一种基于SVM的音频分类方法及系统与流程
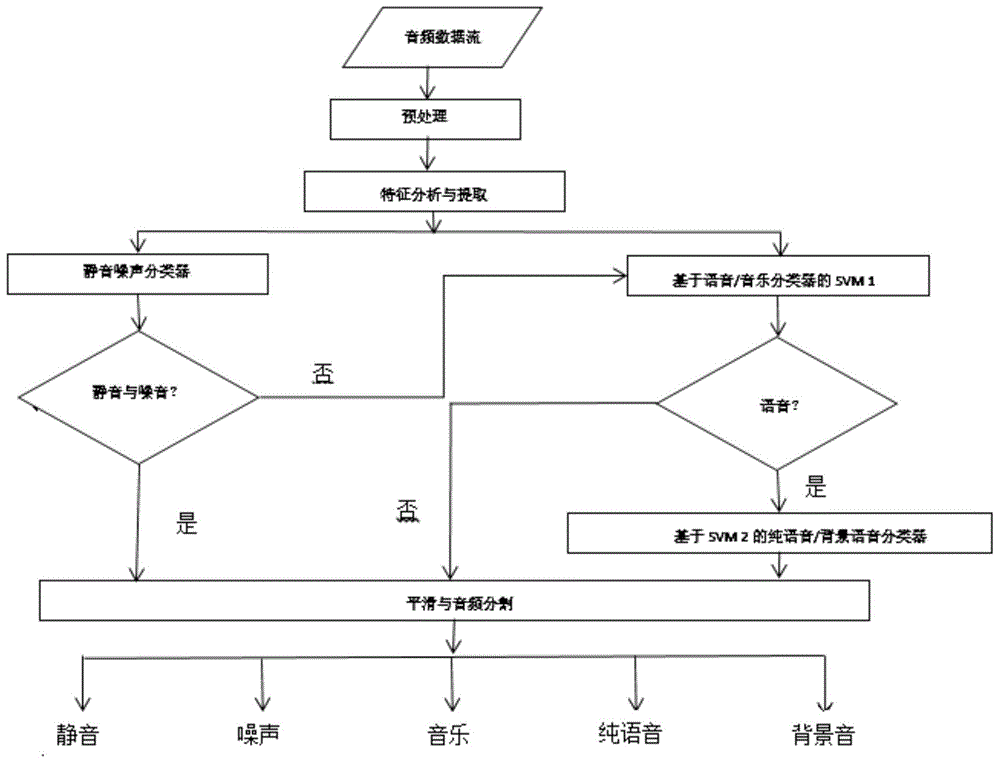
本发明属于音频数据分析
技术领域:
,尤其涉及一种基于svm的音频分类方法及系统。
背景技术:
:目前,业内常用的现有技术是这样的:今天的人类社会已经进入了数字化时代。随着计算机技术、网络技术和通信技术的不断发展,图像、视频、音频等多媒体信息已逐渐成为信息处理领域信息媒体的主要形式。其中,音频占有非常重要的位置。音频是多媒体的重要组成部分。与图像和视频相比,音频不仅具有独特的特征,而且音频数据量小,处理速度快,引起了人们的广泛关注。音频表达的形式多种多样,满足了人们在生活、工作、娱乐等方面的需求,互联网上的音频数据资源继续以前所未有的速度增长。从互联网上的大量音频数据中快速有效地获取和处理所需要的有效信息,是一种很好的分析、分类和检索数据的方法。如何有效地组织和管理这些音频资源,使人们更容易找到所需的音频片段已成为迫切需要。现在,关于音频分类问题的研究不仅仅是对音乐和语言的分类。分类的类别将随着人们的需求而改变,促进人们的工作和生活。一般来说,音频分类最基本的对象是语音、音乐和静音;进一步分为五类:纯音、音乐、环境声音、背景音和哑音。音频分类是音频信息深层处理的基础,是音频结构的核心技术,是提取音频结构和内容语义的重要手段。它根据所感知的特点或表达的内容,将音频数据分为不同的类别,并在语音检索、基于内容的音频分割和音频监督中起着重要的作用。一方面,它可以作为连续语音识别的初始化过程,禁止音频流中的非语音流进入语音识别器,提高语音识别的准确性,缩短识别时间。另一方面,这也是音乐类型分类的第一步。对于一个给定的音频,我们可以通过音频分类对它进行分类和分割。在判断之后,对不同类型的音频数据进行不同的处理,以获得判断结果。在本例中,对不同类型的音频数据采用不同的处理方法,不仅可以缩短处理过程的时间和空间消耗,而且可以同时提高处理精度。目前,该领域的研究主要集中在三个方面:音频特征分析和提取、分类器设计和实现,以及音频分割方法。音频的分类可以说是一种模式识别的过程。它的研究重点通常包括两个基本方面:音频特征分析和提取,分类器的设计和实现。音频分类的实质是模式识别过程,主要实现了以下几点:(1)预处理。在处理音频文件之前,我们需要预先处理它,即把音频流划分为更小的单元。通过对这些较短的音频单元进行分类来对音频文件进行分类。音频信号的预处理包括预重点、框架和窗口。(2)提取音频特性进行分类。特征的选择和提取是模式识别系统中最重要的部分,当然也是音频分类中最重要的部分。(3)功能筛查。多类音频分类,多级二级分类,为了更好地区分每一级的两种音频数据,将使用特征选择方法来选择最适合每个层次分类的特征集。(四)分类器的选择。使用机器学习自动对音频信号进行分类不仅减少了人力,而且还减少了时间,提高了效率。常用的音频分类器的实现主要分为两类:基于阈值和统计的模型。在音频分类领域,分类器实现方法的早期实现是基于阈值的。这种分类方法需要大量的训练数据,并且由于在不同的应用程序中所选择的阈值通常是不同的,所以它并不是通用的,而阈值判断方法只能在音频粗级上实现分类(如分类音乐、静音、声音等),不能实现对音频数据的细分类(如对掌声的识别,喊叫,爆炸声等)。因此,为了克服这些缺点,人们提出了基于统计模型的音频分类。这种分类方法不存在阈值,是一种基于统计理论的数据训练得到的分类模型。它不仅能识别粗糙级别的音频数据,还能识别精细的音频数据。在统计模型中,受监督的模型与无监督模型之间也有区别。在早期,人们经常使用监督的数据分析和分类方法,比如svm(支持向量机)。svm是一种基于统计学习理论的新机器学习方法,它适用于处理分类,并在更大程度上反映不同类别之间的差异。svm方法在许多应用程序中充分展示了它的有效性。然而,svm方法的有效性对训练数据的质量和数量有很强的依赖性。一个好的分类器确定了较高的分类精度,根据分类音频数据的分类目标对目标进行了调整,从而提高了分类精度。该统计模型具有较好的模拟声音特征空间分布的能力,和良好的鲁棒性。因此,近年来,支持向量机(svm)在音频分类中得到了广泛的应用。音频分割,也被称为跳跃点检测,顾名思义,是指通过某些手段在被测试的音频序列中找到跳跃点。那么什么样的点叫做跳跃点呢?一般来说,当人类的耳朵接收到连续的音频信号时,不同的信号会产生不同的感觉。从感知的角度来看,当人类的耳朵感觉到信号的变化时,这个点被称为跳跃点,也称为分点。从信号的角度来看,这种变化可以被称为听觉特征的变化,即相应的信号的某些特征必须随着这个变化而改变。分割出不同长度的音频片段的过程称为音频分割。…….解决上述技术问题的难度和意义:(1)能有效地组织和管理这些音频资源,使人们更容易找到所需的音频片段;(2)将音频数据分为不同的类别,并在语音检索、基于内容的音频分割和音频监督中起着重要的作用,它可以作为连续语音识别的初始化过程,禁止音频流中的非语音流进入语音识别器,提高语音识别的准确性,缩短识别时间;(3)对不同类型的音频数据采用不同的处理方法,不仅可以缩短处理过程的时间和空间消耗,而且可以同时提高处理精度。(4)基于统计理论的数据训练得到的分类模型,它不仅能识别粗糙级别的音频数据,还能识别精细的音频数据。