一种基于知识图谱的城市安全数据检索方法与流程
本发明涉及知识图谱下的海量数据存储与检索
技术领域:
,特别是一种基于知识图谱的城市安全数据检索方法。
背景技术:
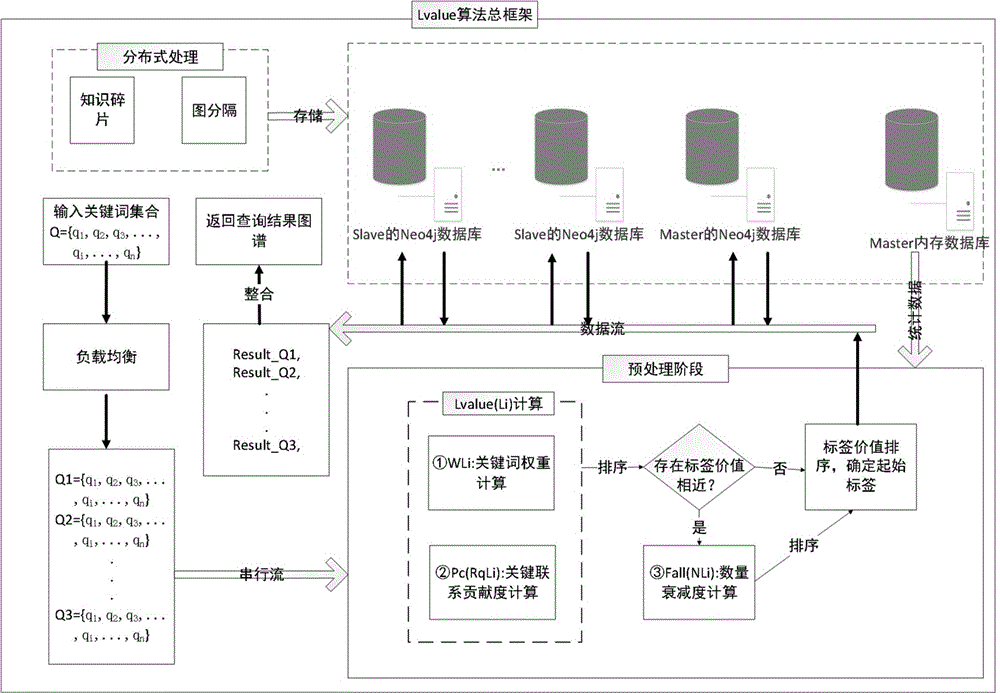
:由于知识图谱拥有强大的语义处理能力和开放组织能力,大规模知识图谱库的研究和应用在不同领域中都引起了足够的注意力。在城市安全领域中,随着城市的发展,风险隐患问题频频发生,城市事故总量与事故死亡人数显著上升,事故呈现多元化和频发性的发展趋势,因此科学的统筹经济社会发展与安全生产的理念被广泛推崇。为了对城市风险与隐患进行及时的预估与评判,减少事故发生的频率,同时提高对突发事故应急处理能力,对松散的城市安全数据碎片进行融合处理,建立强联系的基于rdf模型的城市安全知识图谱网络数据。由于图数据库具有处理强关系数据的优点,同时完全支持acid的事务管理,为大数据平台下的rdf图数据语义检索与推理提供了方法支撑,因此本发明采用图数据库存储城市安全知识图谱。为了提高图数据库的信息检索效率,大量国内外专家对检索策略进行了研究与改进。但是现有技术的缺点在于:目前图数据库的检索研究都是在已经确定起始节点的基础上进行算法优化,没有考虑到知识碎片的到来给图数据库带来动态变化的情况,由于在大量动态变化的数据节点下确定起始节点是一件非常耗时的工作,因此目前的检索方法在知识动态变化的情况下没有表现出良好的检索性能。技术实现要素:有鉴于此,本发明的目的是提出一种基于知识图谱的城市安全数据检索方法,能够提高检索速度,并且适应于在实时变化的指示下进行查询遍历。本发明采用以下方案实现:一种基于知识图谱的城市安全数据检索方法,包括以下步骤:步骤s1:neo4j分布式系统实时接收不断流入的知识碎片,并进行存储;步骤s2:输入关键词集合q,并将其传入到负载均衡处理器中进行负载均衡处理,将输入关键词分隔成多个关键词片段;步骤s3:将关键词片段串行流入预处理阶段,预处理阶段从master内存数据库中快速地获得统计数据后进行标签价值排序计算处理;步骤s4:计算关键词权重wli,关键词在一类标签中出现的次数比重越大其权重越大;在相互关联标签图中,通过关键词匹配、关键词在每个标签下出现的词频以及关键词比率计算被关键词锚定到的标签价值,并进行价值排序;步骤s5:计算关键关系贡献度pc(rqli),标签的关键关系在其所有关系中所占比重越大其贡献度越大;在相互关联标签图中,通过关键词匹配,计算关键词涉及到的标签中,关键关系占所有关系实例数量的比重来确定标签价值,并进行价值排序;步骤s6:计算数量衰减度fall(nli),标签下的实例越多越难锚定其衰减度越高;将wli与pc(rqli)按照一定的比例计算,对标签价值再排序,如果存在标签价值相近的情况则用数量衰减度fall(nli)对其进行最终价值排序;步骤s7:对每组数据进行标签价值排序,确定起始标签后,传入分布式集群进行查询;步骤s8:对查询结果进行整合,输出结果图谱。进一步地,步骤s4中,设q={q1,q2,q3,...,qi,...,qn}为输入的一组关键词集,lq为关键词集q锚定的标签集合,称为关键词标签集,gq为关键词标签集中的标签连接成的关联标签图;设inter_gq为相互关联标签图集合,inter_gq={inter_gq1,inter_gq2,...,inter_gqn}≦gq,linter_gqi={l1,l2,l3,...,li...,ln}为inter_gqi中的标签集,标签集中的标签相互之间都存在关系,故inter_gq为相互关联标签图集合,inter_gqi为相互关联标签图;设nlinter_gqi={nl1,nl2,nl3,...nli...,nln}为linter_gqi={l1,l2,l3,...,li...,ln}对应的节点集,li∈linter_gqi,li中的节点集为nli,nli中的实例节点随着知识碎片的到来动态变化,nli的改变量用△nli表示;qinter_gqi={q1,q2,q3,...,qi,...,qn}为锚定到linter_gqi中的关键词集,qli为锚定到li中的关键词集合,则qli≦qinter_gqi≦q;锚定到li中的关键词数量与锚定到linter_gqi={l1,l2,l3,...