一种数据实用流化分散整合方法与流程
本发明涉及通信技术领域,尤其涉及一种数据实用流化整合分散方法。
背景技术:
在信息越来越发达的今天,人们对于数据信息的获取需求随之也越来越大,尤其是互联网这张大网所笼罩下的数据大幕,越来越受到人们的重视,人们强烈呼吁传输和处理海量数据的方法技术的更迭换代,其中数据的流化分散整合处理成为了提升网络数据实时传输性能的关键技术之一。
现有的数据流化方法体现在订阅方如果想要订阅一张数据表的某一块信息,必须将数据表中的全量数据订阅,这样订阅方才能获取其关注的信息,效率低下,而对于数据整合手段仅仅是整合数据表,而整合数据表无法对数据进行分解,无法做到单独提取订阅某一块信息,而且数据表与数据表之间无法实现信息关联。
技术实现要素:
本发明针对现有技术中的不足,提供了一种数据实用流化分散整合方法,将多张数据表进行数据打散,把数据解构到数据格级别,将不同数据表的格数据内容进行关联,实现关联订阅可对数据进行自由的组合、筛选,订阅方无需将一张数据表的全量数据订阅,只需订阅自己需要的,而且全流程的数据都进行流化处理,对数据的计算在流中处理,使采集与订阅满足实时性,订阅方可在秒内获取所需数据,既保证数据的实时性,又提高了效率。
为了解决上述技术问题,本发明通过下述技术方案得以解决:一种数据实用流化分散整合方法,包括步骤a):进行数据采集任务,采用快照的技术,快速取出数据库中的全量数据;步骤b):将数据表结构中的全量数据打散为格数据,再将打散的全量数据存储到数据库;步骤c):通过读取数据库的操作记录与变更时间,采集数据库增量数据,将增量数据直接流化处理;步骤d):用户进行选择订阅信息,该用户能自主选择所需的数据格数据,并选择计算模型来订阅计算后的信息;步骤e)包括数据初始化流程和数据增量流程,所述数据初始化流程包括以下步骤:步骤a1):进行初始化订阅任务,将用户需订阅的相关数据从存储的数据库中筛选出来,再还原成行数据,再对行数据进行流化处理,存入订阅数据流;步骤b1):取得订阅数据流中的全量数据,在数据流中对数据进行处理,转化成用户所需的数据;步骤c1):进行入库任务,把流化处理后的数据处理结果存储到用户指定的数据库中;所述数据增量流程包括以下步骤:步骤a2):进行增量订阅任务,采集到已流化的增量数据,存入订阅数据流;步骤b2):依序取得订阅数据流中的数据,在数据流中对数据进行处理,转化成用户需要的数据,对不需要计算的数据,照原样传输;步骤c2):进行入库任务,把流化处理后的计算结果存储到用户指定的位置中,保存到用户指定的数据库中。
上述技术方案中,优选的,所述步骤a),步骤b),步骤c),步骤d),步骤e)全流程的数据都进行流化处理,对数据的计算在流中处理,使采集与订阅满足实时性,订阅方可在秒内获取所需数据。
上述技术方案中,优选的,所述步骤a)中采用快照的技术取出数据库中的全量数据。
上述技术方案中,优选的,所述步骤b)是多张数据表进行格数据打散之后,将不同数据表的格数据内容进行关联,实现关联订阅。
上述技术方案中,优选的,所述步骤c)中的增量数据是依据数据库的操作记录与变更时间来获取,减少增量数据的数据量,提高采集效率,使数据可还原与备份任意时间点的数据。
上述技术方案中,优选的,所述增量任务处理数据的起始位置由所述初始化任务给出,使两个任务处理的数据达到无缝衔接,保障数据不会出现缺失、重复。
本发明一种数据实用流化整合分散方法,首先进行数据采集任务,取出数据库中的全量数据,再将数据表结构中的全量数据打散为格数据,再将打散的全量数据存储到数据库,通过读取数据库的操作记录与变更时间,采集数据库增量数据,将增量数据直接流化处理,接着由用户进行选择订阅信息,该用户能自主选择所需的数据格数据,并选择计算模型来订阅计算后的信息,随后进行初始化订阅任务,将用户需订阅的相关数据从存储的数据库中筛选出来,再还原成行数据,再对行数据进行流化处理,存入订阅数据流,取得订阅数据流中的全量数据,在数据流中对数据进行处理,转化成用户所需的数据,进行入库任务,把流化处理后的数据处理结果存储到用户指定的数据库中,接着进行增量订阅任务,采集到已流化的增量数据,存入订阅数据流,依序取得订阅数据流中的数据,在数据流中对数据进行处理,转化成用户需要的数据,对不需要计算的数据,照原样传输,进行入库任务,把流化处理后的计算结果存储到用户指定的位置中,保存到用户指定的数据库中。
1、本发明将全流程的数据进行流化处理,对数据的计算在流中处理,使采集与订阅满足实时性,订阅方可在秒内获取所需数据。
2、本发明将多张数据表进行格数据打散之后,将不同数据表的格数据内容进行关联,实现关联订阅。
3、本发明依据数据库的操作记录与变更时间获取增量数据,减少增量数据的数据量,提高采集效率,使数据可还原与备份任意时间点的数据。
4、本发明对全量数据打散后,用户可以只订阅所需的数据,无需订阅全量数据,提高了订阅效率与灵活性。
5、本发明使增量任务和初始化任务处理的数据达到无缝衔接,保障数据不会出现缺失、重复。