(5)svm方法的有效性对训练数据的质量和数量有很强的依赖性。根据分类音频数据的分类目标对目标进行了调整,从而提高了分类精度。该统计模型具有较好的模拟声音特征空间分布的能力,和良好的鲁棒性。技术实现要素:针对现有技术存在的问题,本发明提供了一种基于svm的音频分类方法及系统。本发明的音频分类和分割技术可以很好地解决了现有技术问题,为音频的构建、深度分析和对音频信息的利用提供了坚实的基础。本发明是这样实现的,一种基于svm的音频分类方法,所述基于svm的音频分类方法包括:在音频提取这些特性的方法中,分别使用时域特性和频域特性来提取音频的特性;在音频分类中,采用基于支持向量机svm的分类方法进行分类;在音频分割方法中,采用贝叶斯信息准则bic的音频分割方法进行分割点确认;其中,音频分割从音频分类的音频流中提取不同音频类别,音频流按时间轴的类别进行划分。进一步,音频提取前,需进行:音频信号预处理:首先,原始音频信号被预处理,对音频信号进行分割,并对每个音频段进行窗口化和帧化;其次,提取音频帧和音频段,并对提取的特征合并。进一步,在音频提取这些特性的方法中,分别使用时域特性和频域特性来提取音频的特性中,具体包括:1)音频时间域特性分析和提取:音频时域特性代表时域特性,通过在时域波形的帧中分析音频信号;具体有:过零率zcr:在音频信号的离散点上两个相邻采样点的信号值与所有采样数的比值;过零率显示信号过零的频率其中x(m)是经过处理的离散音频信号;短期平均能量:短期平均能量为音频特征参数,反映音频能量的变化,这直接关系到窗口长度n的选择;n的值若太长,整个能量的变化相对平稳而差异没有反映出来,但一个窗口太窄则没有光滑的能量函数;选择haiming窗以在两者之间保持良好的平衡;短期平均能量用下公式计算:当x(n)表示音频信号的第m个帧中的第n个信号值时,w(n)是窗函数。短时间的能量被设置为一个阈值,在阈值以下,判定为静音;2)音频域特性分析和提取:计算每个帧的特征值,然后计算出片级的特征值;3)基于音频片段的特征分析和提取:进行:静音比例在频域能量中设置一个阈值;子带能量比平均值由子带能量比参数计算得到音频段特征;带宽平均值为音频段中每个帧的平均带宽;进行高过零率计算;计算音频段中低频能量框架的比值;频谱转换,描述音频片段中每个相邻音频帧的光谱差异的平均参数;在音频段的基础音频速率标准方差,计算每个帧的音高频率,然后用这些音调频率参数计算它们的标准偏差;进行特征向量集的组成向量集划分,划分为24维的mfcc向量,以及由音频片段提取的11维特征向量。进一步,音频分类方法包括:1)安静和噪音使用基于规则的分类方法;2)每个音频类别的分类:基于svm的分类器用于对纯语音/背景声音和音乐/环境声音进行分类。进一步,音频分类方法包括:改进的δbic分割方法,对于每个检测到的bic窗口,如果检测到一个分裂点,将一个特定的长度滑到下一个窗口;如果分裂点未被检测到,窗的长度也增加,当窗口长度增加到一定程度上,分裂点还没有发现,那么窗口保持当前窗口长度和滑行向前直到找到分割点恢复初始窗口长度;检测到分割点时,窗口的长度直接向后移动。本发明的另一目的在于提供一种实现所述基于svm的音频分类方法的计算机程序。本发明的另一目的在于提供一种终端,所述终端至少搭载权利要求1~5任意一项所述基于svm的音频分类方法的处理器。本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的基于svm的音频分类方法。本发明的另一目的在于提供一种实现所述基于svm的音频分类方法的基于svm的音频分类控制系统。本发明的另一目的在于提供一种搭载所述基于svm的音频分类控制系统多媒体信息处理设备。综上所述,本发明的优点及积极效果为:本发明中,音频自动分类和分割是在音频中提取结构化信息和语义内容的重要手段,是理解、分析和检索音频内容的基础。从本质上说,音频数据的分类是一个模式识别问题,它包括两个基本方面:特征提取选择和分类。如何在音频信号中提取最能代表音频信号特征的信息,对于音频分类是至关重要的。音频特征提取可以基于音频帧的特征分析和提取方法,以及基于音频的特征分析和提取方法。在提取这些特性的方法中,分别使用时域特性和频域特性来提取音频的特性。在对现有算法进行充分研究和实验的基础上,实现了音频分类和分割的技术过程。这主要包括音频分类和音频分割的两个内容。在分类方法中采用了基于支持向量机(svm)的分类方法。支持向量机svm是近年来机器学习研究的主要成果。作为一种新的机器学习方法,svm可以解决小样本、非线性和高维数等实际问题,从而成为神经网络研究的一个新的研究热点。在分割方法中,采用贝叶斯信息准则(bic)的音频分割方法进行分割点确认。音频分割是从音频分类的音频流中提取不同音频类别的,也就是说,音频流按时间轴的类别划分。实验证明,基于svm的音频分类算法具有良好的分类效果,平滑的音频分割结果更加准确。本发明通过进行实验分析如下:1)安静和噪音使用基于规则的分类方法。实验设计如下:对所有样本进行静音和噪声域值的判定,对正确的分类编号进行记录,计算出错误分类的数量(非静音但被判定为静音的剪辑数量),并计算出分类精度。