基于基础负荷消减策略的用户负荷分类方法与流程
本发明属于电力系统负荷分类领域,具体为基于基础负荷消减策略的用户负荷分类方法。
背景技术:
负荷聚类是通过一定的数学手段,将大量的用户整合为一个个不同的聚合体。针对电网实时运营的情况,合理引导不同类别的聚合体有序用电,能够产生巨大的经济效益。而现有的聚类方法一般都是通过对负荷的走向和数值进行聚类。但是不同地区由于规模和用户数目不一致,导致同一类型或用电规律的用户不能被识别出来,造成分类结果不够精良。本发明针对上述问题,提出了基于负荷削减的一种聚类方法,通过模糊算法验证本发明聚类的结果。
现有技术中,也有通过其他方式实现负荷分类的方法。例如,申请号201810382946.7的中国专利公开了一种基于决策树的模糊c聚类的负荷分类方法,其先通过凝聚型层次聚类算法确定最优分类数目,然后采用模糊c均值聚类算法对负荷数据进行聚类,从而实现负荷分类。
技术实现要素:
本发明的目的是针对现有技术存在的问题,提供基于基础负荷消减策略的用户负荷分类方法,以解决当前负荷聚类方法中因为用户规模而错误识别用户类型的问题。
为实现上述目的,本发明采用的技术方案是:
基于基础负荷消减策略的用户负荷分类方法,包括以下步骤:
步骤1,提取用户负荷数据,对负荷数据进行预处理;
步骤2,选取削减负荷基准值,以聚合度为评价参数,采用削减基准负荷数值的方法区分负荷类型;
步骤3,根据负荷类型区分结果,采用模糊c均值算法对负荷数据进行聚类。
优选地,步骤1中的预处理步骤包括:定义偏差率η,
其中,yi表示某一点的负荷数据,
优选地,当η>500%时,需要查验数据是否为不良数据点,若当前负荷曲线绝大多数负荷点均超标,则认定为正常测量数据;若仅为个别点超标,则判定为不良数据点。
优选地,步骤2的具体过程为:
2.1,选取削减负荷基准值;
2.2,数据标准化;
2.3,计算数据梯度;
2.4,判断聚合度是否满足要求,若满足,则输出区分的复合类型,若不满足,则重新选取削减负荷基准值,转至2.2。
优选地,步骤3进一步包括:
3.1,确定分类个数、幂指数、隶属度矩阵;
3.2,计算聚类中心度;
3.3,修正隶属度函数和目标函数;
3.4,当隶属度函数满足终止限度或满足最大步长时,停止迭代,否则转至3.2。
优选地,对于隶属度函数,给定终止限度εj>0或定义最大步长l,当满足
优选地,隶属度和聚类中心度的迭代公式如下所示:
ij={1≤i≤c,dij=0}
当
当
优选地,步骤3进一步包括:设样本取自p元样本总体,把样本x1,x2,…xn总体划为c类,其中c的值不小于2,vi表示第i个聚类中心,设变量uij表示第i个样本对第j个样本的隶属度,则设定目标函数如下:
约束条件:
uij∈[0,1]1≤j≤n,1≤i≤c
根据拉格朗日乘数法计算最优解:
并根据给定的约束条件,在matlab中进行优化。
与现有技术相比,本发明的有益效果是:本发明针对当前负荷聚类方法中因为用户规模而错误识别用户类型的问题,提出了改进的负荷聚类算法处理技巧,利用模糊算法,验证本发明所提出的算法的精确性;本发明提出的算法具有更优良的聚类效果,可以根据工程或公司的实际需求,对负荷进行更有效的聚类。
附图说明
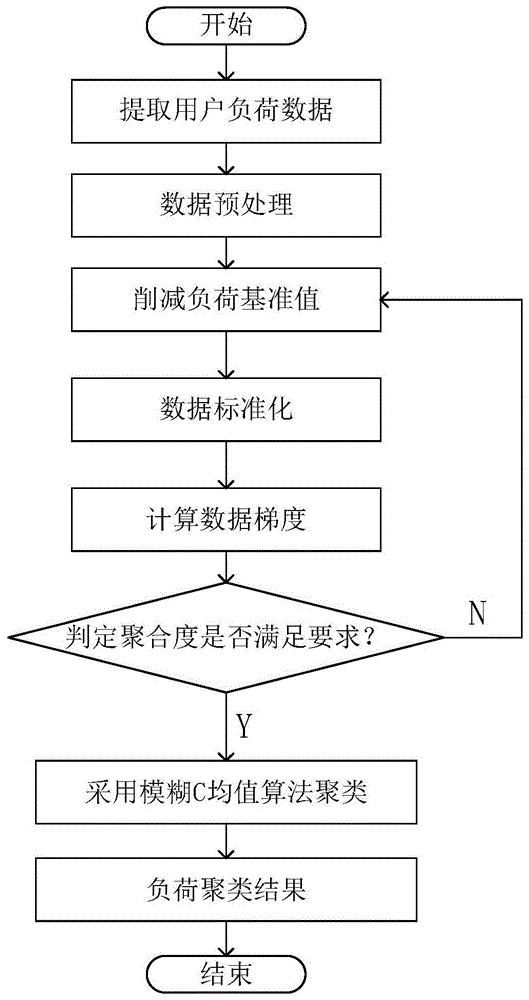
图1为本发明基于基础负荷消减策略的用户负荷分类方法的流程示意图;
图2(a)-(e)为传统模糊聚类结果示意图;
