基于E辅助函数的半非负矩阵分解的人脸识别方法、系统及存储介质与流程
本发明涉及数据处理
技术领域:
,尤其涉及基于e辅助函数的半非负矩阵分解的人脸识别方法、系统及存储介质。
背景技术:
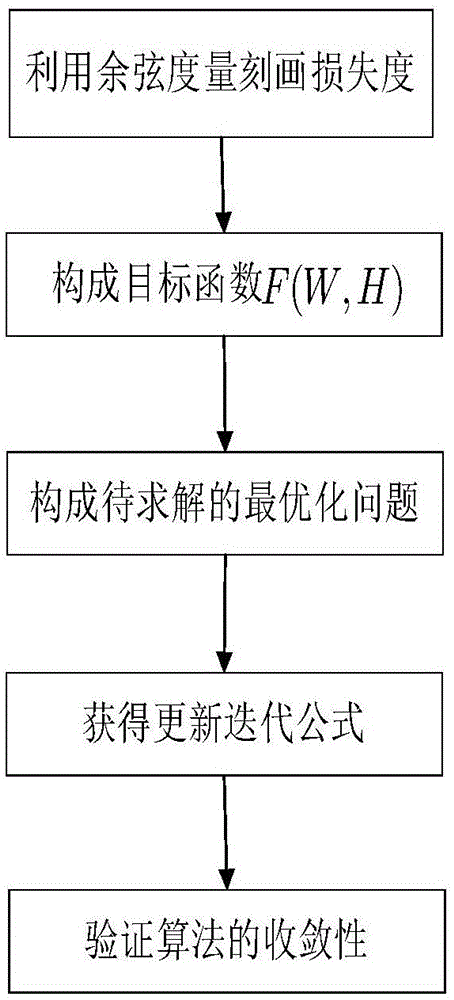
:随着信息化时代的到来,利用人体固有的生理特征和行为特征进行个人身份鉴定的生物识别技术成为了一个最活跃的研究领域之一。在生物识别技术的众多分支中,最容易被人们接受的一个技术是人脸识别技术,这是由于相对于其他生物识别技术而言,人脸识别具有无侵害性、非强制性、非接触性和并发性。人脸识别技术包含两个阶段,第一阶段是特征提取,也就是提取人脸图像中的人脸特征信息,这一阶段直接决定了人脸识别技术的好坏;第二阶段是身份鉴定,根据提取出的特征信息进行个人身份鉴定。主成分分析(pca)与奇异值分解(svd)都是较为经典的特征提取方法,但是这两种方法提出的特征向量通常含有负元素,因此在原始样本为非负数据下,这些方法不具有合理性与可解释性。非负矩阵分解(nmf)是一种处理非负数据的特征提取方法,它的应用非常广泛,比如高光谱数据处理、人脸图像识别等。nmf算法在原始样本非负数据矩阵分解过程中,对提取的特征具有非负性限制,即分解后的所有分量都是非负的,因而可以提取非负的稀疏特征。nmf算法的实质也就是将非负矩阵x近似分解为基图像矩阵w和系数矩阵h的乘积,即x≈wh,且w和h都是非负矩阵。这样矩阵x的每一列就可以表示成矩阵w列向量的非负线性组合,这也符合nmf算法的构造依据——对整体的感知是由对组成整体的部分的感知构成的(纯加性)。然而,nmf需要原始样本为非负数据,这在一定程度上限制了该算法的应用范围。为了扩大nmf的适用范围,近年来,学者们提出了许多对nmf变形的算法,例如,半非负矩阵分解(semi-nmf)和凸非负矩阵分解(convex-nmf)。这两种算法既能用于非负数据,又能用于其他数据。但是,由于它们允许原始样本中含有负数,故证明其迭代公式的收敛性变成了一个十分复杂问题。同时,现有的semi-nmf迭代方法存在收敛速度较慢、算法识别率较低等问题。1.辅助函数(auxiliaryfunction)辅助函数是证明算法收敛性的一种常用工具,其定义与性质如下:定义1:对于任意的矩阵h和h(t),若满足条件g(h,h(t))≥f(h),且g(h(t),h(t))=f(h(t))则称g(h,h(t))为函数f(h)的一个辅助函数。引理1:如果g(h,h(t))是f(h)的一个辅助函数,那么f(h)在如下的更新法则下是单调不增的,2.半非负矩阵分解(semi-nmf)半非负矩阵分解(semi-nmf)不对样本矩阵的符号做限制,从而扩大的nmf的应用范围。对于矩阵分解x≈wh来说,semi-nmf需要解决的最优化问题为:其更新迭代公式为:其中3.凸非负矩阵分解(convex-nmf)凸非负矩阵分解(convex-nmf)的主要思想是限制基图像矩阵中的列是原样本矩阵中的列的一个凸组合。对于矩阵分解x≈xwh来说,convex-nmf需要解决的最优化问题为:其更新迭代公式为:从上面semi-nmf和convex-nmf迭代公式可以看出,其中均出现了开算术平方根,这大大增加了算法的计算复杂度,降低了算法的计算效率。综上:1、非负矩阵分解算法(nmf)的应用范围较窄,仅适用于非负数据。2、传统半非负矩阵分解算法(semi-nmf)虽然扩大了非负矩阵分解算法的应用范围,但是其效果和收敛速度仍需提高。