实验结果如下:表1噪声/静音分类结果正确分类数错误分类数分类准确率噪声54112785.87%静音7092393.28%对于其他类别,音频大小显然是不同的,因此识别精度很高。错误分类主要是由于在一个片段中,它包含了静音和其他音频类别,所以能量平均值可能相对较小。解决了降低能量阈值的方法。对噪音的识别精度为85.87%。分析的原因是,不同音频类别中出现的噪声源不一样,因此噪声的时频特性也有所不同。单一阈值用于判断缺乏普遍性。因此,在测试中噪声判断的准确性不高,假正率高。在能量谱上有微小变化的环境声音很容易被错误地判断为噪音。2)每个音频类别的分类基于svm的分类器用于对纯语音/背景声音和音乐/环境声音进行分类。每一种分类都要进行三次试验。表2纯语音/背景声音的声音分类结果表3音乐/环境声音分类结果从实验中可以看出,支持向量机分类器的分类精度非常高,纯语音和背景声音的平均分类精度为91.28%,音乐和环境声音的平均分类精度也为90.77%。从实验数据可以看出,所提出的支持向量机分类器对音频分类工作具有较好的分类效果和精确度。3)传统δbic分割方法和改进的δbic分割方法实验分别采用传统的分割方法和改进的分割方法。为了比较改进的分割方法与传统分割方法的精度,验证了传统分割方法的合理性,并验证了改进后的分割方法的有效性。采用传统的分割方法和改进的分割方法对分类结果进行了分割。表4分割测试结果分割方法分割结果正确数量/精度漏判误判传统分割方法165127/82.5%2738改进的分割方法148135/87.6%913传统的δbic分割方法等价于改进的δbic分割方法,并且检测到的分割结果的数量远远大于改进的方法。分析的原因是传统的方法只对分类结果进行了平滑处理,然后直接将同一类别的音频组合在一起,获得分割结果。不考虑相邻段之间的相互作用,忽略了分割的总体优化问题。这就相当于放松了音频镜头分割的限制,提高了准确率,将不可避免地导致错误分类的增加,从而导致更多的被检测到的音频镜头。改进的方法将分割问题转化为优化问题解决方案。它是一种动态的方法,充分考虑了分段之间的相互作用和分割的整体优化,从而大大降低了误报的数量,而且精度也得到了一定的提高。结果表明,优化方法的实际效率明显高于传统方法。附图说明图1是本发明实施例提供的基于svm的音频分类方法流程图。图2是本发明实施例提供的预加重滤波器原理图。图3是本发明实施例提供的mel比例滤波器组图。图4是本发明实施例提供的支持向量机示意图。图5是本发明实施例提供的奇点图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。在当前多媒体信息处理中,音频占据着非常重要的位置,但由于媒体源本身的特点和现有技术的约束,对音频信息的进一步分析和利用是有限的。如图1所示,本发明实施例提供的基于svm的音频分类方法,包括:在音频提取这些特性的方法中,分别使用时域特性和频域特性来提取音频的特性;在音频分类中,采用基于支持向量机svm的分类方法进行分类;在音频分割方法中,采用贝叶斯信息准则bic的音频分割方法进行分割点确认;其中,音频分割从音频分类的音频流中提取不同音频类别,音频流按时间轴的类别进行划分。下面结合具体分析对本发明的应用作进一步描述。1、音频信号预处理音频信号预处理分为两个步骤:首先,原始音频信号被预处理,主要目的是统一音频格式,进行预处理,对音频信号进行分割,并对每个音频段进行窗口化和帧化;其次,提取音频帧和音频段,并对提取的特征合并。其主要目的是获得最终所需的音频特征向量。预处理原始音频数据,包括预重点、分割和加窗。(1)预加重处理与人耳听觉机制相结合,人耳可以听到的音频频率范围是60hz~20khz。当进行音频信号处理时,音频信号被预强调,其目的是消除低频干扰,特别是50hz或60hz的功率频率干扰。预强调通常是使用预强调的数字滤波器将音频信号进行数字化,这通常采用一阶高通数字滤波器:h(z)=1-μz-1(1)就时间域而言,若通过的信号为y(n),那y(n)可以表示为:y(n)=x(n)-μ*x(n-1)(2)其中x(n)表示原始信号序列,y(n)表示预强调序列。一阶高通数字滤波器,如图2预加重滤波器原理图所示。通过预强调处理,可以降低尖锐噪声的影响,提高信号的高频部分,使信号的频谱平稳,并使预强调系数通常在0.97或0.98左右。滤波器预先强调的信号需要被规范化。(2)加窗框架在进行了预强调的数字滤波处理后,下一步执行加窗和帧处理。在短时间内,音频信号变化非常缓慢,因此在这个缓慢的过渡过程中,提取的音频特性保持稳定。因此,在处理音频信号时,首先将离散的音频信号划分为一个长度单位进行处理,也就是说,离散的音频采样点被划分为音频帧。该方法是一种信号“短时”处理方法。一般来说,一个“短时间”的音频帧的持续时间大约是几到几十毫秒。根据分音单元的长度,可以将音频单元分为:音频帧、音频剪辑、音频镜头、音频高级语义单元。虽然帧可以采用连续分割的方法,但一般采用图中所示的重叠段的方法,以使帧与帧之间平滑过渡,并保持其连续性。前一帧和下一帧的重叠部分称为帧移位,帧移位通常被认为是帧长度的一半。框架是通过加权一个有限长度的窗口来实现的,这个窗口可以用y(n)乘以一个特定的窗函数w(n)来形成一个窗口音频信号yw(n)=w(n)*y(n)。