一种基于马尔可夫决策过程和k-最近邻强化学习的排序方法与流程
本发明涉及一种基于马尔可夫决策过程和k-最近邻强化学习的排序方法,属于信息检索技术领域。
背景技术:
随着互联网的快速发展,learningtorank技术也越来越受到关注,这是机器学习常见的任务之一。信息检索时,给定一个查询目标,我们需要算出最符合要求的结果并返回,这里面涉及一些特征计算、匹配等算法,对于海量的数据,如果仅靠人工来干预其中的一些参数来进行排序的话,是远远不能达到要求的,而learningtorank算法就是用来解决这种问题的。在信息检索领域,排序学习的核心问题之一是开发新颖算法,通过直接优化评估度量例如归一化折扣累积增益(ndcg)来构造排序模型。现有的方法通常集中于优化在固定位置计算特定评估度量,例如在固定位置k计算的ndcg。在信息检索中,评估度量包括广泛使用的ndcg和p@k,在固定位置计算的ndcg包含的文档信息量有限,并不能完全体现用户的查询目标。通常计算在所有排名位置的文档排序,这种方法比仅在单个位置计算文档排名提供更丰富的信息。因此,设计一种算法,它能够利用在所有的排序位置上计算的度量,来学习更好的排序模型变得很有意义。其次,仅仅依靠相关性来给文档打分具有一定的片面性,有时用户需要返回的文档不仅需要高相关性,对返回结果的多样性仍有一定的需求,传统的排序学习方法大多只考虑到了文档的相关性,忽视了文档多样性,没有解决查询结果文档的多样性问题。
技术实现要素:
本发明要解决的技术问题是为了克服上述现有技术存在的缺陷而提供一种基于马尔可夫决策过程和k-最近邻强化学习的排序方法。
本发明的技术方案是:一种基于马尔可夫决策过程和k-最近邻强化学习的排序方法,具体步骤为:
(1)将原始数据文件平均分成5个组,每组对应一个子数据集,方便实现k折交叉验证实验,对这些数据集中的各个数据项进行预处理,生成候选数据集;
(2)读取步骤(1)所述的候选数据集,设定算法的输入参数包括学习率η,折扣因子γ,奖励函数r,随机初始化学习参数w,中间参数δw初始化为0;
(3)读取步骤(2)所述的参数,完成取样序列e,返回一个序列e;
(4)计算步骤(2)所述的取样序列e的长期累积折扣奖励;
(5)计算在时间步t参数w的梯度,并计算更新中间参数δw;
(6)重复步骤(3)到(5),计算更新参数w,直至参数收敛,程序结束。
所述步骤(3)具体包括以下步骤:
11)初始化环境状态st和序列e;
12)假设查询q所检索到的文档有m个,对于排序过程在时间步t=0至t=m-1,根据马尔可夫决策过程模型的策略,由当前环境的状态st选择一个动作at(文档);
其中,a(st)是当前环境状态st下所有可选择的动作集合,t表示时间步,假设at∈a(st)是当前环境的状态st选择的一个动作,
13)应用奖励函数r,计算在该环境状态st下选择动作at的奖励回报rt+1;
其中,
14)根据状态转移函数,改变环境状态st至st+1;
15)应用欧式距离,计算所选动作at的k个最近邻动作(文档);
16)将14)计算出的k个最近邻动作(文档),从候选文档集中删除;
17)添加元组(st,at,rt+1)至序列e中,完成一个位置排序;
18)完成m次采样序列,得到序列(s0,a0,r1,……,sm-1,am-1,rm)。
所述步骤(4)中计算步骤(2)所述的取样序列的累积长期折扣奖励,并用gt表示:
其中,γ是预先设定的折扣因子,γk-1表示随着时间步t的增加,折扣因子的作用逐渐减小的变化,rt+k表示从时间步t=0开始的奖励回报。
所述步骤(5)具体包括以下步骤:
21)计算在时间步t的参数w的梯度,并用
其中,a(t)是当前环境状态st下所有可选择的动作集合,t表示时间步,
22)计算更新在所有时间步t的累积梯度,并用
其中,γt是随时间步t的增加,折扣因子逐渐减小的表示。gt是从时间步t=0直至t=m-1的取样序列的累积长期折扣奖励。
23)计算更新中间参数δw,并用δw表示:
其中,γt是随时间步t的增加,折扣因子逐渐减小的表示。gt是从时间步t=0直至t=m-1的取样序列的累积长期折扣奖励。
所述步骤(6)具体包括以下步骤:
