e(a)相同;步骤s24:根据步骤s21和步骤2s2获取的结果,计算每个属性的权值sig(a),若属性a对数据集u毫无影响则e(a)=e(a-{a}),说明a对数据集u的划分没有起到作用,即sig(a)=0,说明a的属性重要性为0;反之若属性a对数据集u影响越大,则少了a属性的e(a-{a})与e(a)就相差越大;步骤s25:遍历数据集u计算每个属性的平均密度:其中,densa(x)表示对于a中的任意元素a,对象x在属性a上的平均密度计算方法如下:步骤s26:对于数据集u中的每一个对象x,计算其加权密度wdens(x):步骤s27:选取所有对象中加权密度wdens(x)最大的一个,将其设为第一个初始聚类中心,加入聚类中心集合z;步骤s28:遍历数据集u中已经选取为聚类中心以外的每个对象x,保存对象的加权密度wdens(x),计算公式与上述步骤s26所述相同;步骤s29:采用0-1相异度度量方法计算对象x与每个已分配好的初始聚类中心的距离之和d(x):其中,xi,al与xj,al分别表示数据集中xi和xj两个对象在对应属性上的属性值,如果相等则当前属性间的距离赋值为0,如果不想等则赋值为1,累加所有属性的属性间距离,最后得出两个对象之间的距离,即差异度;;步骤s210:对每一个对象x,计算m(x)=wdens(x)+d(x)。步骤s211:比较所有的m(x),选取m(x)最大的那个对象作为新的初始聚类中心,加入聚类中心集合z;步骤s212:判断聚类中心数是否达到k个,即|z|>k是否成立,若成立跳转到步骤s13,若不成立则跳转到步骤s8,继续选择新的初始聚类中心;步骤s213:根据步骤s24得到的sig(a)计算每个属性的权值weight(a):步骤s214:用改进的相异度度量方法计算相异度矩阵:wd(xi,xj)=∑a∈aweight(a)×δa(xi,xj)步骤s215:计算隶属度矩阵wl×n其中,k表示当前数据集划分为k个簇,即存在k个聚类中心,zi表示当前第i个类的聚类中心,zh表示其它类的聚类中心;步骤s216:根据隶属度更新聚类中心集合z,采用属性众数作为聚类中心的新的属性值。即遍历每一个类簇,计算类簇里每一个属性的每一个属性值的总数,用总数最高的属性值替换当前该类簇的聚类中心;步骤s217:回到步骤s15重新计算隶属度,根据每个样本的最大隶属度重新归类;如果隶属度没有变化,那么k类的聚类已经完成,跳转至步骤s18;步骤s218:根据当前隶属度矩阵与相异度矩阵计算聚类准则函数,聚类准则函数为:其中,n是聚类对象的数量;zl=[zl1,zl2,...,zlm]代表聚类l的向量,即聚类中心;wi,l∈[0,1]是隶属度矩阵wl×n的一个元素,它表示对象xi划分到聚类l中的隶属度,wd是改进后的相异度(距离),α>1是加权指数。步骤s219:聚类数量k递增1,并回到步骤s21,直到为止,聚类准则函数最小的那一轮聚类为最后的聚类结果。在本实施例中,为了验证算法的有效性,利用著名的算法有效性指标正确率ac(accuracy)、类精度pc(precision)、召回率re(recall)进行实验比对:其中k表示数据集当前的聚类数目,令ai代表被正确分配到第i类的数据数量,令bi代表被错误分配到第i类的数据数量,令ci代表被错误排除出第i类的数据数量。实验中,除了准备好有效性指标之外,还需要有明确分类结果的实验数据集,因此,在本实施例中选择加州大学欧文分校提出的用于机器学习的数据库——uci数据库作为实验数据,目前uci总共包含335个数据集,是一个常用的标准测试数据集。该数据集中分别含有数值型数据集与文本型数据集,其中的文本型数据集适用于本发明的算法有效性实验。每个数据集提供了一份完整的数据记录、分类属性和分类结果集,实验中将数据集导入数据分析系统并执行改进的聚类算法进而计算pc,ac,re三项指标值从而检验算法的有效性。本实施例选择了uci数据库中的文本型数据集soybean和zoo来检验算法。并通过与其他的k-modes算法进行pc,ac,re指标值的对比,来展现本发明中算法的优越性。实验中选择随机选取初始聚类中心的k-modes算法(huang’sk-modeswithrandom)和基于平均密度选取初始聚类中心的k-modes算法(huang’sk-modeswithcao’smethod)参与比较。数据表明,本发明中的算法具有较高的聚类有效性。实验结果如表3与表4所示。表3soybean聚类有效指标表表4zoo的聚类有效指标表在本实施例中,将改进的聚类算法应用于爬虫系统所爬取的食品安全数据集进行规律挖掘,由于数据记录中部分存在信息缺失,经过筛选整理最后留下2751条有效记录。通过上述算法中对最大聚类数的计算,本实施例需要进行52轮聚类,并分别计算聚类准则函数值,取值最小的那一轮聚类为最后的聚类结果。表5显示的是聚类完成后有代表性的聚类中心,由于被曝光事件中没有特别多关于食品品牌的数据,因此在预处理数据时都标记为“未知品牌”,所以在最后的聚类中心中该属性也都是该赋值。表5日期地区食品品牌食品种类不安全因素2006北京未知品牌零食添加剂2011北京未知品牌饮品不合格2011广东未知品牌肉类致癌物2012广东未知品牌粮油不合格2011山东未知品牌水产品添加剂2012山东未知品牌水果农药2009浙江未知品牌饮品添加剂2012江苏未知品牌零食添加剂2011上海未知品牌零食添加剂2012上海未知品牌饮品添加剂2012福建未知品牌肉类不合格2012福建未知品牌饮品不合格2011四川未知品牌粮油不合格2013湖南未知品牌粮油不合格2009湖北未知品牌粮油添加剂以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1