一种用于中文历史文献密集文本的文字检测识别方法与流程
本发明涉及模式识别和人工智能技术领域,尤其涉及一种用于中文历史文献密集文本的文字检测识别方法。
背景技术:
大量的历史文献是过去的文明留下来的珍贵遗产,解读和保护这些历史文献最有效的方法就是将它们电子化,包括将其中的文字和符号识别并保存下来。近年来,深度学习算法在计算机视觉领域取得了一系列突破性的进展,通用的物体检测算法和场景文本检测算法都有很大的提升,然而,对于中文历史文献中密集的文本,通用的物体检测算法和场景文本检测框架效果并不太理想,而检测的效果又影响了进一步对历史文献进行文字识别,因此,对历史文献中的密集文本进行精确的检测,对将历史文献进行电子化具有重大的意义。
技术实现要素:
本发明的目的在于克服现有技术中的缺点与不足,提供一种用于中文历史文献密集文本的文字检测识别方法,减少网络的参数量,同时使检测的效果更加有效。
为实现以上目的,本发明采取如下技术方案:
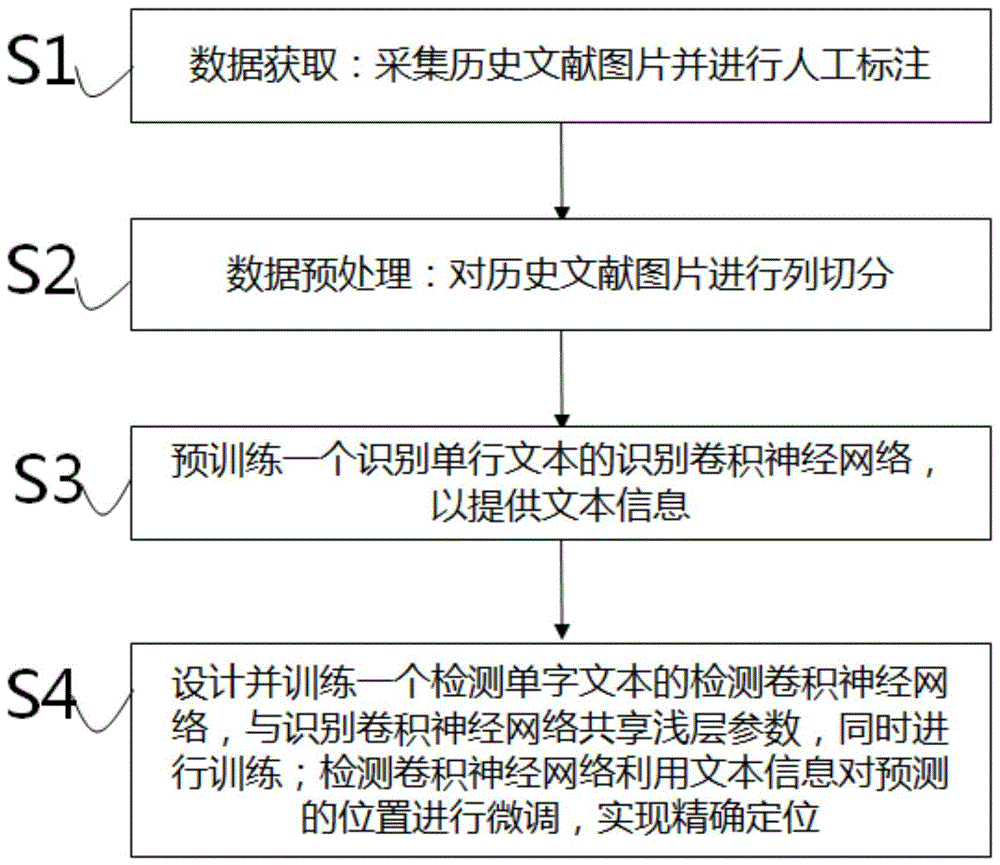
一种用于中文历史文献密集文本的文字检测识别方法,包括下述步骤:
s1、数据获取:采集历史文献图片,并进行人工标注,以形成标签数据集;
s2、数据预处理:对步骤s1所采集的历史文献图片进行竖直投影做列切分,将历史文献图片中竖直的文本按列切开,形成图片数据集;
s3、构建一个用于识别单行文本的识别卷积神经网络,利用步骤s1获得的标签数据集和步骤s2预处理获得的图片数据集对所述识别卷积神经网络进行训练;
s4、构建一个用于检测密集文本文字的检测卷积神经网络,与步骤s3中所述识别卷积神经网络共享浅层参数,并同时进行训练;所述检测卷积神经网络利用所述识别卷积神经网络输出的文本信息,对文字检测的位置进行微调,实现精确检测历史文献图片中密集文本的单个文字位置。
作为有选优的技术方案,步骤s1具体包括下述步骤:
s11、通过文档扫描或相机拍照的方式获取原始的历史文献图片;
s12、通过人工标注的方式,将步骤s11中收集得到的原始历史文献图片中的文本位置与文本信息标注出来,具体的方式是:在原始的历史文献图片中用文本框将单个文字框出来,并将对应的文本文字输入记录,形成标签数据集。
作为有选优的技术方案,步骤s2具体包括下述步骤:
s21、根据需要处理的文本特点对步骤s1采集的历史文献图片使用投影法进行列切分,将历史文献图片中竖直的文本按列切开,形成图片数据集;具体如下:
由于输入的历史文献图片中竖直文本为列格式,故利用垂直投影,即计算每一个像素列上的像素总和,通过寻找所述历史文献图片中列的分界点,来进行列切分,形成图片数据集;将图片按像素投影到x轴,定义分割临界值c,c由公式(1)计算可得,
其中,cavg是平均像素值,dmin是当前历史文献图片的最小像素值,a和b是经验参数;w为垂直投影与分割临界值c的水平线相交的宽度,
式中,γ、δ为自适应参数;
作为有选优的技术方案,步骤s3具体包括下述步骤:
s31、构建用于识别单行文本的识别卷积神经网络,该网络包括十七层结构,第一层为输入层,首先将输入该层的历史文献图片预处理为1000*100大小的列图片;第二层、第四层、第六层为对历史文献图片进行浅层特征提取的卷积层,通道数分别为16、32、64,卷积核大小均为3*3,步长均为1*1;第三层、第五层、第七层为池化层,核大小均为2*2,步长均为2*2;第八层、第十层、第十二层为深层特征提取的卷积层,通道数分别为128、256、512,卷积核大小分别为3*3、3*3、3*1,步长分别为1*1、1*1、3*1;第九层、第十一层为池化层,核大小均为2*2,步长均为2*2;第十三层为批归一化处理层;第十四层为转置层,对矩阵进行转置操作;第十五层、第十六层为全连接层,表示对前一层得到的特征按照不同的权重进行学习;第十七层为解码处理层;