附图说明
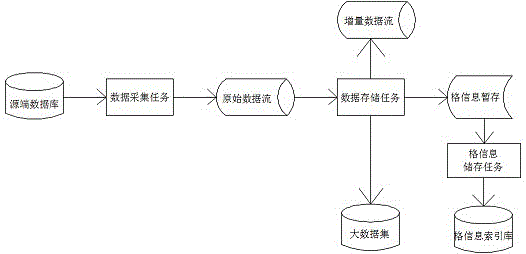
图1是本发明数据采集流程图。
图2是本发明初始化订阅任务流程图。
图3是本发明增量订阅任务流程图。
具体实施方式
下面结合实施例来进一步说明本发明,但本发明要求保护的范围并不局限于实施例表述的范围。
以人员信息订阅为例,员工信息表内容如下:
工号姓名出生年月办公地址
001张三1968年5月201
002李四1977年6月206
1.数据采集流程
数据采集任务线如图1所示。
1.1.数据采集任务
任务开启时为全量数据模式,从数据库中获取当前数据,存入原始数据流中,同时标注操作类型为“新增”,格式如下:
①新增记录:工号:001,姓名:张三,出生年月:1968年5月,办公地址:201
②新增记录:工号:002,姓名:李四,出生年月:1977年6月,办公地址:206
全量数据完成后,进入增量数据模式,从数据日志中获取数据变更情况,存入原始数据流中,数据格式如下:
③新增记录:工号:003,姓名:王五,出生年月:1992年3月,办公地址:502
④修改记录:工号001的员工姓名由张三改成张二
⑤修改记录:工号002的员工出生年月由1977年6月改成1976年6月
⑥修改记录:工号002的员工办公地址由206改成207
⑦删除记录:工号001的员工信息
1.2.数据存储任务
数据存储任务从原始数据流中获取要处理的数据,将数据原子化到格数据级别,为各格数据构造格信息,将格信息与格数据对应存入大数据集,格式如下:格信息格值操作时间人员信息表工号是001记录的工号001新增2018-10-1015:31:12.497人员信息表工号是001记录的姓名张三新增2018-10-1015:31:12.497人员信息表工号是001记录的出生年月1968年5月新增2018-10-1015:31:12.497人员信息表工号是001记录的办公地址201新增2018-10-1015:31:12.497人员信息表工号是002记录的工号002新增2018-10-1015:31:12.502人员信息表工号是002记录的姓名李四新增2018-10-1015:31:12.502人员信息表工号是002记录的出生年月1977年6月新增2018-10-1015:31:12.502人员信息表工号是002记录的办公地址206新增2018-10-1015:31:12.502人员信息表工号是003记录的工号003新增2018-10-1015:33:57.984人员信息表工号是003记录的姓名王五新增2018-10-1015:33:57.984人员信息表工号是003记录的出生年月1992年3月新增2018-10-1015:33:57.984人员信息表工号是003记录的办公地址502新增2018-10-1015:33:57.984人员信息表工号是001记录的姓名张二修改2018-10-1015:36:12.652人员信息表工号是002记录的出生年月1976年6月修改2018-10-1015:36.48.687人员信息表工号是002记录的办公地址207修改2018-10-1015:38.40.536人员信息表工号是001记录的工号001删除2018-10-1015:38.48.762
按序将格信息暂存:
人员信息表工号是001记录的工号
人员信息表工号是001记录的姓名
人员信息表工号是001记录的出生年月
人员信息表工号是001记录的办公地址
人员信息表工号是002记录的工号
人员信息表工号是002记录的姓名
人员信息表工号是002记录的出生年月
人员信息表工号是002记录的办公地址
人员信息表工号是003记录的工号
人员信息表工号是003记录的姓名
人员信息表工号是003记录的出生年月
人员信息表工号是003记录的办公地址
人员信息表工号是001记录的姓名
人员信息表工号是001记录的工号
同时将数据按序以增量格式存入增量数据流:
①新增记录:工号:001,姓名:张三,出生年月:1968年5月,办公地址:201,操作时间:2018-10-1015:31:12.497
②新增记录:工号:002,姓名:李四,出生年月:1977年6月,办公地址:206,操作时间:2018-10-1015:31:12.502
③新增记录:工号:003,姓名:王五,出生年月:1992年3月,办公地址:502,操作时间:2018-10-1015:33:57.984
④修改记录:工号001的员工姓改成张二,操作时间:2018-10-1015:36:12.652
⑤修改记录:工号002的员工出生年月改成1976年6月,操作时间:2018-10-1015:36.48.687
⑥修改记录:工号002的员工办公地址改成207,操作时间:2018-10-1015:38.40.536
⑦删除记录:工号001的员工信息,操作时间:2018-10-1015:38.48.762
1.3.格信息存储任务
