基于BloomFilter的海量数据查询方法与流程
本发明涉及一种海量数据查询方法,特别是涉及一种基于bloomfilter的海量数据查询方法。
背景技术:
随着大数据时代的到来,分布式数据库的发展和应用越来越广泛,数据系统存储的数据越来越海量,需要可以组建成规模上千的集群,处理pb级别的大数据分析系统。apacheimpala、presto、apachedrill、apachehawq等都是目前基于mpp架构的sql-on-hadoop(hdfs)查询引擎,它们提供了类sql的语法,能够提供较高的响应速度和吞吐量,能够对pb级数据进行交互式实时查询、分析。但这些sql引擎在读取文件时,并不能区分该文件中是否包含所需要查询的数据,随着数据量的增加特别是面对着海量数据,查询性能也会随之急剧下降。
bloomfilter是由布隆(burtonhowardbloom)在1970年提出的。它实际上是一个二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中,能够有效地提高检索的效率。但是bloomfilter目前没有在apacheimpala中的应用,也没发现在其他sql引擎中的应用。
技术实现要素:
发明目的:本发明要解决的技术问题是提供一种基于bloomfilter的海量数据查询方法,能够判断文件中是否包含所需查询的数据,过滤了不包含所需查询数据的数据文件,减少了不必要的数据读取和查询,在海量数据的情况下能够大幅提高数据查询的性能。
技术方案:本发明所述的基于bloomfilter的海量数据查询方法,包括以下步骤:
(1)使用sql引擎将收集到的海量数据按分区存储到数据系统中,生成sql逻辑表,形成数据文件;
(2)基于bloomfilter算法,对数据文件生成bloomfilter索引;
(3)查询数据时,sql引擎根据所述的bloomfilter索引信息判断数据文件中是否包含请求查询的数据,从而决定是否读取该数据文件。
所述sql引擎可以是apacheimpala、presto、apachedrill、apachehawq中的任一种。
进一步的,所述海量数据是通过消息中间件从多种数据源收集、过滤和预处理后得到的,包括结构化和非结构化数据。
进一步的,所述的数据系统是分布式文件系统hdfs。
进一步的,步骤(2)中每1个数据文件对应1个bloomfilter索引,该索引信息存储在关系数据库中。
进一步的,步骤(2)中的生成bloomfilter索引包括以下步骤:
(21)建立m位的bit数组,m由文件数据量大小决定,数组中每一位的数值都为0;
(22)对sql表中的字段数据x做k次hash运算,其中第i次hash运算结果n=(hash(x)%m),每次运算后将所述m位的bit数组中的第n位中设置为1,其中1≤i≤k≤m。
进一步的,步骤(3)中的具体步骤为:对查询数据y做k次哈希运算,如果运算所映射的m位的数组中相应位置都为1,则判断包含数据y,将数据文件保存到待读取文件列表中;如果不全为1,则判断不包含对象数据y,忽略该数据文件。