,li...,ln}中的关键词数量之比,计算公式如下:其中分子num(qli)为qli的数量,分母num(qinter_gqi)为qinter_gqi数量;相互关联标签图中的标签集合linter_gqi={l1,l2,l3,...,li...,ln}对应的权重为wl={wl1,wl2,wl3,...,wli,...,wln},由关键词决定的li标签权重称为关键词权重wli,所述关键词权重wli的计算采用下式:式中,分子部分tf(q,nli)为关键词q在标签li下的节点集nli中出现的词频,tf(q,△nli)为关键词q在标签li下的节点集改变量△nli中出现的词频,tf(q,nli)+tf(q,△nli)为关键词q在标签li下总词频,逐一遍历qli并累加结果,得到锚定到标签li中的关键词集qli在节点集nli与△nli中出现的总词频;分母部分关键词集qinter_gqi锚定到的标签集linter_gqi={l1,l2,l3,...,li...,ln}对应的节点集nlinter_gqi={nl1,nl2,nl3,...nli...,nln}随着知识碎片的到来节点集不断扩大,分母中的k取值k∈[1,n],表示遍历并累加关键词在nlinter_gqi与其变化量中出现的词频,得到关键词集qinter_gqi在标签集nlinter_gqi与其变化量中出现的总词频。进一步地,步骤s5中,设标签li关联的出度关系集合rli={r1,r2,r3,...,ri,...,rn},其中关键关系集合rqli={r1,r2,r3,...,ri,...,rm},rqli≦rli≦r,ri的起始标签与结束标签都被关键词锚定,固ri被称为关键关系;li中关键关系集合rqli中的关系数量与rli中的关系数量之比的计算采用下式:式中,△rqli与△rli分别表示由于知识碎片的到来,导致rqli与rli产生的变化量;标签li中关键关系集合rqli={r1,r2,r3,...,ri,...,rm}在rli={r1,r2,r3,...,ri,...,rn}中的贡献度,称为关键关系贡献度关键关系贡献度pc(rqli),其计算采用下式式中,其中分子部分标签li的关键关系rqli={r1,r2,r3,...,ri,...,rm}随着知识碎片的到来集合rqli不断扩大,分子中的k取值k∈[1,m],表示遍历并累加rqli与其变化量△rqli中的实例关系,得到标签li关键关系的实例总量;分母部分标签li关联的出度关系集合rli={r1,r2,r3,...,ri,...,rn}随着知识碎片的到来集合rli不断扩大,分母中的k取值k∈[1,n],表示遍历并累加rli与其变化量△rli中的实例关系,得到标签li所有出度关系的实例总量。进一步地,步骤s6具体包括以下步骤:步骤s61:获得标签li关键词权重wli与关键关系贡献度pc(rqli)后计算相互关联标签图中的标签价值lvalue(li),并进行排序,lvalue(li)的计算公式如下:lvalue(li)=αwli+βpc(rqli);式中,α,β分别表示wli的系数与pc(rqli)的系数;步骤s62:若存在标签价值相近的情况,则用数量衰减度对其进行最终价值排序,标签li中的节点数量nli越少,遍历越容易,反之越难,节点nli随着碎片知识动态变化,变化量为△nli;其中,数量衰减度的计算采用下式:与现有技术相比,本发明有以下有益效果:目前图数据库的检索研究都是在已经确定起始节点的基础上进行算法优化,没有考虑到知识碎片的到来给图数据库带来动态变化的情况,由于在大量动态变化的数据节点下确定起始节点是一件非常耗时的工作,因此目前的检索方法在知识动态变化的情况下没有表现出良好的检索性能。本发明利用neo4j图数据库的特点,将城市安全知识图谱rdf图数据以及不断流入的知识碎片映射到图数据库中,在分布式环境下,当多关键字遍布在多个相互关联标签节点上时,在相互作用的标签图中,根据关键词锚定到的实例节点与关键关系占比,以及标签间的占比快速地预先计算出价值最高的标签,从该标签开始遍历能最快速度的确定起始的实例节点,同时缩短了到下一跳关键节点的时间,提高了对动态变化知识图谱图的数据库检索效率。附图说明图1为本发明实施例的原理示意图。图2为本发明实施例的关联标签图与相互关联标签图。图3为本发明实施例的wli图解过程示意图。图4为本发明实施例的pc(rqli)图解过程示意图。具体实施方式下面结合附图及实施例对本发明做进一步说明。应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属