图3(a)-(c)为本发明方法得到的聚类结果示意图;
图4为c=3时聚类中心与轮廓值的关系示意图;
图5为c=5时聚类中心与轮廓值的关系示意图;
图中:q-负荷;t-时间;t-聚类中心;s(i)-轮廓值。
具体实施方式
下面将结合本发明中的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动条件下所获得的所有其它实施例,都属于本发明保护的范围。
如图1所示,本发明提供基于基础负荷消减策略的用户负荷分类方法,包括以下步骤:
步骤1,提取用户负荷数据,对负荷数据进行预处理;
步骤2,选取削减负荷基准值,以聚合度为评价参数,采用削减基准负荷数值的方法区分负荷类型。为了排除同一类型的负荷,因为地区规模和用户数目的差异,导致聚类结果不同的,本发明采用削减基准负荷数值的方法,放大负荷曲线的差异,使负荷曲线的梯度变大,从而区分负荷类型。
步骤2的具体过程为:
2.1,选取削减负荷基准值;
2.2,数据标准化;
2.3,计算数据梯度;
2.4,判断聚合度是否满足要求,若满足,则输出区分的复合类型,若不满足,则重新选取削减负荷基准值,转至2.2。
步骤3,根据负荷类型区分结果,采用模糊c均值算法对负荷数据进行聚类。本发明借助于l.a.zadeh(20世纪60年代)提出的模糊集的理论和ruspini和bezdek提出的模糊聚类算法,结合用户的用电习惯与用电特征,对负荷曲线进行直接聚类。
步骤3进一步包括:
3.1,确定分类个数、幂指数、隶属度矩阵;
3.2,计算聚类中心度;
3.3,修正隶属度函数和目标函数;
3.4,当隶属度函数满足终止限度或满足最大步长时,停止迭代,否则转至3.2。
经过上步骤以后,可以确定最终的隶属度函数矩阵中的元素和聚类中心,使得目标函数的值达到最小。
本发明在开始算法之初,对负荷数据进行预处理,排除地区规模与用户数目对聚类结果的影响,具有重要的现实意义。再针对不同类型用户的特点去进行聚类,效果更加优良。
实施例
本发明数据采用美国pjm电力市场的数据,选取24小时的负荷数据,对其进行算例分析演示。本实施例选取美国pjm电力市场不同地区的负荷数据,为了排除其他因素干扰,选取了113组统一工作日不同地区的负荷数据进行聚类分析。
(1)本发明首先针对数据进行预处理,剔除偏差过于剧烈的数据,防止极端数值对分类产生干扰。定义偏差率η:
式中yi表示某一点的负荷数据,
当η>500%时,需要查验数据是否为不良数据点,若该负荷曲线绝大多数负荷点均超标,认定为正常测量数据;若仅为个别点超标,判定为不良数据点。
(2)基准负荷削减值得选取。
为了排除同一类型的负荷,因为地区规模和用户数目的差异,导致聚类结果不同的,本发明采用削减基准负荷数值的方法,放大负荷曲线的差异,使负荷曲线的梯度变大,从而区分负荷类型。
(3)模糊算法
本实施例借助于l.a.zadeh(20世纪60年代)提出的模糊集的理论和ruspini和bezdek提出的模糊聚类算法,结合用户的用电习惯与用电特征,对负荷曲线进行直接聚类。设样本取自p元样本总体。把样本x1,x2,…xn总体划为c类,其中c的值不小于2。vi表示第i个聚类中心。设变量uij表示第i个样本对第j个样本的隶属度。
目标函数如下:
约束条件:
uij∈[0,1]1≤j≤n,1≤i≤c
根据拉格朗日乘数法计算最优解:
并根据系统给定的约束条件,在matlab中进行优化。