技术实现要素:本发明提供了一种基于e辅助函数的半非负矩阵分解的人脸识别方法,包括训练步骤,所述训练步骤包括如下步骤:第一步骤:将训练样本图像转化为训练样本矩阵x,设置误差阈值ε、最大迭代次数imax,并输入训练样本矩阵x、误差阈值ε和最大迭代次数imax第二步骤:对基图像矩阵w和系数矩阵h进行初始化;第三步骤:设置迭代次数n=0;第四步骤:根据公式(6)更新基图像矩阵w和系数矩阵h;第五步骤:使n=n+1;第六步骤:判断目标函数f(w,h)≤ε或迭代次数n是否达到最大迭代次数imax,如果是,那么输出基图像矩阵w和系数矩阵h,否则执行第四步骤;在第四步骤中,公式(6)如下:w←xht(hht)-1在公式(6)中,w表示基图像矩阵,h表示系数矩阵,x表示训练样本矩阵。作为本发明的进一步改进:该人脸识别方法还包括在训练步骤之后再执行识别步骤,所述识别步骤包括:第七步骤:计算训练样本中每类的平均特征向量mj(j=1,…,c);第八步骤:输入待识别人脸图像y,计算其特征向量hy=w-1y;第九步骤:计算待识别人脸图像的特征向量hy到每类的平均特征向量mj的距离,若hy与mj的距离最小,则将待识别人脸图像y归于第p类;第十步骤:输出类别p。本发明还提供了一种基于e辅助函数的半非负矩阵分解的人脸识别系统,包括训练模块,所述训练模块包括:输入模块:用于将训练样本图像转化为训练样本矩阵x,设置误差阈值ε、最大迭代次数imax,并输入训练样本矩阵x、误差阈值ε和最大迭代次数imax;初始化模块:用于对基图像矩阵w和系数矩阵h进行初始化;赋值模块:用于设置迭代次数n=0;更新模块:用于根据公式(6)更新基图像矩阵w和系数矩阵h;计数模块:使n=n+1;判断模块:判断目标函数f(w,h)≤ε或迭代次数n是否达到最大迭代次数imax,如果是,那么输出基图像矩阵w和系数矩阵h,否则执行更新模块;在更新模块中,公式(6)如下:w←xht(hht)-1在公式(6)中,w表示基图像矩阵,h表示系数矩阵,x表示训练样本矩阵。作为本发明的进一步改进:该人脸识别系统还包括在训练模块之后再执行识别模块,所述识别模块包括:平均特征向量计算模块:用于计算训练样本中每类的平均特征向量mj(j=1,…,c);特征向量计算模块:用于输入待识别人脸图像y,计算其特征向量hy=w-1y;距离计算模块:计算待识别人脸图像的特征向量hy到每类的平均特征向量mj的距离,若hy与mj的距离最小,则将待识别人脸图像y归于第p类;输出模块:用于输出类别p。本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现权利要求中所述的方法的步骤。本发明的有益效果是:本发明的人脸识别方法具有高识别性能与低计算复杂度的优势,通过在公开的人脸数据库中与相关算法进行实验比较,结果表明本专利开发的方法具有一定的优越性。附图说明图1是本发明的算法构造过程流程图;图2是本发明的方法流程图;图3是本发明提出的方法与相关算法(convex-nmf和semi-nmf)在orl人脸数据库上的识别率比较图,其中fsnmf表示本发明方法;图4是本发明方法与semi-nmf算法的收敛曲线比较图,其中fsnmf表示本发明方法。具体实施方式本发明首次提出了目标函数的e辅助函数的新概念,并据此提出了一种新的构造辅助函数的基本理论和框架,这大大扩充了辅助函数的选择范围,也为我们灵活构造辅助函数来设计新的高性能非负特征算法提供了强有力工具。