一种基于索引的快速人脸检索系统应用的制作方法
本发明涉及一种基于索引的快速人脸检索系统应用,属于海量人脸技术领域。
背景技术:
随着社交网站的流行,互联网中图像、视频等非结构化数据每天都在以惊人的速度增长。针对包含丰富视觉信息的海量图片,如何在这些浩瀚的图像库中方便、快速、准确地查询并检索到用户所需的或感兴趣的图像,成为信息检索领域研究的热点。现有的人脸图像检索技术,主要有基于文本的图像检索技术和基于内容的图像检索技术两种。
基于文本的图像检索技术,采用人工标注的方式对人脸图像特征进行表征。在大规模的人脸图像检索过程中,首先提取出图像描述的关键字信息,之后利用倒排索引技术对关键字信息建立索引。用户在进行人脸图片检索时,需要对待查图片的关键信息进行描述,然后将提取的描述信息与倒排索引表中的关键字信息进行匹配,以此查询出近似的图片数据。
基于内容的图像检索技术,利用计算机视觉技术对人脸图像特征进行分析和提取,并将提取的特征数据进行入库。当用户进行查询操作时,采用相同的特征提取方法对图像提取特征,然后利用计算特征差异,最后根据特征差异的大小进行排序,并根据预设的阈值输出满足要求的图片。
基于文本的图像检索技术在标注时需要人手工处理,使得这种方式只能适用于小规模的图像数据检索,而对于海量的图像数据这种方式显得捉襟见肘。而且在进行图像标注时具有很强的主观性,受到标注者的认知水平、言语使用以及主观判断等的影响使得标注的准确性和完整性很难得到保证。
基于内容的图像检索技术对于提取特征的好坏有着较高的要求,如果特征无法很好地表征或有效的区别于其他图像,则很有可能导致检索失败。而且现阶段提取的图像特征多为高维特征,在进行特征比对时需要占用大量的时间和资源,性能较低。
技术实现要素:
本发明所要解决的技术问题是提供一种基于索引的快速人脸检索系统应用,通过对高维特征的量化和编码,减少高维特征的存储空间;同时构建特征索引加速特征的比对和检索过程,从而满足了数据量大、特征维度高、检索时间快的需求。
本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种基于索引的快速人脸检索系统应用,包括人脸图片特征存储方法,人脸图片存储方法包括如下步骤:
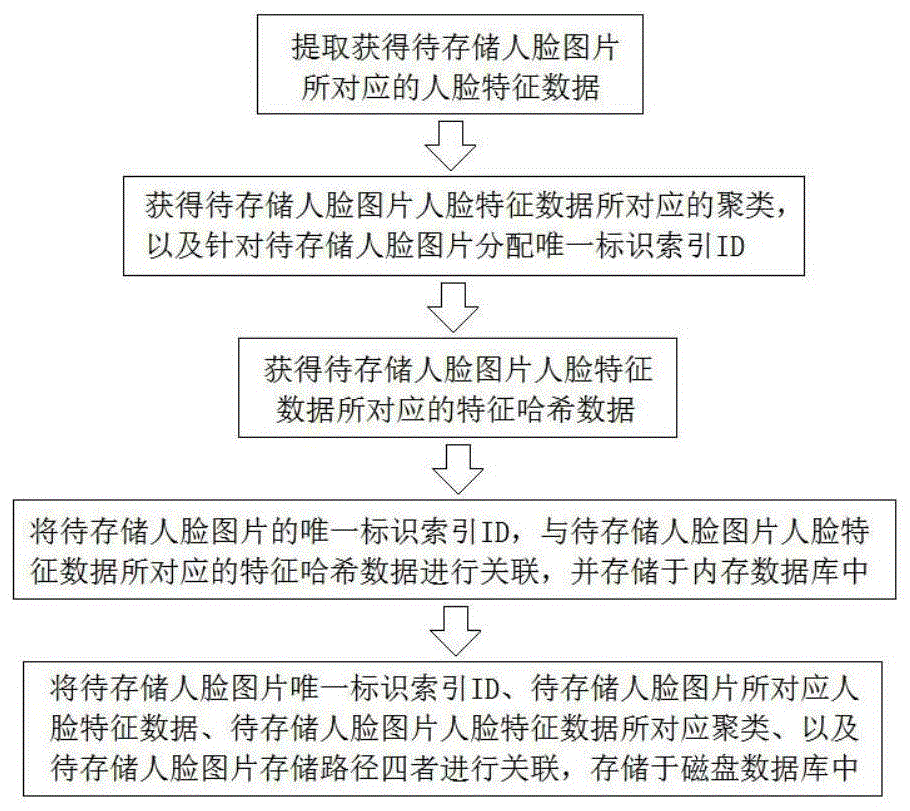
步骤a1.提取获得待存储人脸图片所对应的人脸特征数据,然后进入步骤a2;
步骤a2.基于预设各个聚类中心,针对待存储人脸图片人脸特征数据进行层次聚类,获得待存储人脸图片人脸特征数据所对应的聚类,以及针对待存储人脸图片分配唯一标识索引id,然后进入步骤a3;
步骤a3.针对待存储人脸图片所对应的人脸特征数据进行哈希编码转化,获得待存储人脸图片人脸特征数据所对应的特征哈希数据,然后进入步骤a4;
步骤a4.将待存储人脸图片的唯一标识索引id,与待存储人脸图片人脸特征数据所对应的特征哈希数据进行关联,并存储于内存数据库中、待存储人脸图片人脸特征数据所对应聚类的存储区域,然后进入步骤a5;