所述解码处理层的输入维度为n*1,其中n表示要进行识别的字的类别数加一个额外的“空白”类别;所述解码处理层的输出中每个“时间点”对应一个字符,通过计算可找到这个字符在输入图片中对应的位置,即对应的感受野;假设ri表示当前“时间点”在第i个卷积层所对应的区域大小,(xi,yi)表示在第i个卷积层对应区域的中心位置,具体通过以下公式计算:
ri=(ri+1-1)×si+ki(3)
其中,ri+1为当前“时间点”在第i+1个卷积层所对应的区域大小,(xi+1,yi+1)表示在第i+1个卷积层所述对应区域的中心位置,ki为第i个卷积层的卷积核大小,si为第i个卷积层的步长,pi为第i个卷积层的填充尺寸;
s32、将所述标签数据集的标签和所述图片数据集的图片进行分组,以对步骤s31构建的识别卷积神经网络进行多批次训练,具体如下:
设定每一批进行训练的图片数量为bs1张,将步骤s21预处理切分产生的t1张图片随机分为t1/bs1组,根据预处理切分的列图片,将对应的人工标注的文本行信息作为切分图片对应的真实标签,对步骤s31所构建的识别卷积神经网络进行训练时,采用多批次训练,每批次使用一组数据进行批量训练;
s33、利用所述标签数据集和所述图片数据集对步骤s32批次训练后的识别卷积神经网络进行训练,具体如下:
采用随机梯度下降方法对步骤s32中多批次训练后的识别卷积神经网络进行训练,初始学习率为lr0,学习率惩罚系数为λ,最大训练迭代次数为itermax,学习率按照公式(6)更新:
其中,iter为当前迭代次数;lriter为当前学习率;γ表示学习率调整的速率;stepsize表示学习率调整的步长。
作为有选优的技术方案,步骤s4具体包括下述步骤:
s41、构建一个对检测密集文本文字的检测卷积神经网络,将输入该网络的图片预处理成1000*100大小的列图片;所述检测卷积神经网络与识别卷积神经网络共享浅层参数,即共享前七层参数;所述检测卷积神经网络的第八层、第十层为深层特征提取的卷积层,通道数分别为128、256,卷积核大小分别为3*3、3*3,步长均为1*1;所述检测卷积神经网络的第九层、第十一层为池化层,核大小均为2*2,步长均为2*2;所述检测卷积神经网络的第十二层为卷积层,通道数为4,卷积核大小为3*1,步长为3*1;所述检测卷积神经网络的第十三层为批归一化处理层,第十四层为损失函数层;
s42、利用所述图像数据集对所述检测卷积神经网络进行训练,具体如下:
所述检测卷积神经网络与识别卷积神经网络采用随机梯度下降方法同时进行训练,用于训练所述检测卷积神经网络的图片为预切分的t2张列图片和对应的人工标注的文字位置信息,每bs2张图片为一组,分为t2/bs2组进行训练,其中t2=t1,bs2=bs1;
s43、所述检测卷积神经网络对所述识别卷积神经网络计算出来的感受野进行微调,具体如下:
通过步骤s31中式(3)、式(4)、式(5)的计算,所述识别卷积神经网络最后一层的每一个输出对应在输入图片中的位置即可作为检测卷积神经网络的有效候选框,所述检测卷积神经网络输出有效候选框四个顶点的偏移值,对有效候选框的位置进行微调,来达到更加紧密的检测定位效果;
s44、合并整理最终的候选框与识别结构,具体如下:
在所述检测卷积神经网络的输出中,存在多个候选框,即文本框,采用简化的非最大值抑制方法对最终的文本框进行筛选,具体过程是:相邻的两个框如果在识别卷积神经网络中是相同的文字识别结果,当它们的重叠面积比,即两个框重叠的面积/两个框的面积总和大于阈值t,那么在识别卷积神经网络输出的结果中对应置信度最大的将成为检测的结果,从而实现精确检测历史文献中密集文本的单个文字位置,同时得到对应的识别文本。
作为有选优的技术方案,步骤s41中,所述检测卷积神经网络的输出维度为4*1,其中4表示对应感受野的4个定点的偏移值;为了保持相同位置上的特征向量对应的感受野大小一致,将识别卷积神经网络与检测卷积神经网络的特征一直保持在相同的维度;所述检测卷积神经网络的损失函数由以下公式计算:
其中t为识别出的字符个数,pj为检测卷积神经网络在第j个位置检测的输出结果,gj为第j个位置的真实位置标签,smoothl1(·)为平滑l1范数函数,计算方法如下式(9):
本发明相对于现有技术具有如下的优点和效果:
(1)本发明采用识别卷积神经网络和检测据卷积神经网络共享浅层参数共同训练的方式,有效地提高两个卷积神经网络的性能,同时又减少了网络计算和存储的参数量。
(2)本发明采用识别卷积神经网络来为检测卷积神经网络提供有效的候选框,大大减少了候选框的数目;通过计算识别字符对应的感受野(即这个字符在输入图片中对应的位置),再对感受野的四个顶点进行偏移预测,对感受野进一步进行微调,相对于其他检测框架使用更少的参数量即可达到更加紧密而有效的检测结果。
附图说明
图1是本发明用于中文历史文献密集文本的文字检测识别方法流程图;
图2是本发明步骤s4中共享参数的两个卷积神经网络;
图3是本发明步骤s4中检测神经网络对计算的感受野进行微调的过程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
本发明主要解决通用物体检测和场景文本检测框架对于密集文本的检测不够精确的问题,参考人类阅读的特点,利用一个文本识别分类器来提供文本信息,来帮助训练文本检测器,从而提高文本检测器的精确性,在相对情况下,利用很少的参数量可以实现更加紧密而有效的检测定位。
如图1所示,一种用于中文历史文献密集文本的文字检测识别方法,包括下述步骤:
s1、数据获取:采集历史文献图片,并进行人工标注,以形成标签数据集;
s2、数据预处理:对步骤s1所采集的历史文献图片进行竖直投影做列切分,将历史文献图片中竖直的文本按列切开,形成图片数据集;
s3、构建一个用于识别单行文本的识别卷积神经网络,利用步骤s1获得的标签数据集和步骤s2预处理获得的图片数据集对所述识别卷积神经网络进行训练;
s4、构建一个用于检测密集文本文字的检测卷积神经网络,与步骤s3中所述识别卷积神经网络共享浅层参数,并同时进行训练;所述检测卷积神经网络利用所述识别卷积神经网络输出的文本信息,对文字检测的位置进行微调,实现精确检测历史文献图片中密集文本的单个文字位置。
以下分别对本发明的技术方案进行详细说明。
步骤s1、数据获取:采集历史文献图片,并进行人工标注,以形成标签数据集;包括下述步骤:
s11、通过文档扫描或相机拍照的方式获取原始的历史文献图片;
s12、通过人工标注的方式,将步骤s11中采集的原始历史文献图片中的文本位置与文本信息标注出来,具体的方式是:在原始的历史文献图片中用文本框将单个文字框出来,并将对应的文本文字输入记录,形成标签数据集。