时域中的信号相乘,相当于频域的卷积计算。因此,窗口的计算也可以如下表示:其中y和w分别表示频谱。可以看出,窗函数w(n)不仅影响时域原始信号的波形,而且影响其频域的波形。两个最常用的窗函数是矩形窗和汉明窗。矩形窗:汉明窗:窗函数w(n)的形状和长度的选择对短期分析参数的特征有很大的影响。因此,应选择适当的窗口,使短期参数更好地反映语音信号的特征变化。矩形窗有较好的光谱平滑性,但高频分量和波形细节丢失,矩形窗将会导致泄漏。汉明窗能有效地克服泄漏(gibbs)现象,具有最广泛的应用范围。如果窗口长度为n,就相当于一个非常窄的低通滤波器。当音频信号通过时,反射波形细节的高频部分受到阻碍,其短时间能量随时间变化不大。这并不能真正反映语音信号的振幅变化。相反地,如果n太小,滤波器的通带就会变宽,短期能量随时间而急剧变化,而无法获得平滑的能量函数。因此,应该适当地选择窗口的长度,通常是15-30毫秒。在上述处理后,音频信号被划分为帧间加窗函数的短时间信号,然后每一个短期音频帧被视为一个平滑的随机信号,数字信号技术用于提取音频特征参数。2音频特性分析提取音频信号包含大量的信息,并且有许多干扰信号和冗余信息。如何提取音频信号中最具代表性的信息是音频分类的关键。音频特性是音频分类的基础,而提取的音频特性则是为了尽可能地反映音频的显著特性。与此同时,对环境的影响应反映出良好的鲁棒性,同时消除引起识别歧义[3]的信号特征。该特性提取的参数作为向量形式的分类处理方法的输入。因此,应该考虑向量参数之间的独立性,并在保证结果准确性的同时,尽量减少计算复杂度。它具有尽可能多地包含信息的特征,但是数据量应尽可能的小。音频的特征提取可以基于特征分析和音频帧的提取,以及音频分割的特征分析和提取。通过音频框架对音频帧的特点进行分析,并根据音频帧的特征参数对音频段进行特征分析和提取。音频的特点包括三个方面:时域特征、频域特征和感知特征。(1)时域特性:时域特性有两个方面。我们在音频帧中使用的主要指标是短时间能量和过零率。音频段中使用的指标主要有三个指标:静音比、低频能量比和高过零率。(2)频域特性:傅里叶变换后获得频域特征有两个方面。音频帧中使用的指标是频率域能量、子带能量分布、频率质心、带宽、基音频率、mfcc系数(mel-频率调合系数)。在音频部分中,我们使用了子带能量比平均值、频谱质心平均值、带宽平均值、频谱变换和mfcc系数平均值等指标。(3)感知特征:感知特征主要有音频帧特征的基高,音频段的主要特征是基本的音频标准偏差。在本发明中,在操作过程中,声学特性并不能很好地反映出音频的类特征,因此我们不会采用它。2.1音频时间域特性分析和提取音频时域特性是指一个矢量参数,它代表一个时域特性,通过在时域波形的帧中分析音频信号。过零率(zcr):指的是在音频信号的离散点上两个相邻采样点的信号值与所有采样数的比值。过零率显示了信号过零的频率,过零率也是一个常见的音频特征。其中x(m)是经过处理的离散音频信号。短期平均能量:短期平均能量是常用的音频特征参数之一。它是一个相对直观的特性,反映了音频能量的变化,这直接关系到窗口长度n的选择。n的值若太长,整个能量的变化相对平稳而差异没有反映出来,但一个窗口太窄就没有光滑的能量函数。因此,选择窗口更为重要。在本发明中,选择了haiming窗口,以在两者之间保持良好的平衡。短期平均能量可以用公式(7)来计算:当x(n)表示音频信号的第m个帧中的第n个信号值时,w(n)是先前在文本中描述的窗函数。短时间的能量可以被设置为一个阈值,在阈值以下,可判定为静音,所以短时间的能量主要用于判断音频信号是否为静音。短期的能量率可以用来判断音频信号是否属于语音、音乐和噪音的类别。2.2音频域特性分析和提取帧是我们处理的音频信号中最小的单元,计算每个帧的特征值,然后计算出片级的特征值。在帧级别上通常有几个典型的音频特性。(1)mfcc系数,mel频率变位系数是由人类听觉机制衍生而来的声学特征。人类遵循一种近似的线性关系的感知声频范围在1000赫兹以下。对1000赫兹以上的声音频率范围的感知并不遵循线性关系,而是在对数上遵循近似线性关系。mel量表描述了人类耳朵对频率的感知的非线性特征。mfcc是在mel尺度频率域中提取的一种倒谱参数。该特性具有较高的识别率和良好的噪声鲁棒性。mfcc源于两个听觉系统的研究结果。首先,人类对单音的感知与音调频率的对数近似成正比。所谓的mel频率刻度,其值通常对应于实际的频率对数分布关系。在mel频域中,人们对音调的感知是线性的。mel频率和实际频率之间的关系可以用下面的公式来近似:其次,当两个频率相近的音调同时发出时,只能听到一种音调。临界带宽是指使主观感觉减弱的带宽边界。当两个音调之间的频率差小于临界带宽时,就会听到这两个音调作为一个整体,这被称为屏蔽效应。临界带宽的计算公式如下:其中fc表示中心频率。因此,可以构造一个临界频带滤波器组来模拟人耳的感知特征。利用频谱中的滤波组方法计算了mel频率倒谱系数(mfcc)。音频被分成一系列三角形的滤波器序列。这组滤波器在频率的mel坐标系中是相同的带宽。如图3mel比例滤波器组所示。(2)频域能量,频域能量公式如下:其中f(ω)是该框架fft变换的系数,ω0是采样频率的一半。