进一步地,根据拉格朗日乘数法,可以得到j(u,c)的最优解。隶属度和聚类中心度的迭代公式如下所示:
ij={1≤i≤c,dij=0}
当
当
模糊算法步骤如下:
1)确定分类个数c和幂指数m>1和隶属度矩阵
2)根据上述公式计算聚类中心度。
3)修正隶属度函数u(l)和目标函数j(l)。
其中,
4)对给定的隶属度函数终止限度εj>0或定义最大步长l。当满足
经过上步骤以后,可以确定最终的隶属度函数矩阵u中的元素和聚类中心v,使得目标函数的j(u,v)的值达到最小。
本发明针对当前负荷聚类方法中因为用户规模而错误识别用户类型的问题,提出改进的负荷聚类算法处理技巧,利用模糊算法,验证本发明所提出的算法的精确性。
对传统的负荷聚类算法与本发明的改进的负荷聚类算法进行比较,如附图所示。图2(a)-(e)为传统模糊聚类结果示意图。图3(a)-(c)为本发明方法得到的聚类结果示意图。对比传统方法的聚类效果,能够验证得到本发明采用的方法能有效地排除用户规模对用户类型的干扰。
对于传统方法,根据模糊算法结果可知,负荷大致可以分为5类,类别之间有如下区分:
(1)负荷峰谷值出现的时间点不同。第二类和第五类负荷与第四类负荷比较,峰值分别出现在9:00和8:00,存在明显时差。
(2)负荷曲线走向不一致。第二类、第四类和第五类负荷出现了双峰,而第一类与第三类在9:00至21:00时一直处于高负荷状态。
(3)峰谷值数存在值差异。第二类负荷和第四类峰值在4×104mw,谷值略小于3×104mw。对比第一三五类负荷,峰谷值降低5×103mw左右。
传统方法中,由于算法存在边界不清晰的问题,所以类别之间的交叉现象比较严重。针对电力系统而言,区分点(3)不利于负荷聚类。因为有些地区由于地区规模造成的峰谷值不一致时,不应单独区分开来。
而本发明采用负荷削减的方法,拉高了负荷变化梯度,可以解决由于用户规模不同而造成的误识别。其结果如图3(a)-(c)所示。
对比图2与图3,可知当分类结果变为3类以后,曲线的规律性明显加强,聚类依据中按照变化趋势的权重加大,有利于识别用户用电规律。根据图3,可以将负荷明显地分为平稳型负荷、双峰型负荷以及单峰型负荷。为针对不用地区、不用用电习惯的用户更好的制定需求侧响应的策略提供了良好的实验基础。
本发明采用轮廓值作为算法的一个指标。
具体地,采用轮廓值s(i)进行对比分析,
其中a表示第i个点的与同类别点标准化距离;b表示与不同类别点的标准化距离。轮廓值s(i)的取值范围为[-1,1],s(i)越大说明分类越合理。当s(i)<0时,说明该点分类不合理,还有更合理的分类方法。
如附图所示,图4为c=3时聚类中心与轮廓值的关系示意图。图5为c=5时聚类中心与轮廓值的关系示意图。
根据本发明提出的处理技巧,将负荷值削减一定的基准值之后,负荷之间的变化梯度被拉大,负荷重新划分聚类标准。根据图4可知,当聚类标准划分为5类时,第1类和第2类中有样本的隶属度出现负值,表明该点样本对聚类中心从属度低,存在更优的聚类方式。根据图5可知,当划分样本为3类时,样本轮廓值均为正且对于绝大部分样本,隶属度较高,是较为合理的分类方式。且该分类方式避免了因为电力负荷数据规模而造成误分类的现象。
对比传统方法的聚类效果可见,在分类数目从5类减少至3类时,从图4、图5对比发现,本发明算法的分类结果更加精确。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!