一种基于残差学习卷积神经网络的多光谱图像反演方法与流程
本发明涉及多光谱成像领域的图像反演问题领域,更具体而言,涉及一种基于残差学习卷积神经网络的多光谱图像反演方法。
背景技术:
已有的研究发现,多光谱成像系统的成像质量通常较差,难以获取各个通道的清晰图像。主要原因是由离焦(out-of-focus)、衍射方向波长展宽等因素引起。针对该问题,国内外许多研究者展开了深入的研究。针对离焦模糊问题,早期的研究通过调焦方式消除色差导致的成像模糊,该方法主要通过一定算法计算图像清晰度并采用步进电机对前置光学镜头调焦,但在宽光谱范围的成像测量中,完成一次光谱成像测量耗时较长,对运动物体进行测量效果较差;近年来,较为流行的处理思路是通过图像处理的方式将图像去模糊问题转化为一个带先验知识约束的优化问题。沈会良等人针对光谱成像系统失焦模糊问题,利用通道间的图像相关性提取模糊图像的参考图像先验知识,并作为约束添加到优化问题的正则项中。但是该方法需要选取所有通道中最清晰通道作为参考通道;另外,该方法采用高斯型模糊核函数近似描述失焦模糊的退化过程,虽然可以简化问题,但由于模型不能准确逼近实际的失焦点扩散函数,导致离焦模糊图像复原无法取得预期效果。针对衍射方向波长展宽引起的模糊问题,赵慧洁等人提出了期望值最大化迭代去模糊方法,该方法对于同一个换能器取得较好结果,但不同换能器、不同超声驱动频率需采用不同点扩散函数来解决宽光谱范围内衍射方向成像模糊问题。
技术实现要素:
为了克服现有技术中所存在的不足,本发明提供一种基于残差学习卷积神经网络的多光谱图像反演方法,解决现有多光谱成像系统中普遍存在的清晰图像获取困难问题。
为了解决上述技术问题,本发明所采用的技术方案为:
一种基于残差学习卷积神经网络的多光谱图像反演方法,包括以下步骤:
s1、利用多光谱成像系统分别采集k个目标物体的主通道图像与从通道清晰图像,其中,多光谱成像系统包括n个通道,任意选择第i∈{1,2,...,n}个通道作为主通道,剩余通道j∈{1,2,...,i-1,i+1,...,n}作为从通道;建立主通道与从通道图像库
s2、将图像库s中的主通道和从通道清晰图像
s3、构造与每个从通道对应的卷积神经网络模型mj,j∈{1,2,...,i-1,i+1,...n}训练所需的样本对;
s4、设计基于残差学习的卷积神经网络模型结构;
s5、卷积神经网络模型训练学习,针对从通道集合中的每个通道j∈{1,2,...i-1,i+1,...,n},利用随机梯度下降算法,建立每个从通道的卷积神经网络模型mj,j∈{1,2,...,i-1,i+1,...,n};
s6、对新目标物体第j个从通道图像的反演:若要反演新目标物体l的第j个个从通道的清晰图像,则首先获取主通道第i个通道的清晰图像
s7、针对从通道集合中的每个通道j∈{1,2,...,i-1,i+1,...,n},重复s6,直至反演出所有从通道的清晰图像。
