针对任意视角汽车图片的细粒度车型识别方法与流程
本发明涉及一种车型识别方法,特别涉及一种针对任意视角汽车图片的细粒度车型识别方法。
背景技术:
随着科技的发展,汽车成为了越来越普遍的交通工具,随之而来的车辆管理的问题也凸显了出来。为了解决这个问题,智能交通系统应运而生,而作为智能交通系统重要组成部分的车型识别系统也成为了热门的研究内容。近些年提出的车型识别方法主要分为两大类:传统方法和深度学习方法。
传统方法主要是利用一些人工设计的特征进行车型识别,例如mcnmsnagmode在文献“nagmodemcnms.vehicleclassificationusingsift[c]//internationaljournalofengineeringresearchandtechnology.esrsapublications,2014.”中提出使用sift特征进行车型识别。但是采用传统的人工设计的特征来描述图像,不能够很好的描述图像的高层语义信息,从而使得识别的准确率不能够很理想,并且特征表示的泛化能力较差。
深度学习方法主要是利用卷积神经网络学习特征,从而利用学习到的特征进行车型识别分类,例如“huangk,zhangb.fine-grainedvehiclerecognitionbydeepconvolutionalneuralnetwork[c]//20169thinternationalcongressonimageandsignalprocessing,biomedicalengineeringandinformatics(cisp-bmei).ieee,2016:465-470.”中提出的车型识别方法。该文章中的车型识别方法的只是使用普通的卷积神经网络和r-cnn结合来进行分类,并没有针对细粒度分类这个特殊问题进行一些特别的设计,所以得到的识别准确率较低,在50类的车型数据集上,平均只得到了百分之六十的识别准确率,并且该方法仅针对视角固定的汽车图片进行分类识别。
技术实现要素:
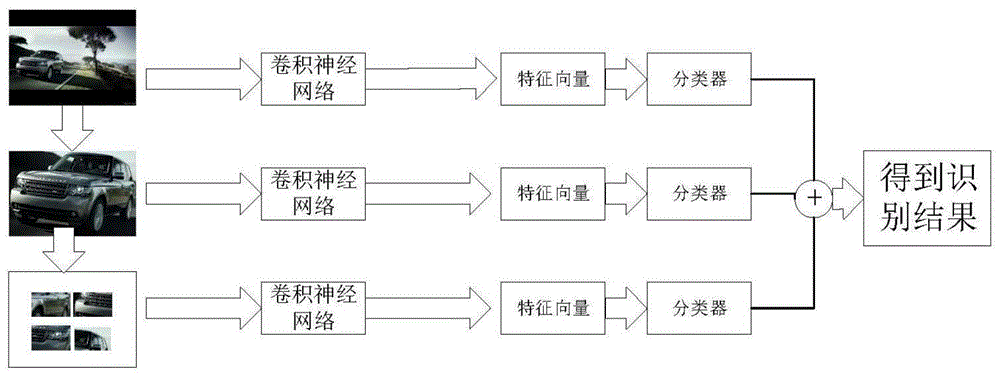
为了克服现有车型识别方法车型识别准确率低的不足,本发明提供一种针对任意视角汽车图片的细粒度车型识别方法。该方法首先根据stanfordcars数据集训练第一个分支网络,再使用fasterr-cnn对原始图片中的汽车区域进行定位,去除大部分背景,得到裁剪后的图片,使用裁剪后的图片训练第二个分支网络,利用selectivesearch方法处理裁剪后的图片,得到多幅子图,使用第二个分支网络对这些子图进行筛选,将保留下来的图片送入第三个分支网络进行训练,然后确定每个分支网络的输出权重,将原始图片和经过fasterrcnn和selectivesearch生成的图片分别送入三个分支网络中,对网络的输出加权求和,此时最大输出值对应的类别即为所识别的车型类别。本发明不仅提高了车型识别准确率,并且能够对任意视角的汽车图片进行识别。
本发明解决其技术问题所采用的技术方案:一种针对任意视角汽车图片的细粒度车型识别方法,其特点是包括以下步骤:
步骤一、先将数据集原始图片送入vgg网络中进行训练,训练具有识别n类车型能力的网络模型,所述网络模型的训练是在imagenet上预训练好的网络模型的基础上进行finetuning训练,完成第一个分支网络的训练。
步骤二、利用预训练好的fasterr-cnn模型,对数据集原始图片中的汽车区域进行定位,得到相应的boundingbox,然后裁剪掉不必要的背景信息,得到裁剪后的汽车图片数据集。
步骤三、将裁剪后的汽车图片数据集送入第二个vgg网络中,进行同步骤一类似的finetuning训练,得到训练好的第二个分支网络模型。
步骤四、对裁剪后的汽车图片数据集使用ss方法进行图片信息的挖掘,生成多幅子图,将生成的子图送入第二个训练好的vgg网络模型中,得到多个分类概率向量,若向量中的最大值大于0.5,则保留该子图,否则删除。然后将这些保留下来的子图送入第三个vgg网络中进行finetuning训练,得到第三个训练好的vgg网络模型。
步骤五、步骤一到四得到三个训练好的vgg网络模型网络结构相同,但是不共享任何参数。
步骤六、根据三个分支网络在数据集上的分类效果,给不同分支网络的输出赋予不同的权重,权重分别是0.3,0.5,0.2。
步骤七、将测试图片的原始图片同时分别送入第一个vgg网络和fasterrcnn网络中,得出第一个vvg网络输出的分类概率向量和原始图片的boundingbox。