根据本发明提出的e辅助函数的方法,我们构造了一种新的辅助函数,据此推导出了一种新的快速半非负矩阵分解(fsnmf)算法。由辅助函数的性质可知,本发明得到的fsnmf算法是收敛的。实验结果表明,本发明提出的fsnmf迭代方法与其他基于nmf的算法相比具有更好的识别率和更快的收敛速度。同时,本发明提出的e辅助函数方法还适用于开发其他生物特征识别迭代算法,以及证明算法的收敛性。一.关键词解释:1.符号说明:x矩阵xtx的转置|x|对矩阵x的每个元素取绝对值xij矩阵x的第ij个元素xj矩阵x的第j列矩阵a与b中对应元素的积矩阵a与b中对应元素的商ad矩阵a中每个元素的d次幂2.非负矩阵分解(non-negativematrixfactorization,nmf)nmf的基本思想是将一个非负样本矩阵近似分解为两个非负矩阵的乘积,即:x≈wh,其中,和分别被称为基图像矩阵和系数矩阵。并且,通过构建损失函数度量x与wh之间的逼近程度,通常损失函数是基于f-范数被定义的,写为:f(w,h)=||x-wh||2(1)这里||·||表示f-范数。3.半非负矩阵分解(semi-non-negativematrixfactorization,semi-nmf)semi-nmf不对样本矩阵的符号做限制,从而扩大的nmf的应用范围。对于样本矩阵考虑分解:x≈wh,其中,和即semi-nmf仅限制系数矩阵非负。二.具体技术方案:1.本发明的主要目的有:(1).拓展了nmf的应用范围,使其对含有负数的数据仍然有效;(2).提出了e辅助函数的新概念,据此给出了一种构造新的辅助函数的基本理论框架和方法。(3).根据提出的e辅助函数方法,开发出了一种新的具有高识别性能与低计算复杂度的快速半非负矩阵分解(fsnmf)人脸识别算法。2.技术方案:(1)e辅助函数的定义及性质:对于许多目标函数来说,构造合适辅助函数十分困难。例如,传统半非负矩阵分解算法中构造的辅助函数极为复杂,且得到的迭代公式的收敛速度较慢。为了克服这些不足,本专利首次提出了e辅助函数的概念,并基于e辅助函数得到了一种新的具有高识别性能与低计算复杂度的快速半非负矩阵分解(fsnmf)人脸识别算法。e辅助函数的定义与性质如下:定义2:对于任意的矩阵h和h(t),若e(h,h(t))满足条件e(h,h(t))≥0,且e(h(t),h(t))=0则称e(h,h(t))为函数f(h)的一个e辅助函数。定理1:若函数g(h,h(t))是函数f(h)的一个辅助函数,若函数e(h,h(t))是函数f(h)的一个e-辅助函数。则有:仍是f(h)的一个辅助函数,其中λ≥0。证明:由辅助函数及e辅助函数的定义,我们有:故可知仍是f(h)的一个辅助函数。定理1给出了一种基于e辅助函数来构造新的辅助函数的理论框架和方法,这大大扩充了辅助函数的选择范围,也为我们灵活构造辅助函数来设计新的高性能非负特征算法提供了强有力工具。(2)新fsnmf的提出:目标函数的构建对于样本矩阵考虑semi-nmf:x≈wh其中,和得到快速半非负矩阵分解算法(fsnmf)的目标函数为:f(w,h)=||x-wh||2(3)为了求解目标函数(3)中的两个未知矩阵w和h,我们将目标函数转化为两个子目标函数,分别为:f1(w)=||x-wh||2,其中h固定f2(h)=||x-wh||2,其中w固定则,问题(3)也演变成了两个子问题,分别为:minf1(w)(4)minf2(h)s.t.h≥0(5)对基图像矩阵w的学习固定h,由于f1(w)是凸的,同时对w的符号没有限制,故可知其极值点就是最优解。