进一步地,所述s1中采集图像通过硬件手段或者软件手段使得采集的图像清晰。
进一步地,所述通过硬件手段捕获清晰图像,包括但不限于采用步进电机等对前置光学镜头调焦;所述通过软件手段捕获清晰图像,包括但不限于利用图像去模糊等方法进行清晰图像的恢复。
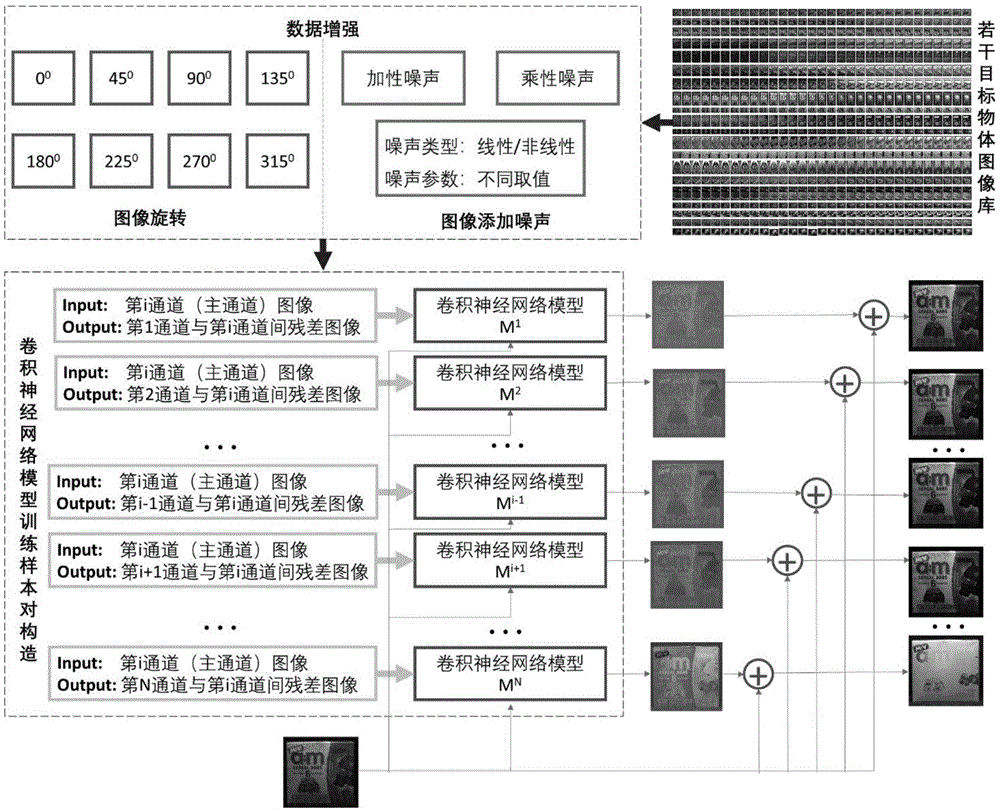
进一步地,所述s2中图像库s执行旋转和添加噪声两种操作算子的处理的具体操作方式为:将图库s中的每一对主/从通道图像都进行相同角度的旋转或添加相同噪声。
进一步地,所述旋转的角度包括但不限于0°、45°、90°、135°、180°、225°、270°、315°。
进一步地,所述噪声的添加方式为加性或乘性噪声;噪声类型为线性或非线性;噪声的参数为不同的参数组合。
进一步地,所述s3中每个样本对包括输入和输出两部分,其中每个样本对的输入为第i个主通道清晰图像imaster,每个样本对的输出为第j个从通道与主通道之间的残差图像
进一步地,所述s4中卷积神经网络模型的结构包含一个输入层、若干个卷积层、池化层、激活函数层、全连接层和输出层。
进一步地,所述s4中卷积神经网络模型的拓扑结构,包括但不限于lenet、alexnet、vgg16/vgg19、googlenet、resnet等已有的结构类型,也包含自定义的拓扑结构类型。
与现有技术相比,本发明所具有的有益效果为:
本发明提供了一种基于残差学习卷积神经网络的多光谱图像反演方法。将多光谱成像系统中各个通道间图像的相关性问题转化为基于残差学习的卷积神经网络建模问题,通过模型的训练,利用任一通道的清晰图像,可以反演出所有通道的图像。该方法无需对各个通道进行调焦或利用图像去模糊方法进行处理,只需获得一个通道的清晰图像并将其作为主通道图像,利用该方法即可快速地反演出其它各个通道(从通道)的清晰图像,从而可以大大提升多光谱成像系统的速度。利用该方法,可以从任意一个通道的清晰图像出发,即可反演出其它各个通道的清晰图像。
附图说明
图1为基于残差学习卷积神经网络多光谱图像反演方法示意图;
图2为基于残差学习的卷积神经网络拓扑结构示意图;
图3为20个目标物体多光谱图像库;
图4为新目标物体多光谱真实图像;
图5为残差图像;
图6为卷积神经网络结构参数;
图7为新目标物体多光谱图像反演结果;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1-2所示,一种基于残差学习卷积神经网络的多光谱图像反演方法,包括以下步骤:
s1、建立主通道与从通道图像库。利用多光谱成像系统分别采集k个目标物体的主通道图像与从通道清晰图像,其中,多光谱成像系统包括n个通道,任意选择第i∈{1,2,...,n}个通道作为主通道,剩余通道j∈{1,2,...,i-1,i+1,...,n}作为从通道;建立主通道与从通道图像库