从格信息暂存中获取格信息,按序存入格信息索引库。格信息暂存是为了在生成格信息时保持高速;存入格信息索引库一是为了固化存储格信息,二是为了给格信息构造索引,提高可以检索效率。
2.用户进行订阅
假定在15时32分开启订阅任务,另有一个计算模型可将出生年月转换成年龄。
用户选择订阅工号、姓名、年龄字段(在出生年月字段上选择了年龄计算模型)。
3.数据初始化订阅任务流程和增量订阅任务流程
订阅开启后,先开启订阅初始化订阅流程,初始化任务完成后,记录下最后操作时间,替换上增量订阅任务。
3.1.初始化订阅任务流程
初始化订阅任务线如图2所示,初始化任务先从格信息索引库中检索出用户关心的姓名、年龄字段,检索得到格信息如下:
人员信息表工号是001记录的工号
人员信息表工号是001记录的姓名
人员信息表工号是001记录的出生年月
人员信息表工号是002记录的工号
人员信息表工号是002记录的姓名
人员信息表工号是002记录的出生年月
这一过程去除用户不关心的信息,简化数据传输内容,提高处理速度。
由这些格信息,自大数据集中检索出数据:格信息格值操作时间人员信息表工号是001记录的工号001新增2018-10-1015:31:12.497人员信息表工号是001记录的姓名张三新增2018-10-1015:31:12.497人员信息表工号是001记录的出生年月1968年5月新增2018-10-1015:31:12.497人员信息表工号是001记录的办公地址201新增2018-10-1015:31:12.497人员信息表工号是002记录的工号002新增2018-10-1015:31:12.502人员信息表工号是002记录的姓名李四新增2018-10-1015:31:12.502人员信息表工号是002记录的出生年月1977年6月新增2018-10-1015:31:12.502人员信息表工号是002记录的办公地址206新增2018-10-1015:31:12.502
再将得到的信息整理成行数据,存入订阅数据流中,格式如下:
①新增记录:工号:001,姓名:张三,出生年月:1968年5月,办公地址:201
②新增记录:工号:002,姓名:李四,出生年月:1977年6月,办公地址:206
并记录下最后操作时间是2018-10-1015:31:12.502。
3.2.增量订阅任务流程
增量订阅任务线如图3所示,增量数据由本系统的采集任务提供主要是有三种形式:增、删、改,记录下原表的数据变更情况。
订阅增量任务从增量数据流中依序获取数据记录,针对各类情况作出初步处理,并存入订阅数据流。
首先去除初始化任务标记时间之前的记录:
①新增记录:工号:001,姓名:张三,出生年月:1968年5月,办公地址:201,操作时间:2018-10-1015:31:12.497
②新增记录:工号:002,姓名:李四,出生年月:1977年6月,办公地址:206,操作时间:2018-10-1015:31:12.502
针对记录③去除用户不关心的字段信息,变为:
③新增记录:工号:003,姓名:王五,出生年月:1992年3月,操作时间:2018-10-1015:33:57.984
针对记录④⑤,都是用户关心的字段,照原样传输:
④修改记录:工号001的员工姓改成张二,操作时间:2018-10-1015:36:12.652
⑤修改记录:工号002的员工出生年月改成1976年6月,操作时间:2018-10-1015:36.48.687
针对记录⑥,是用户不关心的字段,不传输
针对记录⑦也是原样传输:
⑦删除记录:工号001的员工信息,操作时间:2018-10-1015:38.48.762
3.3.计算
依序取得订阅数据流中的数据,对涉及的字段加以计算,转化成用户需要的信息,存入计算结果流,对不需要计算的记录,照原样传输,记录如下:
初始化部分:
①新增记录:工号:001,姓名:张三,年龄:51
②新增记录:工号:001,姓名:李四,年龄:42
增量部分:
③新增记录:工号:003,姓名:王五,年龄:27
④修改记录:工号001的员工姓名改成张二
⑤修改记录:工号002的员工年龄改成了43
⑦删除记录:工号001的员工信息
3.4.入库任务
依序从计算结果流中取得数据,保持顺序处理记录。
对新增记录,例如记录①②③,转化成insert语句在目标库中执行
对修改记录,例如记录④⑤,转化成按主键变更单字段的update语句在目标库中执行。在此仅对字段进行操作,可提高操作的准确性,从而提高任务的整体效率
对删除记录,例如记录⑦,转化成delete语句在目标库中执行。
处理完①②③记录后,目标库内数据情况如下:
工号姓名年龄
001张三51
002李四42
003王五27
处理完④⑤修改记录后,目标库内数据情况如下:
工号姓名年龄
001张二51
002李四43
003王五27
处理完⑦修改记录后,目标库内数据情况如下:
工号姓名年龄
002李四43
003王五27。
- 还没有人留言评论。精彩留言会获得点赞!