一种面向非连通图的Top-K相似匹配方法与流程
本发明属于图数据挖掘领域,涉及图结构分析和图匹配等方面,尤其涉及一种面向非连通图的top-k相似匹配方法。
背景技术:
随着大数据时代的到来,信息呈现爆发式增长趋势,越来越多的数据呈现出结构化强、数据间关系复杂等新特点,这给数据挖掘领域带来了新的挑战。如今,数据挖掘已经应用于生物信息学、社交网络分析和链接预测等诸多领域,大量的数据以图的形式保存,这种数据结构类型可以清晰描述事物以及事物之间的相互关系,例如在社交网络分析领域,可以用图来描述人们的社交关系行为,图中的节点表示人物实体,图中的边表示人物之间的社会联系;在生物信息学领域,可以用蛋白质相互作用图表示ppi网络,蛋白质作为图中的节点,而图中的边则代表两个蛋白质之间的相互作用。
图的相似性分析是数据挖掘领域的一个重要内容,它是许多分类思想、搜索算法以及匹配策略的基础依据,在图数据功能预测方面具有很好的应用前景,例如可以通过对未知蛋白质网络与已知蛋白质网络的相似性分析预测未知蛋白质网络的功能。该方法的难点是定量描述图的相似性以及分析算法的通用性两个方面。在图的相似性分析计算中,最核心的思想是把图的相似性映射到图中属性相同节点间的匹配程度上,匹配程度与属性数据处理分别体现了定量描述与通用性这两个难点。
weisfeiler-lehman标签策略是目前处理属性数据的一种常用方法,该方法的核心思想是图中的一个节点属性信息通过不断地从邻居节点获取其属性信息,用以扩大信息的表述范围,同时融入图的结构关系属性,从而不断增强信息内容质量。虽然这种方法能够很好地对节点属性信息进行增强表述,但是它只是对节点属性的一个加强分类,并没有在属性相似度上对这一增强具体表现。另外,节点经过多次获取的邻居属性信息,可以代表与其相距多跳的邻居信息,节点相距跳数不同,那么节点所包含的信息范围也就不同。
jaccard相似性是分析图匹配程度的常用计算方法,该方法的核心思想是把图的相似性映射到节点的属性信息交集元素个数与节点的属性信息并集元素个数的占比上,以这种0到1之间的比例值来定量描述图节点的相似性(proteincomplexsimilaritybasedonweisfeiler-lehmanlabelin,biancak.stocker,tillschafer,etal)。虽然这种方法可以对连通图的相似性进行很好的定量描述,但是对于非连通图而言,该方法并不适用,例如,一个连通图包含六个节点组成的环,另一个非连通图包含两个由三个节点组成的环,以度信息为节点属性,它们jaccard相似性却为1。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术不足,提供一种面向非连通图的top-k相似匹配方法,准确高效地对非连通图相似性进行定量描述。
为解决上述技术问题,本发明所采用的技术方案是:一种一种面向非连通图的top-k相似匹配方法,包括以下步骤:
1)给定目标图gp和待匹配的图集合
2)计算目标图gp与图集合中待匹配图gi连通子图间的相似度分值,加权计算gp与gi的相似度分值sim(gp,gi);
3)根据相似度分值降序排序,从图集合
步骤1)的具体实现过程包括:
1)依次选取目标图gp和
2)根据节点度信息,为每个连通子图集中节点赋予初始属性标签。
相似度分值sim(gp,gi)的具体计算过程包括:
1)给定分值向量维数l,迭代计算目标图gp的每个连通子图与待匹配图集合
当l>1,或者l=1时,若当前迭代轮数h=1,则依次对具有初始属性标签的两个连通子图集{gp1,gp2,...,gpm}和{gi1,gi2,...,gis}中的每一对连通子图gpx和giy执行基于属性标签的相似度分值计算:
当s(gpx,giy)=0时或当h>l时,结束迭代过程;
2)计算目标图gp的每个连通子图与待匹配图集合
3)选取图gp的各连通子图与图gi的各连通子图间的最佳分值匹配方案,即通过步骤2)中计算得到的目标图gp的每个连通子图与待匹配图集合
4)通过加权策略加权计算图gp与图gi的相似度分值sim(gp,gi),即通过加权策略计算求得的count条边权重的加权分值。
结束迭代包括以下3种情况:
当s(gpx,giy)=0且h<l时,则提前结束迭代,第h到l轮迭代分值直接为零;当s(gpx,giy)=0且h=l时,则l轮迭代结束,第1到l-1轮具有非零相似性分值,而第l轮相似性分值为零;
当s(gpx,giy)≠0且h>l时,则l轮迭代结束,第1到第l轮均具有非零相似性分值。
分值系数向量β=[12,22,...,l2]的选取方法为:在迭代计算过程中,节点自身标签合并邻居节点属性标签后,被压缩替换成一个新的属性值,当第一轮迭代结束,该属性值代表以此节点为根节点的一跳子树的结构属性;当第二轮迭代结束,每个节点又获得邻居节点具有一跳子树结构的属性标签,此时,该节点具有代表二跳邻居节点子树的结构属性,依此类推,经过m轮迭代的节点属性标签最大可表示m跳子树结构属性。将此属性映射到圆面积计算,半径以节点标签可代表的最大节点子树跳数表示,得出节点最大表示范围πm2,以此反映迭代对节点分值计算权重比例为m2。
所述加权策略具体过程包括:假设选取了边edge[z],z∈{1,2,...,count},gpx与giy为边edge[z]连接的两个连通子图,则该边的加权比例为:
步骤3)中,将求得的所有sim(gp,gi)值按降序排列,选取sim(gp,gi)中的top-k个值,则图集合
与现有技术相比,本发明所具有的有益效果为:本发明首次提出一种面向非连通图的top-k相似匹配方法,用以更好地衡量涉及图结构之间的相似性,解决非连通图在涉及图结构相似度计算方面的问题,完成给定目标图与多个待匹配图间的top-k相似匹配的任务,提高了图匹配方法的通用性。
附图说明
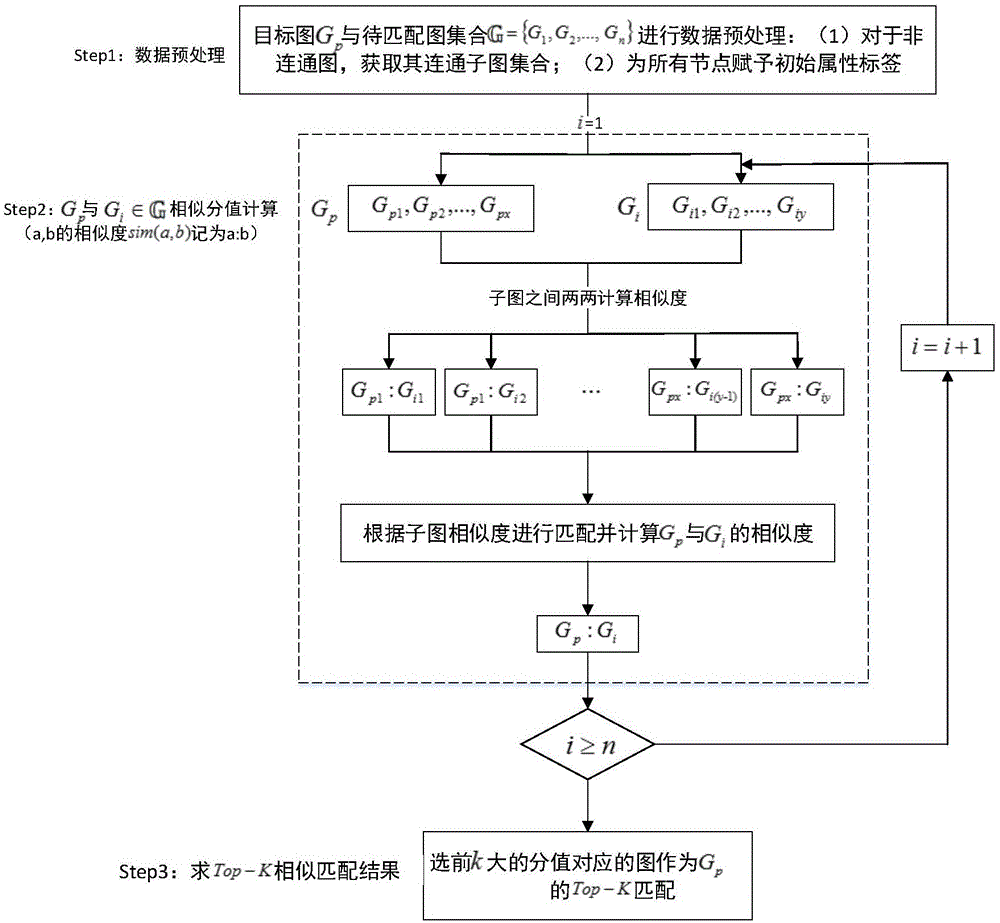
图1是面向非连通图的top-k相似匹配方法的流程图;
图2是面向非连通图的top-k相似匹配方法步骤1详图;
图3是面向非连通图的top-k相似匹配方法步骤2-(i)详图;
图4是面向非连通图的top-k相似匹配方法步骤2-(ii)详图;
图5是面向非连通图的top-k相似匹配方法步骤2-(iii)详图;
图6是面向非连通图的top-k相似匹配方法步骤2-(iv)详图。
具体实施方式
下面结合流程图及实施案例对本发明所述的面向非连通图的top-k相似匹配方法作进一步的详细描述。
本实施案例对带有度属性标签的目标图gp和待匹配的图集合
本方法包含如下步骤:
步骤1:如图2所示,给定目标图gp和待匹配的图集合
(i)利用深度优先算法获取gp和g1各自的连通子图集{gp1,gp2,gp3}和{g11,g12,g13}。
(ii)根据节点度信息,为每个连通子图{gp1,gp2,gp3,g11,g12,g13}中节点赋予初始属性标签。
步骤2:通过迭代计算目标图gp与图集合中待匹配图gi(i∈{1,2,3})连通子图间的相似度分值,加权计算gp与gi的相似度分值sim(gp,gi)。以gp和g1为例:
(i)如图3所示,给定分值向量维数4,迭代计算目标图gp的每个连通子图与待匹配图g1的每个连通子图间的4个相似度分值。并记当前迭代轮数为h。
若当前迭代轮数h=1时,依次对具有初始属性标签的两个连通子图集{gp1,gp2,gp3}和{g11,g12,g13}中的每一对连通子图gpx(x∈{1,2,3})和g1y(y∈{1,2,3})执行基于属性标签的相似度分值计算:
其中,d(gpx,g1y)为两连通子图相同标签点对个数,且每个点只允许有另一个点与其配对;|gpx|和|g1y|为两个连通子图各自的节点个数。
当1<h≤l时,对节点标签进行标签合并,压缩替换,获得节点新标签:对gpx和g1y两个连通子图中的每一个节点,将其自身标签和其邻居节点的标签进行合并组成一个新的属性值集合,并将这个集合压缩替换成一个新的整数,作为节点新的属性标签。之后仍然按照公式(1)计算相似度分值。
当s(gpx,g1y)=0时或当h>4时,结束迭代过程。结束迭代存在以下3种情况:
1)当s(gpx,g1y)=0且h<4时,则提前结束迭代,h到4轮迭代分值直接为零。
2)当s(gpx,g1y)=0且h=4时,则4轮迭代结束,第1到3轮具备非零相似性分值,而第4轮相似性分值为零。
3)当s(gpx,g1y)≠0且h>4时,则4轮迭代结束,第1到4轮均具备非零相似性分值。
(ii)如图4所示,计算目标图gp的每个连通子图与g1的每个连通子图间的相似度,即由本步骤(i)中计算得到gp的一个连通子图gpx(x∈{1,2,3})与g1的一个连通子图g1y(y∈{1,2,3})的4个相似度分值,构造gpx和g1y间的l维分值向量α。取分值系数向量值为β=[12,22,32,42],通过4维分值向量α与分值系数向量β求内积,得到连通子图gpx和连通子图g1y间的相似度。
将图gp的每一个连通子图gpx逐一与图g1的每一个连通子图g1y进行上述操作,即可求得图gp的3个连通子图{gp1,gp2,gp3}和图g1的3个连通子图{g11,g12,g13}的3×3个相似度。记作:
对于上述
(iii)如图5所示,选取图gp的各连通子图与图g1的各连通子图间的最佳分值匹配方案,即通过本步骤(ii),可以构造图gp的3个连通子图到图g1的3个连通子图的带权二部图。记count=min{3,3}=3,选取图gp的各连通子图与图g1的各连通子图间3条边,使得选取的3条边edge[1]、edge[2]、edge[3](边两端的顶点有且仅出现一次)对应的权值wedge[1]、wedge[2]、wedge[3]能在匹配不冲突的情况下,使得权值总和最大。由此,实现图gp的3个连通子图与图g1的3个连通子图的最佳相似匹配。
(iv)如图6所示,通过加权策略加权计算图gp与图g1的相似度分值sim(gp,g1),即通过加权策略计算求得的3条边权重的加权分值。加权策略如下:
假设选取了边edge[z](z∈{1,2,3}),gpx与g1y为边edge[z]连接的两个连通子图,则该边的加权比例为:
其中,|gp|表示图gp的总节点数,|g1|表示图g1的总节点数。|gpx|表示连通子图gpx的节点个数,|g1y|表示连通子图g1y的节点个数。
将3条边权重的加权分值之和作为gp与g1的相似度分值sim(gp,g1),则
步骤3:从待匹配的图集合{g1,g2,g3}中选取与目标图gp的top-1(k=1)的图,即选取相似度最高的图。
(i)gp再分别与g2,g3进行相同的操作,得到图gp与图g2的相似度分值sim(gp,g2),图gp与图g3的相似度分值sim(gp,g3)。
(ii)将相似度分值sim(gp,gi)降序排序,选取sim(gp,gi)(i∈{1,2,3})中的top-1值,即sim(gp,gi)的最大值。取得该最大值对应的图gi,即为与目标gp最为相似的图。
如上所述为本发明对面向非连通图的top-k相似匹配方法在以度信息为属性标签,从待匹配的图集合{g1,g2,...,gn}中选取与目标图gp的top-k个图的具体应用。
- 还没有人留言评论。精彩留言会获得点赞!