步骤a5.将待存储人脸图片存入磁盘数据库中,并将待存储人脸图片唯一标识索引id、待存储人脸图片所对应人脸特征数据、待存储人脸图片人脸特征数据所对应聚类、以及待存储人脸图片存储路径四者进行关联,存储于磁盘数据库中。
作为本发明的一种优选技术方案,还包括人脸图片检索方法,包括如下步骤:
步骤b1.提取获得待检索人脸图片所对应的人脸特征数据,然后进入步骤b2;
步骤b2.基于预设各个聚类中心,针对待检索人脸图片人脸特征数据进行层次聚类,获得待检索人脸图片人脸特征数据所对应的聚类,以及与该聚类满足预设相似规则的其它各个聚类,作为各个待处理聚类,然后进入步骤b3;
步骤b3.扫描内存数据库,获取各个待处理聚类所对应存储区域中的所有唯一标识索引id、以及相对应的特征哈希数据,作为各组待匹配数据,然后进入步骤b4;
步骤b4.针对待检索人脸图片所对应的人脸特征数据进行哈希编码转化,获得待检索人脸图片人脸特征数据所对应的特征哈希数据,作为待匹配特征哈希数据,然后进入步骤b5;
步骤b5.计算各组待匹配数据中特征哈希数据分别与待匹配特征哈希数据之间的误差,获得误差低于预设误差阈值的各组待匹配数据,并提取该各组待匹配数据中的唯一标识索引id,然后进入步骤b6;
步骤b6.根据步骤b5所获各个唯一标识索引id,在磁盘数据库中,提取该各个唯一标识索引id分别所对应的人脸特征数据、以及对应人脸图片存储路径,作为各组相似备选数据,然后进入步骤b7;
步骤b7.根据各组相似备选数据中人脸图片存储路径,由磁盘数据库中提取各张人脸图片,作为待检索人脸图片的检索结果。
作为本发明的一种优选技术方案:还包括步骤b6-7如下,执行完步骤b6之后,进入步骤b6-7,执行完步骤b6-7之后,进入步骤b7;
步骤b6-7.计算各组相似备选数据中人脸特征数据分别与待检索人脸图片人脸特征数据之间的欧式距离,删除欧氏距离高于预设距离阈值的各组相似备选数据,针对剩余各组相似备选数据,进入步骤b7。
作为本发明的一种优选技术方案:所述步骤a1中的人脸特征数据提取、以及所述步骤b1中的人脸特征数据提取,均按如下操作实现;
首先针对人脸图片,通过至少两种卷积神经网络,按卷积神经网络输出精度由低到高的顺序,依次对人脸图片中人脸的位置进行定位;然后,采用残差网络从获取的人脸中提取出特征数据。
作为本发明的一种优选技术方案:所述步骤b5中,通过计算各组待匹配数据中特征哈希数据分别与待匹配特征哈希数据之间的汉明码距离,作为各组待匹配数据中特征哈希数据分别与待匹配特征哈希数据之间的误差。
作为本发明的一种优选技术方案:所述步骤a2中获得待存储人脸图片人脸特征数据所对应的聚类,以及所述步骤b2中获得待检索人脸图片人脸特征数据所对应的聚类,均按如下操作实现:
首先基于预设各个聚类中心,针对人脸图片的人脸特征数据进行层次聚类,获得该人脸图片的人脸特征数据所对应的聚类;
然后,基于该所对应聚类中预设的各个子聚类中心,再对人脸图片的人脸特征数据进行层次聚类,进一步获得该人脸图片的人脸特征数据所对应的子聚类;
通过上述二次聚类,将该人脸图片的人脸特征数据所对应的聚类、及其子聚类,作为该人脸图片的人脸特征数据所对应的聚类。