s2、数据增强。将图像库s中的主通道和从通道清晰图像
s3、构造与每个从通道对应的卷积神经网络模型mj,j∈{1,2,...,i-1,i+1,...n}训练所需的样本对,每个样本对包括输入和输出两部分,其中每个样本对的输入为第i个主通道清晰图像imaster,每个样本对的输出为第j个从通道与主通道之间的残差图像
s4、设计基于残差学习的卷积神经网络模型结构。卷积神经网络模型的拓扑结构,包括但不限于lenet、alexnet、vgg16/vgg19、googlenet、resnet等已有的结构类型,也包含自定义的拓扑结构类型;卷积神经网络模型的结构包含一个输入层、若干个卷积层、池化层、激活函数层、全连接层和输出层;
s5、卷积神经网络模型训练学习。针对从通道集合中的每个通道j∈{1,2,...i-1,i+1,...,n},利用随机梯度下降算法,建立每个从通道的卷积神经网络模型mj,j∈{1,2,...,i-1,i+1,...,n};
s6、对新目标物体第j个从通道图像的反演。若要反演新目标物体l的第j个个从通道的清晰图像,则首先获取主通道第i个通道的清晰图像
s7、针对从通道集合中的每个通道j∈{1,2,...,i-1,i+1,...,n},重复s6,直至反演出所有从通道的清晰图像。
在本实施例中,图像库s中共包含20个目标物体,每个目标物体采集了31张不同通道(波长)的灰度图像,波长范围为400nm-700nm,每间隔10nm采集一个通道的图像。
图3为已建立好的包含20个目标物体的多光谱图像库,用于训练基于残差的卷积神经网络模型;图4为新目标物体的多光谱真实图像,该图像为测试集样本,不参与卷积神经网络模型的学习过程,仅用于测试多光谱图像反演结果的好坏。
在本实施例中,不失一般性,将第一个通道(即波长为400nm)作为主通道,剩余30个通道作为从通道。图5列出了多光谱图像库中某一个目标物体各个从通道图像与主通道图像之间的残差图像。
在本实施例中,卷积神经网络的结构及参数如图6所列。从中可以直观地看出,该卷积神经网络模型共包含41层,其中第1一层为输入层,第2层至第40层为交替的卷积层和激活函数层,第41层为输出层。训练算法采用随机梯度下降法,损失函数为均方根误差。
新目标物体所有从通道(即从第2~31个通道,对应波长为410~700nm)的图像反演结果如图7所列。其中,为了评价反演图像与真实图像之间的相似度,这里利用结构相似度ssim(structuralsimilarityindex)作为评价指标。ssim的定义如下:
其中,μx为图像x的平均值;μy为图像y的平均值;
从图7中可以看出,反演图像与真实图像之间的ssim均高于0.70,最高可达0.90左右,表明利用本发明提出的方法,可以准确地反演出各个从通道的图像。
上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!