进一步的,上述方法还包括针对新增数据的操作:对新增数据进行k次hash运算,将结果映射到所在数据文件对应的bloomfilter索引中并更新索引信息。
有益效果:本方法能够在进行数据查询时,根据bloomfilter索引判断分片文件中是否包含所需要查询的数据,以空间换时间,利用少量的存储空间存储bloomfilter索引信息,换取了在数据查询时,减小大量的不必要的系统io,从而大幅提升数据查询性能百倍以上。
附图说明
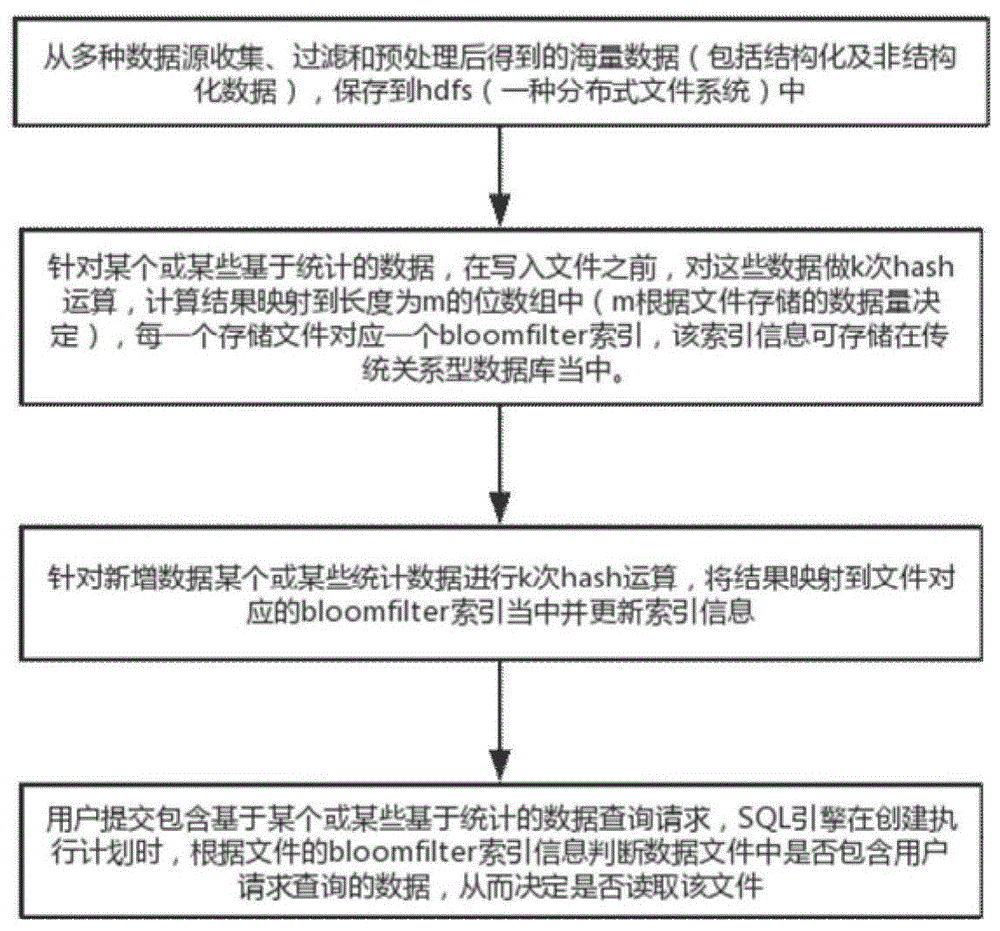
图1是本方法实施方式的整体流程图;
图2是传统impala查询引擎查询架构图;
图3是经过bloomfilter索引优化后的impala查询引擎查询架构图;
图4是使用bloomfilter索引优化后的查询过程图;
图5是本实例中查询所耗时间对比示意图。
具体实施方式
如图1所示,本方法的流程为,首先从不同的数据源收集,过滤和预处理后得到的海量数据保存到hdfs中;针对某个或某些基于统计的数据,利用bloomfilter算法,对这些数据做k次hash运算,计算结果映射到长度为m的位数组中,生成bloomfilter索引;针对新增的数据同样需要做k次hash运算,计算结果映射到上述位数组中,更新索引信息;用户提交包含基于某个或某些基于统计的数据查询请求,sql引擎在创建执行计划时,根据文件的bloomfilter索引信息判断数据文件中是否包含用户请求查询的数据,从而决定是否读取该文件。
本方法可以应用在当前主流的sql引擎apacheimpala、presto、apachedrill、apachehawq中,本实施方式以apacheimpala为例描述实施过程,检验技术效果。具体如下。
步骤1,从不同的数据源收集,过滤和预处理后的海量数据,保存到分布式文件系统hdfs中。在该步骤中,首先利用各种中间件从不同的数据源收集数据,具体实现中,由于收集的数据中包含重复及“无效”等数据,因此需要对收集的数据经过预处理后保存到分布式文件系统hdfs中。
步骤2,针对某个或某些基于统计的数据,利用bloomfilter算法,基于impala创建bloomfilter索引。在该步骤中,针对某个或某些基于统计的数据,在写入文件之前,对impala表中的字段数据x做k次hash运算,其中第i次hash运算结果n=(hash(x)%m),每次运算后将所述m位的bit数组中的第n位中设置为1,其中1≤i≤k≤m。每一个存储文件对应一个bloomfilter索引,该索引信息可存储在传统关系型数据库当中。
例如,某系统每天存储约2t的移动用户信号数据,每5分钟一个分区,每天288个存储分区,每天约存储5万个文件,每个存储文件大小在30m~100m不等。在创建存储文件后,相应的每个文件初始化一个长度为m的位数组,每一位初始值为0。当进行数据写入时,针对某个或某些基于统计的数据作k词hash运算,并将结果映射到上述位数组中。当需要查询某个用户近一个月的运动轨迹时,impala查询引擎会按分区信息读取一个月的所有的分区文件,以每个文件0.05秒读取一个文件计算,查询某个用户近一个月的移动轨迹需要大约10min(100万个文件*0.05)的时间。