步骤八、根据步骤七得到的boundingbox裁剪原始图片,得到裁剪后的图片,将裁剪后的图片送入第二个vgg网络中,得到第二个分类概率向量。同时对裁剪后的图片使用ss生成多幅子图,再将多幅子图送入第二个vgg网络中,得到多个分类概率向量,然后求取每个概率向量的最大值,只保留取到最大值所对应的那张子图。将得到的唯一一张子图送入第三个vgg网络中,得到第三个分类向量。
步骤九、将得到的分类向量与步骤六中赋予每个分支网络的权重对应相乘,再将相乘得到的三个值再相加,得到一个向量,最大值所对应的类别即是所识别的汽车类别序号。
步骤十、再根据字典查找出汽车类别序号对应的汽车类别名称,实现车型识别。
本发明的有益效果是:该方法首先根据stanfordcars数据集训练第一个分支网络,再使用fasterr-cnn对原始图片中的汽车区域进行定位,去除大部分背景,得到裁剪后的图片,使用裁剪后的图片训练第二个分支网络,利用selectivesearch方法处理裁剪后的图片,得到多幅子图,使用第二个分支网络对这些子图进行筛选,将保留下来的图片送入第三个分支网络进行训练,然后确定每个分支网络的输出权重,将原始图片和经过fasterrcnn和selectivesearch生成的图片分别送入三个分支网络中,对网络的输出加权求和,此时最大输出值对应的类别即为所识别的车型类别。本发明不仅提高了车型识别准确率,并且能够对任意视角的汽车图片进行识别。
由于采用深度卷积神经网络提取特征,所以能够充分有效地挖掘图片中包含的语义信息,使得车型识别的精度度和鲁棒性得到了提升。经测试,在相同条件下,车型识别准确率由背景技术的60%提高到89.9%。
下面结合附图和具体实施方式对本发明作详细说明。
附图说明
图1是本发明针对任意视角汽车图片的细粒度车型识别方法的流程图。
具体实施方式
参照图1。
选择公开的compcars数据集,按照标准划分方式,将compcars数据集中的8144张图片划分为训练集,其余的8041张设置为测试集。本发明针对任意视角汽车图片的细粒度车型识别方法具体步骤如下:
步骤一、先将数据集原始图片送入vgg网络中进行训练,训练具有识别n类车型能力的网络模型,所述网络模型的训练是在imagenet上预训练好的网络模型的基础上进行finetuning训练,完成了第一个分支网络的训练。
步骤二、利用预训练好的fasterr-cnn模型,对数据集原始图片中的汽车区域进行定位,得到相应的boundingbox,然后裁剪掉不必要的背景信息,得到裁剪后的汽车图片数据集。
步骤三、将裁剪后的汽车图片数据集送入第二个vgg网络中,进行同步骤一类似的finetuning训练,得到了训练好的第二个分支网络模型。
步骤四、对裁剪后的汽车图片数据集使用ss方法进行进一步的图片信息的挖掘,生成多幅子图,将生成的子图送入第二个训练好的vgg网络模型中,得到多个分类概率向量,若向量中的最大值大于0.5,则保留该子图,否则删除。然后将这些保留下来的子图送入第三个vgg网络中进行finetuning训练,得到第三个训练好的vgg网络模型。
步骤五、步骤一到四得到三个训练好的vgg网络模型网络结构相同,但是不共享任何参数。
步骤六、根据三个分支网络在数据集上的分类效果,给不同分支网络的输出赋予不同的权重,权重分别是0.3,0.5,0.2。
步骤七、将测试图片的原始图片同时分别送入第一个vgg网络和fasterrcnn网络中,得出第一个vvg网络输出的分类概率向量和原始图片的boundingbox。
步骤八、根据步骤七得到的boundingbox裁剪原始图片,得到裁剪后的图片,将裁剪后的图片送入第二个vgg网络中,得到第二个分类概率向量。同时对裁剪后的图片使用ss生成多幅子图,再将多幅子图送入第二个vgg网络中,得到多个分类概率向量,然后求取每个概率向量的最大值,只保留取到最大值所对应的那张子图。将得到的唯一一张子图送入第三个vgg网络中,得到第三个分类向量。
步骤九、将得到的分类向量与步骤六中赋予每个分支网络的权重对应相乘,再将相乘得到的三个值再相加,得到一个向量,最大值所对应的类别即是所识别的汽车类别序号。
步骤十、再根据字典查找出汽车类别序号对应的汽车类别名称,实现车型识别。
经测试,本发明在stanfordcars数据集上获得了89.9%的识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!