频率域能量e用于确定静默帧。如果某一帧的频域能量小于阈值,则帧被标记为一个静默帧,否则它是一个非静默帧。(3)子带能量比将频域划分为四个子带,分别为:然后计算每个子带的能量分布。计算公式如式(11)所示:其中lj和hj为子带的上、下界频率。不同类型的音频在每个子带间隔中有不同的能量分布。在每个子带间隔中,音乐的频率域能量相对均匀分布。在语音方面,能量主要集中在第0个子带,大约80%或更多。(4)过零率,在离散时间信号的情况下,具有不同代数符号的相邻样本被称为过零率。过零率是描述过零的速度,是一种测量信号频率的简单方法。公式由方程(12)给出:其中x(m)表示离散音频信号。zcr是一种更常见的音频功能。(5)频率质心,框架的亮度由帧内频率质心测量,计算方法如方程式(13)所示:(6)带宽,带宽是音频的频率范围的指示器。计算方程式为式(14):(7)音高频率。音高频率是测量音高的单位。音高周期检测方法可大致分为三类:时域法、频域法、以及用于总结信号的时域和频域特性的方法。一般情况下,基音周期是用一种更简单的峰值裁剪算法来估计的,该算法适用于中心剪裁的短期自相关函数。自相关方法的原理是,短时间自相关函数在音高周期的积分倍数上有一个较大的峰值,并且只要找到最大峰值点的位置,就可以估计音高周期。计算音高周期的步骤如下:(a)预处理:中心剪辑功能(15)用于剪辑音频,以减少共振峰的效果。限幅值l是由语音信号的峰值振幅决定的,一般取最大信号振幅的60%-70%。(b)计算y(n)和y'(n)的相关性:为了克服大量的短期自相关计算问题,在方程(15)的中心剪切后的y(n)自相关函数被两个互相关信号所取代。一个信号是唯一y(n)的,另一个信号是y(n)三阶量化后的唯一结果y'(n),即:使用以下公式计算互相关性:(c)找音高周期:选择r(k)的最大值,记作rmax。如果rmax<c*r(0)(c是阈值),被认为是无声的,因此它的音高周期为0;否则当r(k)=rmax时,音高周期为k,即:(d)后处理:由于存在声干扰、音高周期估计等因素的影响,一些零散的音高周期偏离了音高周期轨迹,对于后期处理的准确性和方便性,中值滤波技术通常用于平滑原始曲线。中值滤波是一个非线性过程。它使用一个滑动窗口从数据序列中选择一段数据,然后用数据的中值替换数据。当窗口不断地沿着数据序列滑动时,它会不断地绘制中值,这是过滤的结果。2.3基于音频片段的特征分析和提取音频部分比音频帧单元大。一个音频段通常包含几个音频帧。它的特点是在统计上划分音频帧。一般的计算方法是计算音频段中所包含的音频帧的均值、方差和标准偏差。本章中使用的主要音频片段是:(1)静音比例在频域能量中设置一个阈值。当样本框架的能量小于这个阈值时,我们称这个框架为静寂帧,否则它是一个非静寂帧。在音频段的基础上,静音框架的比例是静音比例,可以用下面的公式(19)表示。参数m表示音频段中静默帧的数量,而参数n表示音频片段中包含的所有音频帧的数量。(2)子带能量比平均值[9]是由子带能量比参数计算的音频段特征,也就是音频段中每个帧子带的能量比的平均值。该特性在信号研究中得到了广泛的应用。(3)带宽平均值意味着带宽平均值是音频段中每个帧的平均带宽,而频谱质心的平均值是音频段中每个帧的音频亮度的平均值。(4)高过零率。语言的过零率比音乐要高。如果设置了一个阈值,那么可以计算超过这个阈值的音频片段的音频帧的比例。这个比率被称为高过零率(高zcr比率)。阈值通常是音频段中过零率平均值的1.5倍。其特征值的计算公式如下式(20)所示:参数n表示音频段中音频帧的总数,zcr(n)表示音频段中第n帧的过零率。(5)低频率能量比在音频段中设置一个能量阈值。在这个能量下面被称为低频能量框架。可以计算音频段中低频能量框架的比值。这个比值称为低频能量比,被称为lrer[10],由式(21)得到。参数n是音频段中音频帧的总数,而e(n)代表音频段中第n帧的频域能量。这个公式的临界值是音频段中每一帧中能量的平均值的0.5倍。(6)频谱转换用于描述音频片段中每个相邻音频帧的光谱差异的平均参数。计算公式如(22)所示:(7)在音频段的基础音频速率标准方差,首先计算每个帧的音高频率,然后用这些音调频率参数计算它们的标准偏差,这是用来描述音高频率范围的一个特征。(8)特征向量集的组成向量集被分为两个部分,一个24维的mfcc向量,以及由音频片段提取的11维特征向量。因为特征向量之间的差异相对较大,所以需要对其进行规范化。然而,在mfcc向量集的标准化之后,实验结果并没有得到很好的改善。因此,只有片段特性是规范化和处理的。如式(23)所示:xi'=(xi-μi)/βi(23)参数xi需要规范化输入特性矢量,μi是均值,βi是方差,xi'是标准化后获得的特征值。2.4音频分类方法音频分类技术本质上是一种模式识别技术。统计学习方法具有坚实的理论基础和简单的实现机制,并被大多数当前的音频分类系统所采用。统计学习方法需要提前给出一批带有类别标记的训练样本,并通过指导学习训练生成分类器,然后对测试样本集进行分类,以测量分类性能。典型的音频分类方法包括最小距离方法,支持向量机,神经网络,隐藏马尔可夫模型和决策树。