技术领域:
的普通技术人员通常理解的相同含义。需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。如图1所示,本实施例提供了一种基于知识图谱的城市安全数据检索方法,包括以下步骤:步骤s1:neo4j分布式系统实时接收不断流入的知识碎片,并进行存储;步骤s2:输入关键词集合q,并将其传入到负载均衡处理器中进行负载均衡处理,将输入关键词分隔成多个关键词片段;步骤s3:将关键词片段串行流入预处理阶段,预处理阶段从master内存数据库中快速地获得统计数据后进行标签价值排序计算处理;步骤s4:计算关键词权重wli,关键词在一类标签中出现的次数比重越大其权重越大;在相互关联标签图中,通过关键词匹配、关键词在每个标签下出现的词频以及关键词比率计算被关键词锚定到的标签价值,并进行价值排序;步骤s5:计算关键关系贡献度pc(rqli),标签的关键关系在其所有关系中所占比重越大其贡献度越大;在相互关联标签图中,通过关键词匹配,计算关键词涉及到的标签中,关键关系占所有关系实例数量的比重来确定标签价值,并进行价值排序;步骤s6:计算数量衰减度fall(nli),标签下的实例越多越难锚定其衰减度越高;将wli与pc(rqli)按照一定的比例计算,对标签价值再排序,如果存在标签价值相近的情况则用数量衰减度fall(nli)对其进行最终价值排序;步骤s7:对每组数据进行标签价值排序,确定起始标签后,传入分布式集群进行查询;步骤s8:对查询结果进行整合,输出结果图谱。lvalue算法的计算总公式如下式所示,先运行图1中预处理阶段的①②两步,对相互关联标签图中的标签进行价值排序,如果存在标签价值相近,再通过第③步判定最终的起始标签。在本实施例中,关键词权重wli算法将关键词锚定到的标签节点组合成关键词标签集,在关键词标签集中相互作用的标签构成一个或者多个相互关联标签图。在相互关联标签图中,每个标签都有自己的实例节点。随着知识碎片的到来,这些相互关联标签图中的标签和其对应的实例节点均会发生动态变化。由于从相互关联标签图中的任何一个标签开始遍历都能到达图中的其他标签,通过lvalue算法确定价值最高的起始标签,从该标签开始遍历能缩短锚定实例节点的时间与到达下一跳关键节点的时间。关键词权重wli在lvalue算法中的作用是计算关键词在标签li中出现的比重,是本发明算法的重要环节。步骤s4中,设q={q1,q2,q3,...,qi,...,qn}为输入的一组关键词集,lq为关键词集q锚定的标签集合,称为关键词标签集,gq为关键词标签集中的标签连接成的关联标签图;设inter_gq为相互关联标签图集合,inter_gq={inter_gq1,inter_gq2,...,inter_gqn}≦gq,linter_gqi={l1,l2,l3,...,li...,ln}为inter_gqi中的标签集,标签集中的标签相互之间都存在关系,故inter_gq为相互关联标签图集合,inter_gqi为相互关联标签图;如图2所示在关联标签图gq中存在两个相互关联标签图inter_gq1与inter_gq2,在相互关联标签图中的任何一个标签出发都能到达其他标签。设nlinter_gqi={nl1,nl2,nl3,...nli...,nln}为linter_gqi={l1,l2,l3,...,li...,ln}对应的节点集,li∈linter_gqi,li中的节点集为nli,nli中的实例节点随着知识碎片的到来动态变化,nli的改变量用△nli表示;qinter_gqi={q1,q2,q3,...,qi,...,qn}为锚定到linter_gqi中的关键词集,qli为锚定到li中的关键词集合,则qli≦qinter_gqi≦q;锚定到li中的关键词数量与锚定到linter_gqi={l1,l2,l3,...,li...,ln}中的关键词数量之比,计算公式如下:其中分子num(qli)为qli的数量,分母num(qinter_