31)计算更新参数w,并用w表示:
w=w+δw;(8)
其中,w是模型参数,其维度与文档特征一致。δw是模型的中间参数。
本发明的有益效果是:本发明基于马尔可夫决策过程模型框架,提出了一种应用k-最近邻的文档排序方法,方法大大提高了的排序准确率;同时,智能化的为用户提供高相关性和多样性的文档搜索结果,节省用户的文档搜索时间,通过高效的文档排序更快更准确的使用户检索到符合其查询的文档。
附图说明
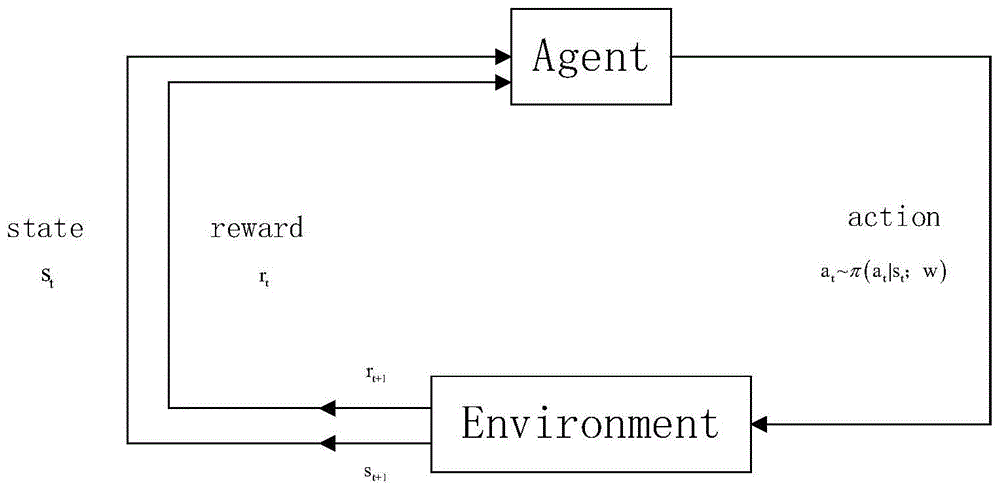
图1是本发明马尔可夫决策过程中agent和环境的交互图;
图2是本发明流程图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明进一步地详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
如图1所示,将文档排序过程建模为马尔可夫决策过程,图中的agent相当于本发明的算法,environment相当于查询用户。m个文档的排序问题形式化决策问题。每一个动作对应于选择一个文档。马尔可夫决策过程是一个agent与环境交互的过程,因此有一个离散的时间序列,t=0,1,2,…m,在每一个时刻t,agent都会接收一个用来表示现处环境的状态st∈s,其中s表示所有可能状态的集合,并且在现处状态st的基础上选择一个动作at∈a(st),其中a(st)表示在状态st时所有可能采取的动作的集合,在t时刻agent采取一个动作后,环境的状态由st更新为st+1,在时间步t+1,agent会收到一个奖励回报值rt+1∈r。在每个时间步t,动作的选择取决于策略函数policy。
如图2所示,针对基于马尔可夫决策过程和k-最近邻强化学习的排序方法,其特征在于,包括以下步骤:
1、将原始数据文件平均分成5个组,每组对应一个子数据集,方便实现k折交叉验证实验,其中k设定为5,对这些数据集中的各个数据项进行预处理,生成候选数据集。
2、读取步骤1所述的候选数据集,设定算法的输入参数包括学习率η=0.0001,折扣因子γ=1,奖励函数r,随机初始化学习参数w,中间参数δw初始化为0。
3、读取步骤2所述的参数,完成取样序列e,返回一个序列e,初始化环境状态st和序列e。假设查询q所检索到的文档有m个,对于排序过程在时间步t=0至t=m-1,根据马尔可夫决策过程模型的策略,由当前环境的状态st选择一个动作at(文档),
其中,a(st)是当前环境状态st下所有可选择的动作集合,t表示时间步,假设at∈a(st)是当前环境的状态st选择的一个动作,
3.1、应用奖励函数r(2),计算在该环境状态st下选择动作at的奖励回报rt+1;
其中,
3.2、根据状态转移函数,改变环境状态st至st+1;
3.3、应用欧式距离公式(3),计算所选动作at的k个最近邻动作(文档)。计算出的k个最近邻动作(文档),从候选文档集中删除;添加元组(st,at,rt+1)至序列e中,完成一个位置排序。完成m次采样序列,得到序列(s0,a0,r1,……,sm-1,am-1,rm)。
4、计算步骤(2)所述的取样序列e的长期累积折扣奖励,并用gt表示:
其中,γ是预先设定的折扣因子,γk-1表示随着时间步t的增加,折扣因子的作用逐渐减小的变化,rt+k表示从时间步t=0开始的奖励回报。
5、计算在时间步t参数w的梯度,并用
其中,a(t)是当前环境状态st下所有可选择的动作集合,t表示时间步,
5.1、计算更新在所有时间步t的累积梯度,并用
其中,γt是随时间步t的增加,折扣因子逐渐减小的表示。gt是从时间步t=0直至t=m-1的取样序列的累积长期折扣奖励。
5.2、计算更新中间参数δw,并用δw表示:
其中,γt是随时间步t的增加,折扣因子逐渐减小的表示。gt是从时间步t=0直至t=m-1的取样序列的累积长期折扣奖励。
6、计算更新参数w,直至参数收敛,程序结束。
w=w+δw;(8)
其中,w是模型参数,其维度与文档特征一致。δw是模型的中间参数。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!