2.4.1支持向量机分类算法支持向量机(svm)是一种基于vc维理论和1995年由cortes和vapik提出的结构风险最小化的机器学习方法,而且它的性能非常好。它能解决小的样本和非线性问题。而高维模式识别和其他问题可以显示出它自己独特的优势。简单地说,支持向量机方法的目的是找到一个最优的分类超平面,它可以在最大的时间间隔内完全分离这两种类型的数据。svm可以有很好的学习效果,而不考虑两类或多分类问题。svm方法最初用于解决两类问题。下面详细解释了第二种分类的基本原则。训练样本集为x={x1...xn},x∈rd。对应的类别被标记为{y1...yn},yi∈{1,-1}。令训练样本特征向量的维数为d,样本数为n。如图4支持向量机示意图。(1)线性支持向量机对于线性可分问题,二分问题可以构造一个分类超平面,使正和负的样本可以完全分离。如图4所示。左边的实样点表示正的样本,右边的空心样本点代表负的样本。在h1和h2之间有几个分类层,所有这些都能完全分离出正和负的样本。如果其中一个分类面不仅能完全分离出正和负的样本,而且还能最大限度地增加几何间距,那么这个分类线就称为最佳分类超平面。所谓的几何间距是h1和h2之间的距离。h是分类平面,h1和h2是平行于h的直线,同时传递距离h的两种类型的样本,h1和h2上的样本点是我们讨论的支持向量。正是这些支持向量共同构建了最优的分类超平面。假设线性判别函数为:g(x)=wx+b。通常{x1...xn}满足g(x)≥1,此时,分类间隔为2l||w||。yi[wxi+b]-1≥0,i=1,...,n(24)当式(24)成立时,这个分类器可以正确地标记所有的样本。显然,最大化分类间隔实际上是最小化||w||。因此,最佳分类超平面应该同时满足方程(25)和最小化||w||。支持向量机是公式(25)的一个样本。总之,解决最优分类超平面的问题等价于以下约束优化问题:通过这种方法,将svm的解决方案转化为求解二次规划问题,从理论上说,svm的解决方案是全局唯一的最优解。首先,构造拉格朗日函数:式中ai是拉格朗日系数,分别在上面的公式中区分w和b并使它们等于0。可以得到将原始优化问题转化为对偶问题:求解上述公式可以获得各样本的相应ai值,得到的解是优化问题的最优解。只有与ai对应的样本不是0的才是支持向量。通常只有一小部分样本的ai值不是0。最后的分类函数判别法如下:由上面的公式计算的b是倾斜量。当公式中ai*不为0时,xs表示这两类样本中任何一对支持向量。在现实中,由于噪声的影响,分类样本不能被线性分离,因此无法获得未修正的分类超平面。这里的噪声可以被认为是图5中最右边的黑色点。显然,这是一个负类的样本。这个奇怪的样本使线性可分问题线性化且不可分割。通常这种问题被称为“近似线性可分性”。对于这类问题,我们通常的处理方法是,样本点最初是不小心错误地将样本错误标记的用户,这是干扰、噪音,应该被忽略。但是它的存在确实导致了这个问题是不可解的,所以在这种情况下,我们采取的解决方法,它允许少量的样本点到分类超平面的距离不需要满足原始的要求。也就是说,我们最初要求所有样本点到分类超平面应该至少大于1个区间。现在加入容错,并允许将一个硬阈值添加到硬变量中,这允许一些采样点落在几何区间内,表达式变成以下形式:松弛变量是非负的,也就是说,最终的结果是样本间隔被允许小于1。当样本点之间的间隔被计算为小于1时,这意味着分类器放弃了这些奇异点的精确分类。尽管这本身会给分类器造成一些损失,但它也允许将分类的超平面移到这些采样点,而不会受到这几个样本点的影响,从而产生更大的几何间距。所以这两者之间有多重的权重。已知||w||2是目标函数,并且期望它的取值尽可能的小,所以损失量会使||w||2更大。通常有两种测量损失的方法,第一个是二阶软间隔分类器:另一个是一阶软间隔分类器:在目标函数中增加一个损失需要一个惩罚因子,所以最初的优化问题可以如下所写:(2)非线性支持向量机介绍了支持向量机在求解线性可分性问题和“近似线性可分性问题”的基本原理。但在现实世界中,很多时候,在原始的低维度样本空间中,样本是极其不可分的。无论如何找到分类超平面,总有许多奇异点不符合要求。在此期间,有必要将低维空间中线性不可分的样本数据映射到高维空间。尽管映射在映射之后不是完全线性可分的,但它至少是“近似线性可分的”。然后用松弛变量来处理少量的奇异点,可以得到很好的结果。将一个从低维度空间映射到高维空间的样本需要通过一个内核函数来实现,因此内核函数为:k(xi,xj)=φ(xi)·φ(xj)(34)内核函数本身必须满足mercer的条件。它的基本功能是在两个低维空间中输入矢量,然后计算一个转换的高维空间的矢量内积值。所以原始的问题可以转化为以下形式:判别函数变为:。(3)对内核函数的介绍在处理非线性可分离问题时,核函数使支持向量机运行良好。由不同的内核函数构造的非线性分类器也是不同的。在处理实际问题时,目前还没有选择核函数的指导原则。更多的需要通过实验来验证,以选择最好的内核函数。常用的内核函数如下所列:(a)线性核函数:k(x,xi)=(xi·x)(38)(b)多项式核函数[17]:k(x,xi)=[p(xi·x)+s]q(39)(c)sigmoid核函数[18]:k(x,xi)=tanh(μ(xi·x)+c)(40)(d)径向基和函数:k(x,xi)=exp(-γ|x-xi|2)(41)上述核函数最广泛使用的是径向基函数,它具有广泛的收敛域,适用于各种场合,如低维、高维、小样本和大样本。