gqi)为qinter_gqi数量;相互关联标签图中的标签集合linter_gqi={l1,l2,l3,...,li...,ln}对应的权重为wl={wl1,wl2,wl3,...,wli,...,wln},由关键词决定的li标签权重称为关键词权重wli,所述关键词权重wli的计算采用下式:式中,分子部分tf(q,nli)为关键词q在标签li下的节点集nli中出现的词频,tf(q,△nli)为关键词q在标签li下的节点集改变量△nli中出现的词频,tf(q,nli)+tf(q,△nli)为关键词q在标签li下总词频,逐一遍历qli并累加结果,得到锚定到标签li中的关键词集qli在节点集nli与△nli中出现的总词频;分母部分关键词集qinter_gqi锚定到的标签集linter_gqi={l1,l2,l3,...,li...,ln}对应的节点集nlinter_gqi={nl1,nl2,nl3,...nli...,nln}随着知识碎片的到来节点集不断扩大,分母中的k取值k∈[1,n],表示遍历并累加关键词在nlinter_gqi与其变化量中出现的词频,得到关键词集qinter_gqi在标签集nlinter_gqi与其变化量中出现的总词频。关键词权重wli图解如图3所示,图中虚线关系r23为不断流入的知识碎片导致关系扩展部分,扩展的关系将相互关联标签图inter_gq1与inter_gq2合并成一个相互关联标签图inter_gqi。锚定到inter_gqi中的关键词集为qinter_gqi={q1,q2,q3,q4,q5},涉及到的标签集linter_gqi={l1,l2,l3,l4,l5,l6}对应的节点集nlinter_gqi={nl1,nl2,nl3,nl4,nl5,nl6},图中空心节点表示被关键词锚定的实例节点,实心节点表示未被关键词锚定的实例节点。标签li(li∈linter_gqi)对应的节点集nli,△nli是不断流入的知识碎片导致nli实例节点变化的部分,现计算li标签在inter_gqi中的关键词权重wli,由公式(3)得:1、当i=1时,ql1={q2,q3}是锚定到l1上的关键词。2、分子部分:ql1={q2,q3}在nl1与△nl1中出现的词频为4次q2,1次q3,4q2+1q3=5次。3、分母部分:qinter_gqi={q1,q2,q3,q4,q5}在标签集linter_gqi={l1,l2,l3,l4,l5,l6}对应的节点集nlinter_gqi={nl1,nl2,nl3,nl4,nl5,nl6}中出现的词频标签l15次+l25次+l37次+l45次+l53次+l61次=26次。4、关键词比率rate(ql1)中num(ql1)=2,num(qinter_gqi)=5,得到li中的关键词比率2/5。5、li在相互关联标签图中的关键词权重wl1=5/26*(2/5)=1/13。6、同理计算l2,l3,l4,l5,l6的关键词权重wl2=3/26,wl3=14/65,wl4=3/26,wl5=3/65,wl6=1/130。排序后得wl3wl4wl2wl1wl5wl6。在本实施例中,在相互关联标签图inter_gqi中,标签节点li存在一条或者多条出度,每条出度关系都有大量的实例关系,关键的实例关系占li总实例关系比重越大则表示li的关键关系贡献度越大,对li关系的遍历能更快地到达下一跳关键节点,因此计算关键关系贡献度是本发明算法的重要环节。步骤s5中,设标签li关联的出度关系集合rli={r1,r2,r3,...,ri,...,rn},其中关键关系集合rqli={r1,r2,r3,...,ri,...,rm},rqli≦rli≦r,ri的起始标签与结束标签都被关键词锚定,固ri被称为关键关系;li中关键关系集合rqli中的关系数量与rli中的关系数量之比的计算采用下式:式中,△rqli与△rli分别表示由于知识碎片的到来,导致rqli与rli产生的变化量;标签li中关键关系集合rqli={r1,r2,r3,...,ri,...,rm}在rli={r1,r2,r3,...,ri,...,rn}中的贡献度,称为关键关系贡献度关键关系贡献度pc(rqli),其计算采用下式:式中,其中分子部分标签li的关键关系rqli={r1,r2,r3,...,ri,...,rm}随着知识碎片的到来集合rqli不断扩大,分子中的k取值k∈[1,m],表示遍历并累加rqli与其变化量△rqli中的实例关系,得到标签li关键关系的实例总量;分母部分标签li关联的出度关系集合rli={r1,r2,r3,...,ri,...,rn}随着知识碎片的到来集合rli不断扩大,分母中的k取值k∈[1,n],表示遍历并累加rli与其变化量△rli中的实例关系,得到标签li所有出度关系的实例总量。