计算梯度并令其为0,有:可解得w的闭形式解:w=xht(hht)-1对系数矩阵h的学习固定w,我们先构造目标函数f2(h)的一个辅助函数g(h,h(t))。将目标函数f2(h)展开为:f2(h)=tr(xtx)-2tr(ht(wtx)+-ht(wtx)-)+tr((wtw)+-(wtw)-)hht对于等式右边最后两项,我们有:引理2:函数是tr((wtw)+hht)的一个辅助函数。引理3:函数g2(h,h(t))=-2tr((wtw)-h(t)ht)+tr((wtw)-h(t)h(t)t)是-tr((wtw)-hht)的一个辅助函数。由以上两个引理,我们可以得到定理2。定理2:函数是f2(h)的一个辅助函数。证明:由引理2和引理3可知,是tr((wtw)+hht)的辅助函数,是-tr((wtw)-hht)的辅助函数。故有g(h,h(t))是f2(h)的一个辅助函数。通常,更新迭代公式可直接由辅助函数推出。但这里由辅助函数g(h,h(t))推出的公式并不满足非负性,故我们需要借助e辅助函数来重新构造一个新的辅助函数。定理3:函数是f2(h)的一个e辅助函数。证明:显然,e(h,h(t))≥0,且e(h(t),h(t))=0故可知e(h,h(t))仍是f2(h)的一个e辅助函数。定理4:定义函数g(h,h(t))和e(h,h(t))如下:则是f2(h)的一个辅助函数。证明:由定理2和定理3可知:函数g(h,h(t))是函数f2(h)的一个辅助函数,且函数e(h,h(t))是函数f2(h)的一个e辅助函数。结合定理1,我们取λ=1,可直接推出仍是f2(h)的一个辅助函数。根据定义1与引理1,我们可知函数是函数f2(h)的一个上限,且为了得到的最小值,我们求解它的导数并令其为0,有由此式可解得h的更新迭代公式:通过简单的推导,可以证明该迭代公式也满足kkt条件。综上所述,本专利提出的fsnmf的更新迭代公式为:相较于传统的semi-nmf的迭代公式(2),本专利提出的的更新迭代公式(6)不仅在收敛速度和计算速度上有着较大的提高,同时有一个更好的识别效果。综上:如图2所示,本发明提供了一种基于e辅助函数的半非负矩阵分解的人脸识别方法,包括训练步骤,所述训练步骤包括如下步骤:第一步骤:将训练样本图像转化为训练样本矩阵x,设置误差阈值ε、最大迭代次数imax,并输入训练样本矩阵x、误差阈值ε和最大迭代次数imax;第二步骤:对基图像矩阵w和系数矩阵h进行初始化;第三步骤:设置迭代次数n=0;第四步骤:根据公式(6)更新基图像矩阵w和系数矩阵h;第五步骤:使n=n+1;第六步骤:判断目标函数f(w,h)≤ε或迭代次数n是否达到最大迭代次数imax,如果是,那么输出基图像矩阵w和系数矩阵h,否则执行第四步骤;在第四步骤中,公式(6)如下:w←xht(hht)-1在公式(6)中,w表示基图像矩阵,h表示系数矩阵,x表示训练样本矩阵,t表示矩阵的转置。该人脸识别方法还包括在训练步骤之后再执行识别步骤,所述识别步骤包括:第七步骤:计算训练样本中每类的平均特征向量mj(j=1,…,c),j表示第j类,c表示一共c个不同的人脸类别;第八步骤:输入待识别人脸图像y,计算其特征向量hy=w-1y,w表示基图像矩阵;第九步骤:计算待识别人脸图像的特征向量hy到每类的平均特征向量mj的距离,若hy与mj的距离最小,则将待识别人脸图像y归于第p类;第十步骤:输出类别p。输出类别p,表示待识别人脸图像y被识别为第p个人脸类别,所以输出类别p后,人脸识别就完成了。