最佳的径向基核函数也被选择用于音频分类。γ的值为8。2.4.2支持向量机多分类方法近年来,国内外研究人员提出的svm多类分类算法可以大致分为两类:一种是将基本两种类型的svm扩展到多类分类svm中,这种方法解决了优化问题。在这个过程中使用了很多变量,所以它是不实际的,因为计算复杂度太高了。另一种方法是逐步将多类分类问题转化为两类分类问题,即形成一个具有多个双级分类svm的多类分类器。目前,这种方法得到了广泛的应用,有两种常用的分类策略:一种针对一种[20]策略,另一种针对所有策略。(1)一对一的策略。这一策略是由knerr等人在1990年提出的。其主要思想是在分类时为任意两个类别构造一个分类超平面,并分离n个类别。要使用此策略对n个类别进行分类,总共需要n*(n-1)/2个双级svm分类器。然后,根据这两种类型的组合,对每两类分类问题进行分类器训练。在识别过程中,每个测试样本分别输入n*(n-1)/2两个分类器,每个分类器获得的分类结果被投票以获得最多的选票。样本的最终分类结果,该策略称为“投票方法”。(2)一对多的策略。这一方法是由bottou等人于1994年提出的。其主要思想是:在分类时,对于训练样本n个类别的多分类问题,首先在第i类和其他n-1类之间构造一个分类超平面。因此,该算法构造了n个两种类型的svm分类器。当第i级分类器被训练时,第i类的样本为正1,而其他类的样本点是负1,以执行两类分类问题的训练。在识别过程中,每个被识别的样本将分别输入经过训练的n分类器,并将每个分类器获得的输出值进行比较以获得分类结果。一对多策略要求每个分类器输出属于分类器判别类别的某个类的概率值,然后比较所有的输出概率值,并且具有最高概率的分类器的类被作为样本的类。支持向量机的输出是一个特定的分类,并且没有概率值输出。因此,当应用一对多策略时,我们没有找到svm的判别类别,而是找到svm的概率输出。通过这个计算过程,每个样本在每个分类中都有一个概率值,表明样本属于某一分类的概率。最后,选择了具有最大输出概率值的分类器,并且由正1表示的类别是要识别的样本的最终分类结果。一对多策略简单、有效,并且有很短的训练时间。它比一对一的策略更适合于大规模数据分类。2.5音频分割技术音频分割的目的是利用计算机程序智能地将音频流分割成不同长度和属性的片段,从而解放了手工分割的时间、劳动力和资本成本。所谓的一致性意味着音频段的特征参数在时域或频域内是相同或相似的。2.5.1基于bic理论的音频分割算法基于贝叶斯信息准则(bic)的音频分割是一种广泛使用的方法。bic准则通常通过样本的最大似然值和模型的复杂性之间的差异来检测模型是否符合bic准则。模型的复杂性通常指的是模型的参数。近年来,由于其优异的性能,已将其引入到音频分割和集群问题中。假定x={xi:i=1,2,...,n}是一段要测试的音频序列,n为信号长度,m={mi:1,2,...,k}是候选模型参数,l(x,m)是模型m中样本数据x的最大似然函数,m是模型m的数量参数,bic准则在方程式(42)中被定义:其中λ是惩罚因子,通常取为1。若信号x满足多变量高斯分布,它有一个窗口长度信号y={y1,y2,...,yn},其中n是窗口长度。为了检测y中是否存在一个分点,有必要检测y中的每一点i(0<i<n)。假设y被点i分成两部分:y1={y1,y2,...yi}和y2={yi+1,yi+2,...yn},若h0和h1在y中生成,这意味着y中没有或只有一个分度点,数学描述如公式(43)所示:对应的最大似然比可以用方程式(44)来描述:r(i)=n*ln|σ|-n1*ln|σ1|-n2*ln|σ2|(44)其中μ,μ1,μ2分别是y,y1,y2平均值,σ,σ1,σ2是它们各自对应的协方差矩阵,n,n1,n2为对应的信号长度。比较h0和h1模型,并按方程式(45)定义它们的bic值之间的差异:δbic=bic(h1)-bic(h0)=r(i)-λp(45)其中p=1/2×(d+1/2×(d+1))ln(n),d是样本空间的维度。如果所有序列的候选分割点的加权方差集大于0,这意味着在y中有一个分割点,并且假设h1是正确的。条件描述如方程式(46)所示:{maxδbic(i)}>0(46)当公式(46)满足时,在y中有一个分点,分割点所在的时刻如方程式(47)所描述:如果公式(46)不满足,那么就假定h0已经建立,也就是说,在y中没有分割点,而一个新的窗口y是通过放大n来执行bic检测的。对于一个单独的分点和多个分点,chen提出了他们自己的解决方案[24],这对于有更多过渡的短期剪辑来说是更好的选择。然而,如果要测试的列太长,并且不能在很长一段时间内检测到分割点,它无疑会增加计算量。此外,该方法容易出现累积错误。如果之前出现错误的分割点,那这个错误将会继续,并且不会在以后得到纠正。2.5.2改进的bic音频分割算法虽然在基于bic的音频分割中存在各种各样的缺陷,但它的优点是不容忽视的。为了保证算法的鲁棒性,只需稍微修改一下各种不足之处。以下是后来的研究人员为解决这些缺陷所做的一些更高的识别改进的描述。