关键关系贡献度pc(rqli)图解如图4所示,图中虚线关系r23为不断流入的知识碎片导致关系扩展部分,扩展的关系将相互关联标签图inter_gq1与inter_gq2合并成一个相互关联标签图inter_gqi。标签li(li∈linter_gqi)的总出度关系集合为rli,对应的关键关系集合为rqli,图中关系上的数字是关系实例数量加上关系实例变化量的总数量,现计算li标签在inter_gqi中的关键关系贡献度pc(rqli),由公式(5)得:1、当i=1时,l1的出度关系集合rl1={r1,r1’,r12},关键关系集合rql1={r12}。2、分子部分:l1的关键关系集合为rql1中关系实例数量加上变化量后的总数量是1000r12=1000。3、分母部分:l1的出度关系集合rl1中关系实例数量加上变化量后的总数量是1000r12+50r1+250r1’=1300。4、关键关系比率rate(rql1)中num(rqli+△rqli)/num(rli+△rli)=1/3。5、l1在相互关联标签图中的关键关系贡献度pc(rql1)=1000/1300*(1/3)=10/39。6、同理计算l2,l3,l4,l5,l6的关键关系共享度pc(rql2)=14/23,pc(rql3)=9/13,pc(rql4)=14/23,pc(rql5)=100/603,pc(rql6)=5/13。排序后得pc(rql3),pc(rql4),pc(rql2),pc(rql6),pc(rql1),pc(rql5)。在本实施例中,步骤s6具体包括以下步骤:步骤s61:获得标签li关键词权重wli与关键关系贡献度pc(rqli)后计算相互关联标签图中的标签价值lvalue(li),并进行排序,lvalue(li)的计算公式如下:lvalue(li)=αwli+βpc(rqli);式中,α,β分别表示wli的系数与pc(rqli)的系数;两个系数都是通过数据集训练后的取值,α=0.7,β=0.3。由上式得到inter_gqi中的标签集linter_gqi={l1,l2,l3,l4,l5,l6}的lvalue(li)值如表格1所示:表1lvalue(li)计算b/al1l2l3l4l5l6wli1/133/2614/653/263/651/130pc(rqli)10/3914/239/1314/23100/6035/13lvalue(li)0.1307690.2633780.3584620.2633780.0820590.120769价值排序③②①②⑤④当相互关联标签图中的标签通过lvalue(li)排序后,存在价值相近的标签,如表1中的标签l2与标签l4,此时可以通过标签中的数量衰减度决策出最终起始标签。步骤s62:若存在标签价值相近的情况,则用数量衰减度对其进行最终价值排序,标签li中的节点数量nli越少,遍历越容易,反之越难,节点nli随着碎片知识动态变化,变化量为△nli;其中,数量衰减度的计算采用下式:其中标签li中的实例节点数量以图2为准,lvalue(li)*fall(nli)计算标签价值如表2所示,得到价值最高的标签l3即为我们遍历的起始标签。表2lvalue计算b/al1l2l3l4l5l6lvalue(li)0.1307690.2633780.3584620.2633780.0820590.120769fall(nli)1/log2(12)1/log2(19)1/log2(11)1/log2(13)1/log2(14)1/log2(12)lvalue0.0373620.0627090.105430.0711830.0215940.034505价值排序④③①②⑥⑤以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1