本发明还提供了一种基于e辅助函数的半非负矩阵分解的人脸识别系统,包括训练模块,所述训练模块包括:输入模块:用于将训练样本图像转化为训练样本矩阵x,设置误差阈值ε、最大迭代次数imax,并输入训练样本矩阵x、误差阈值ε和最大迭代次数imax;初始化模块:用于对基图像矩阵w和系数矩阵h进行初始化;赋值模块:用于设置迭代次数n=0;更新模块:用于根据公式(6)更新基图像矩阵w和系数矩阵h;计数模块:使n=n+1;判断模块:判断目标函数f(w,h)≤ε或迭代次数n是否达到最大迭代次数imax,如果是,那么输出基图像矩阵w和系数矩阵h,否则执行更新模块;在更新模块中,公式(6)如下:w←xht(hht)-1在公式(6)中,w表示基图像矩阵,h表示系数矩阵,x表示训练样本矩阵,t表示矩阵的转置。该人脸识别系统还包括在训练模块之后再执行识别模块,所述识别模块包括:平均特征向量计算模块:用于计算训练样本中每类的平均特征向量mj(j=1,…,c),j表示第j类,c表示一共c个不同的人脸类别;特征向量计算模块:用于输入待识别人脸图像y,计算其特征向量hy=w-1y,w表示基图像矩阵;距离计算模块:计算待识别人脸图像的特征向量hy到每类的平均特征向量mj的距离,若hy与mj的距离最小,则将待识别人脸图像y归于第p类;输出模块:用于输出类别p。本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现权利要求中所述的方法的步骤。表1是本专利提出的方法(ourmethod)与凸非负矩阵分解(convex-nmf)和半非负矩阵分解(semi-nmf)在orl人脸数据库上的识别率(%)比较(tn表示每一类的训练样本数)tn3456789convex-nmf72.2176.7983.7085.7587.1788.5088.50semi-nmf75.9380.9285.8586.0089.0090.1389.00ourmethod78.2982.9288.0588.5691.8391.6391.75表2是本专利提出的方法(ourmethod)与凸非负矩阵分解(convex-nmf)和半非负矩阵分解(semi-nmf)在orl人脸数据库上的识别速度(秒s)比较(tn表示每一类的训练样本数)tn3456789convex-nmf0.490.761.181.531.702.392.72semi-nmf0.530.630.951.081.091.241.38ourmethod0.460.560.880.890.901.091.21本发明的有益效果:1.本发明允许输入矩阵含有负数,扩大了nmf的应用范围。2.本专利提出了e辅助函数的新概念,据此给出了一种构造新的辅助函数的基本理论框架和方法。3.本发明的人脸识别方法具有高识别性能与低计算复杂度的优势。4.通过构造新的e辅助函数得到了识别效果更好,收敛速度更快迭代公式。5.本专利所提出的算法的收敛性,不仅通过利用辅助函数在理论上进行了证明,而且在实验中也得到了验证,我们的算法具有较高的收敛性。6.通过在公开的人脸数据库中与相关算法进行实验比较,结果表明本专利开发的方法具有一定的优越性。以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属
技术领域:
的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1