作为本发明的一种优选技术方案:所述步骤b2中,在获得待检索人脸图片人脸特征数据所对应的聚类后,计算该聚类中心分别与其余各个聚类中心之间的欧氏距离,并选择欧式距离低于预设距离阈值的各个聚类,结合待检索人脸图片人脸特征数据所对应的聚类,作为各个待处理聚类。
本发明所述一种基于索引的快速人脸检索系统应用采用以上技术方案与现有技术相比,具有以下技术效果:
本发明所设计一种基于索引的快速人脸检索系统应用,具有大数据承载能力,能够支持百亿级的数据规模;而且特征维度高,能够更好的进行语义表征;不仅如此,整个设计在实际应用中,响应时间快,具备更快的检索速率。
附图说明
图1是本发明所设计人脸图片存储方法的流程示意图;
图2是本发明所设计人脸图片检索方法的流程示意图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
本发明设计了一种基于索引的快速人脸检索系统应用,实际应用当中,包括人脸图片特征存储方法和人脸图片检索方法,其中,如图1所示,人脸图片存储方法包括如下步骤a1至步骤a5。
步骤a1.提取获得待存储人脸图片所对应的人脸特征数据,然后进入步骤a2。
实际应用中,上述步骤a1中的人脸特征数据提取,按如下操作实现。
首先针对人脸图片,通过至少两种卷积神经网络,按卷积神经网络输出精度由低到高的顺序,依次对人脸图片中人脸的位置进行定位;然后,采用残差网络从获取的人脸中提取出特征数据。
步骤a2.基于预设各个聚类中心,针对待存储人脸图片人脸特征数据进行层次聚类,获得待存储人脸图片人脸特征数据所对应的聚类,以及针对待存储人脸图片分配唯一标识索引id,然后进入步骤a3。
实际应用中,上述步骤a2,按如下操作,获得待存储人脸图片人脸特征数据所对应的聚类。
首先基于预设各个聚类中心,针对人脸图片的人脸特征数据进行层次聚类,获得该人脸图片的人脸特征数据所对应的聚类。
然后,基于该所对应聚类中预设的各个子聚类中心,再对人脸图片的人脸特征数据进行层次聚类,进一步获得该人脸图片的人脸特征数据所对应的子聚类。
通过上述二次聚类,将该人脸图片的人脸特征数据所对应的聚类、及其子聚类,作为该人脸图片的人脸特征数据所对应的聚类。
如此,依次通过两次聚类操作,从而能够有效提高检索效率。
由于原始的人脸的特征为高维的浮点型数据,计算过程复杂且存储量大,并不便于存储到内存之中。因此,采用哈希编码的方式对原始特征进行编码,将其转化为便于处理的二进制编码形式,能够减少了数据量、提高了内存使用效率,因此继续执行如下步骤a3。
步骤a3.针对待存储人脸图片所对应的人脸特征数据进行哈希编码转化,获得待存储人脸图片人脸特征数据所对应的特征哈希数据,然后进入步骤a4。
步骤a4.将待存储人脸图片的唯一标识索引id,与待存储人脸图片人脸特征数据所对应的特征哈希数据进行关联,并存储于内存数据库中、待存储人脸图片人脸特征数据所对应聚类的存储区域,然后进入步骤a5。
步骤a5.将待存储人脸图片存入磁盘数据库中,并将待存储人脸图片唯一标识索引id、待存储人脸图片所对应人脸特征数据、待存储人脸图片人脸特征数据所对应聚类、以及待存储人脸图片存储路径四者进行关联,存储于磁盘数据库中。