传统的bic方法的误差积累和计算的很大一部分是由于窗口长度的增加,所以后来的研究人员提出了一种更直观的改进方法,该方法基于固定窗口长度的滑动模式。对于每个检测到的bic窗口,初始窗口的长度是恒定的。如果检测到一个分裂点,将一个特定的长度滑到下一个窗口。如果分裂点未被检测到,窗的长度也增加,但当窗口长度增加到一定程度上,分裂点还没有发现,那么窗口保持当前窗口长度和滑行向前直到找到分割点恢复初始窗口长度。即使检测到分割点,窗口的长度也不会增加,并且会直接向后移动。下面结合实验对本发明的应用作进一步描述。该实验都是在matlabr2014b环境,windows7版本,64位操作系统,intelcorecpu,时钟频率为3.40ghz以及内存为8gb的条件下完成的。实验测试音频数据被人工分类为无声/噪音、纯语音、混合语音、音乐、环境声音等,并作为训练样本和测试样本的混合使用。有许多音频格式,如wav,mp3,midi。这些通道被分为单声道、双通道和多通道。采样率为44.1khz,32khz,16khz,8khz,精度为32位,16位和8位。音频在音频实验前进行了标准化,采样频率为44.1khz,量化精度为16位,音频文件统一为wav,并对大学频道数据进行分析。音频分为剪辑序列数是3600,手动分类后,静音剪辑760,噪音剪辑630,音乐剪辑570,纯语音剪辑530,带背景声音的声音剪辑560,环境声音剪辑550。下面结合静音和噪声的分类对本发明的应用作进一步描述。1)安静和噪音使用基于规则的分类方法。实验设计如下:对所有样本进行静音和噪声域值的判定,对正确的分类编号进行记录,计算出错误分类的数量(非静音但被判定为静音的剪辑数量),并计算出分类精度。实验结果如下:表1噪声/静音分类结果正确分类数错误分类数分类准确率噪声54112785.87%静音7092393.28%对于其他类别,音频大小显然是不同的,因此识别精度很高。错误分类主要是由于在一个片段中,它包含了静音和其他音频类别,所以能量平均值可能相对较小。解决了降低能量阈值的方法。对噪音的识别精度为85.87%。分析的原因是,不同音频类别中出现的噪声源不一样,因此噪声的时频特性也有所不同。单一阈值用于判断缺乏普遍性。因此,在测试中噪声判断的准确性不高,假正率高。在能量谱上有微小变化的环境声音很容易被错误地判断为噪音。2)每个音频类别的分类基于svm的分类器用于对纯语音/背景声音和音乐/环境声音进行分类。每一种分类都要进行三次试验。表2纯语音/背景声音的声音分类结果表3音乐/环境声音分类结果从实验中可以看出,支持向量机分类器的分类精度非常高,纯语音和背景声音的平均分类精度为91.28%,音乐和环境声音的平均分类精度也为90.77%。从实验数据可以看出,所提出的支持向量机分类器对音频分类工作具有较好的分类效果和精确度。3)传统δbic分割方法和改进的δbic分割方法实验分别采用传统的分割方法和改进的分割方法。为了比较改进的分割方法与传统分割方法的精度,验证了传统分割方法的合理性,并验证了改进后的分割方法的有效性。采用传统的分割方法和改进的分割方法对分类结果进行了分割。表4分割测试结果分割方法分割结果正确数量/精度漏判误判传统分割方法165127/82.5%2738改进的分割方法148135/87.6%913传统的δbic分割方法等价于改进的δbic分割方法,并且检测到的分割结果的数量远远大于改进的方法。分析的原因是传统的方法只对分类结果进行了平滑处理,然后直接将同一类别的音频组合在一起,获得分割结果。不考虑相邻段之间的相互作用,忽略了分割的总体优化问题。这就相当于放松了音频镜头分割的限制,提高了准确率,将不可避免地导致错误分类的增加,从而导致更多的被检测到的音频镜头。改进的方法将分割问题转化为优化问题解决方案。它是一种动态的方法,充分考虑了分段之间的相互作用和分割的整体优化,从而大大降低了误报的数量,而且精度也得到了一定的提高。结果表明,优化方法的实际效率明显高于传统方法。下面结合效果对本发明的应用作进一步描述。音频分类是音频信息深层处理的基础,是音频结构的核心技术,是提取音频结构和内容语义的重要手段。它根据所感知的特点或表达的内容,将音频数据分为不同的类别,在基于内容的视频分割、语音检索和音频监督中起着重要的作用。音频分类也是音频信息处理、音频信息检索和数据管理的关键技术之一。虽然音频分类没有很长的历史,但研究人员在这一领域进行了更详细的研究,这不仅使该领域的知识成为一个完整的系统,而且在一定程度上促进了音频信息处理技术的发展。从本质上说,音频数据的分类可以被认为是模式识别的过程。它的重点通常包括音频特征分析和提取的两个基本方面,以及分类器的设计和实现。一种基于svm的音频分类算法,将音频分为六类:静音、噪音、音乐、背景声音、纯语音和背景声音。在分类的基础上,提出了一种平滑准则,并对分类结果进行了平滑处理,最后通过音频分类对音频流进行了分割。实验结果表明,基于svm的分类算法具有良好的分类效果和较高的分类精度。平滑处理进一步提高了分类精度,减少了误分类率,并使分割结果更加准确。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1