步骤s2、数据预处理:对步骤s1所采集的历史文献图片进行竖直投影做列切分,将历史文献图片中竖直的文本按列切开,形成图片数据集;包括下述步骤:
s21、根据需要处理的文本特点对历史文献图片使用投影法进行列切分,将历史文献图片中竖直的文本按列切开,得到t1张图片;具体如下:
由于输入的历史文献图片中竖直文本为列格式,故利用垂直投影,即计算每一个像素列上的像素总和,通过寻找所述历史文献图片中列的分界点,来进行列切分,形成图片数据集;将图片按像素投影到x轴,定义分割临界值c,具体由公式(1)计算可得,
其中,cavg是平均像素值,dmin是当前历史文献图片的最小像素值,a和b是经验参数;w为垂直投影与分割临界值c的水平线相交的宽度,
式中,γ、δ表示自适应参数,本实施例中均取值1.5;
步骤s3、构建一个用于识别单行文本的识别卷积神经网络,利用步骤s1获得的标签数据集和步骤s2预处理获得的图片数据集对所述识别卷积神经网络进行训练;包括下述步骤:
s31、构建用于识别单行文本的识别卷积神经网络,该网络包括十七层结构,第一层为输入层,首先将输入该层的历史文献图片预处理为1000*100大小的列图片;第二层、第四层、第六层为对历史文献图片进行浅层特征提取的卷积层,通道数分别为16、32、64,卷积核大小均为3*3,步长均为1*1;第三层、第五层、第七层为池化层,核大小均为2*2,步长均为2*2;第八层、第十层、第十二层为深层特征提取的卷积层,通道数分别为128、256、512,卷积核大小分别为3*3、3*3、3*1,步长分别为1*1、1*1、3*1;第九层、第十一层为池化层,核大小均为2*2,步长均为2*2;第十三层为批归一化处理层;第十四层为转置层,对矩阵进行转置操作;第十五层、第十六层为全连接层,表示对前一层得到的特征按照不同的权重进行学习;第十七层为ctc解码处理层;
所述ctc解码处理层的输入维度为n*1,其中n表示要进行识别的字的类别数加一个额外的“空白”类别;所述解码处理层的输出中每个“时间点”对应一个字符,通过计算可找到这个字符在输入图片中对应的位置(感受野);假设ri表示当前“时间点”在第i个卷积层所对应的区域大小(宽度/高度),(xi,yi)表示在第i个卷积层对应区域的中心位置,具体通过以下公式计算:
ri=(ri+1-1)×si+ki(3)
其中,ri+1为当前“时间点”在第i+1个卷积层所对应的区域大小,(xi+1,yi+1)表示在第i+1个卷积层所述对应区域的中心位置,ki为第i个卷积层的卷积核大小,si为第i个卷积层的步长,pi为第i个卷积层的填充尺寸。
s32、将标签数据集的标签和图片数据集的图片进行分组,以对步骤s31构建的识别卷积神经网络进行多批次训练,
设定每一批进行训练的图片数量为bs1张,将步骤s21预处理产生的t1张图片随机分为t1/bs1组,根据预处理切分的列图片,将对应的人工标注的文本行信息作为切分图片对应的真实标签,对步骤s31所构建的识别卷积神经网络进行训练时,采用多批次训练,每批次使用一组数据进行批量训练;
s33、利用标签数据集和图片数据集对步骤s32批次训练后的识别卷积神经网络进行训练,具体如下:
采用随机梯度下降方法对步骤s32中批次训练后的识别卷积神经网络进行训练,初始学习率(神经网络算法在训练样本空间寻找最优解的更新速率)为lr0,学习率惩罚系数(用于防止神经网络对训练样本出现过拟合)为λ,最大训练迭代次数为itermax,学习率按照公式(6)更新:
其中,iter为当前迭代次数;lriter为当前学习率;γ表示学习率调整的速率;stepsize表示学习率调整的步长;在本实施例中,lr0取值为1、0.5或0.1;λ取值为0.01、0.005、0.001;itermax范围取值为10000-20000;γ范围取值为0.0001-0.0003;stepsize范围取值为2000-3000;
步骤s4、如图2所示,构建一个用于检测密集文本文字的检测卷积神经网络,与步骤s3中所述识别卷积神经网络共享浅层参数,并同时进行训练;所述检测卷积神经网络利用所述识别卷积神经网络提供的文本信息,对文字检测的位置进行微调,实现精确检测历史文献图片中密集文本的单个文字位置;具体包括下述步骤:
s41、构建一个对检测密集文本文字的检测卷积神经网络,将输入该网络的图片预处理成1000*100大小的列图片;所述检测卷积神经网络与识别卷积神经网络共享浅层参数,即共享前七层参数;所述检测卷积神经网络的第八层、第十层为深层特征提取的卷积层,通道数分别为128、256,卷积核大小分别为3*3、3*3,步长均为1*1;所述检测卷积神经网络的第九层、第十一层为池化层,核大小均为2*2,步长均为2*2;所述检测卷积神经网络的第十二层为卷积层,通道数为4,卷积核大小为3*1,步长为3*1;所述检测卷积神经网络的第十三层为批归一化处理层,第十四层为损失函数层;
所述检测卷积神经网络的输出维度为4*1,其中4表示对应感受野的4个定点的偏移值;为了保持相同位置上的特征向量对应的感受野大小一致,将识别卷积神经网络与检测卷积神经网络的特征一直保持在相同的维度;所述检测卷积神经网络的损失函数由以下公式计算:
其中t为识别出的字符个数,pj为检测卷积神经网络在第j个位置检测的输出结果,gj为第j个位置的真实位置标签,smoothl1(·)为平滑l1范数函数,计算方法如下式(9):
s42、利用所述图像数据集对所述检测卷积神经网络进行训练,具体如下:
所述检测卷积神经网络与所述识别卷积神经网络采用随机梯度下降方法同时进行训练,用于训练所述检测卷积神经网络的图片为预切分的t2张列图片和对应的人工标注的文字位置信息,每bs2张图片为一组,分为t2/bs2组进行训练,其中t2=t1,bs2=bs1;
s43、如图3所示,所述检测卷积神经网络对所述识别卷积神经网络计算出来的感受野进行微调,具体如下:
通过步骤s31中式(3)、式(4)、式(5)的计算,所述识别卷积神经网络最后一层的每一个输出对应在输入图片中的位置即可作为检测卷积神经网络的有效候选框,检测卷积神经网络利用识别卷积神经网络提供的文本指导信息,可以大大减少候选框的数量,相对其他检测框架,用更少的参数就可以实现字符级别的文字检测;所述检测卷积神经网络输出有效候选框四个顶点的偏移值,对有效候选框的位置进行微调,来达到更加紧密的检测定位效果;
s44、合并整理最终的候选框与识别结构,具体如下:
在所述检测卷积神经网络的输出中,存在多个候选框,即文本框,采用简化的非最大值抑制方法对最终的文本框进行筛选,具体过程是:相邻的两个框如果在识别卷积神经网络中是相同的文字识别结果,当它们的重叠面积比,即两个框重叠的面积/两个框的面积总和大于阈值t,那么在识别卷积神经网络输出的结果中对应置信度最大的将成为检测的结果,从而实现精确检测历史文献中密集文本的单个文字位置,同时得到对应的识别文本;本实施例中,t取值0.5。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明的保护范围应以权利要求所述为准。
- 还没有人留言评论。精彩留言会获得点赞!