实际应用当中,人脸图片检索方法,如图2所示,包括如下步骤b1至步骤b7。
步骤b1.提取获得待检索人脸图片所对应的人脸特征数据,然后进入步骤b2。
实际应用中,上述步骤b1中的人脸特征数据提取,按如下操作实现。
首先针对人脸图片,通过至少两种卷积神经网络,按卷积神经网络输出精度由低到高的顺序,依次对人脸图片中人脸的位置进行定位;然后,采用残差网络从获取的人脸中提取出特征数据。
步骤b2.基于预设各个聚类中心,针对待检索人脸图片人脸特征数据进行层次聚类,获得待检索人脸图片人脸特征数据所对应的聚类,以及与该聚类满足预设相似规则的其它各个聚类,作为各个待处理聚类,然后进入步骤b3。
实际应用中,上述步骤b2,按如下操作,获得待检索人脸图片人脸特征数据所对应的聚类。
首先基于预设各个聚类中心,针对人脸图片的人脸特征数据进行层次聚类,获得该人脸图片的人脸特征数据所对应的聚类。
然后,基于该所对应聚类中预设的各个子聚类中心,再对人脸图片的人脸特征数据进行层次聚类,进一步获得该人脸图片的人脸特征数据所对应的子聚类。
通过上述二次聚类,将该人脸图片的人脸特征数据所对应的聚类、及其子聚类,作为该人脸图片的人脸特征数据所对应的聚类。
这里同样,依次通过两次聚类操作,从而能够有效提高检索效率。
步骤b2在实际应用中,当获得待检索人脸图片人脸特征数据所对应的聚类后,计算该聚类中心分别与其余各个聚类中心之间的欧氏距离,并选择欧式距离低于预设距离阈值的各个聚类,结合待检索人脸图片人脸特征数据所对应的聚类,作为各个待处理聚类。
步骤b3.扫描内存数据库,获取各个待处理聚类所对应存储区域中的所有唯一标识索引id、以及相对应的特征哈希数据,作为各组待匹配数据,然后进入步骤b4。
步骤b4.针对待检索人脸图片所对应的人脸特征数据进行哈希编码转化,获得待检索人脸图片人脸特征数据所对应的特征哈希数据,作为待匹配特征哈希数据,然后进入步骤b5。
步骤b5.计算各组待匹配数据中特征哈希数据分别与待匹配特征哈希数据之间的汉明码距离,作为各组待匹配数据中特征哈希数据分别与待匹配特征哈希数据之间的误差,获得误差低于预设误差阈值的各组待匹配数据,并提取该各组待匹配数据中的唯一标识索引id,然后进入步骤b6。
步骤b6.根据步骤b5所获各个唯一标识索引id,在磁盘数据库中,提取该各个唯一标识索引id分别所对应的人脸特征数据、以及对应人脸图片存储路径,作为各组相似备选数据,然后进入步骤b6-7。
步骤b6-7.计算各组相似备选数据中人脸特征数据分别与待检索人脸图片人脸特征数据之间的欧式距离,删除欧氏距离高于预设距离阈值的各组相似备选数据,针对剩余各组相似备选数据,进入步骤b7。
步骤b7.根据各组相似备选数据中人脸图片存储路径,由磁盘数据库中提取各张人脸图片,作为待检索人脸图片的检索结果。
上述技术方案所设计一种基于索引的快速人脸检索系统应用,具有大数据承载能力,能够支持百亿级的数据规模;而且特征维度高,能够更好的进行语义表征;不仅如此,整个设计在实际应用中,响应时间快,具备更快的检索速率。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!