图2所示的是传统的impala查询架构。为了提升查询性能,本发明引入bloomfilter算法,在写入数据时,根据用户的号码进行k次hash运行,将结果映射到长度为m的位数组中,生成长度为m的bloomfilter索引。当查询某用户近一个月的移动轨迹时,在读取文件之前,同样需要对所要查询的用户号码进行k次hash运算,将计算结果映射到文件对应的bloomfilter索引中,判断文件中是否包含所需要查询的信息。该方法可过滤掉大部分不包含用户数据的文件,减少系统的io,从而大幅提升查询性能。图3所示是经过bloomfilter索引优化后的impala查询引擎查询架构,图4所示的是使用bloomfilter索引优化后的查询过程。
步骤3,针对新增的数据,针对某个或某些基于统计的数据进行k次hash运算,并将结果映射到文件对应的bloomfilter索引中。在该步骤中,在impala查询引擎中创建一个线程,扫描已写完的分区中的文件,对文件中的基于统计的某个或某些数据做k次hash运算,并将计算结果更新到文件所对应的bloomfilter索引中。
步骤4,用户提交包含查询基于某个或某些基于统计的数据查询请求,impala引擎在创建执行计划时,根据用户提交的查询请求中基于某个或某些基于统计的数据,查询对应文件的bloomfilter索引,判断数据文件中是否包含用户所要查询的数据,如果包含,则将该文件保存到执行计划待读取文件列表中;如果不包含,则忽略该文件。在该步骤中,sql引擎根据用户的查询请求,生成执行计划,impala引擎将执行计划分发给各个执行节点,执行节点在读取文件之前,根据文件对应的bloomfilter索引,判断是否有必要读取该文件。
例如,当需要查询某移动用户2018年10月1日至2018年10月7日这段时间范围内的移动轨迹时,impala引擎根据用户提交的查询请求生成执行计划,需要读取分析的文件分区包括2018年10月1日至7日的所有分区文件。执行节点在读取文件之前,根据用户的号码进行k次hash运算,并将结果映射到文件对应的bloomfilter索引上,如果索引对应的位上的值为1,说明该文件中可能包含所需要查询的数据。如果索引对应的位上的值为0,说明该文件中并不包含所需要查询的数据,则不必再读取该文件。
以具体的实验数据进行分析如下:在本实验中,采用5台服务器搭建了一个hadoop集群,服务器cpu采用e5-2630v4*2,内存128g,硬盘为12*2t的sata,全部的总数据量大小为1.3t,超过100亿条数据记录,字段包括时间戳(timestamp)、ip地址、低基数列、高基数列等,其中ip详单及字符串详单创建bloomfilter索引,查询优化前及优化后的耗时对比如图5所示。实验证明,在充分发挥hadoop集群的分布式存储和分布式计算能力的情况下,100亿数据量的查询平均的响应时间可以控制在在10s以内。与传统的方法相比,查询效率提高了百倍以上,具有非常显著的技术效果。
- 还没有人留言评论。精彩留言会获得点赞!