一种基于LSTM神经网络的医疗单据识别方法与流程
本发明涉及图像处理的技术领域,尤其是指一种基于lstm神经网络的医疗单据识别方法。
背景技术:
在保险理赔行业中,理赔单据包括医疗发票、药物清单、病历、检验单等都是重要的理赔依据。目前对保险公司而言,由于数据积累的需要和监管要求,对于原始单据的信息采集往往要求非常旺盛,但是受限于成本压力,目前大部分保险公司仅仅通过bpo采集了发票信息,其他票据信息往往转变为沉默数据,无法支撑保险公司产品设计和自动化□控的要求。传统的bpo方式主要依赖于人工录入,需要对票据进行人工分类,人员投入巨大,而且数据安全管理复杂,整体的效率非常低。
目前,并没有针对保险行业形成一种专门的保险理赔单据识别方法,现如今大多是对金融票据进行识别,采用神经网络模式识别的方式,对票据的金额数字和身份证数码进行了分割、图像处理和特征提取,并在此基础上用改进的bp网络对其进行了识别。
本文采用lstm神经网络对理赔单据进行识别,lstm是一种时间递归神经网络,所有的rnn都具有一种重复神经网络模块的链式形式,lstm区别于rnn的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。一个cell当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入lstm的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。因此采用lstm神经网络来识别理赔单据,不仅能够提高识别的准确度,还能将提高分类的准确性。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出了一种基于lstm神经网络的医疗单据识别方法,可以有效地提取单据的属性特征,识别单据的具体内容,并根据属性特征对票据进行自动分类,并且lstm神经网络结构复杂性低,计算速度高效,可以有效提高效率和识别精度。
具体地,通过版面分析提取相互独立的图像单元与对单据版面进行识别两个方法。首先由于单据模板种类繁多,盖了常□的医疗单据,如发票、药物清单、病例、诊疗卡、检验单等,模版方式的识别是无法满足需求的,需要采取端到端的模式,实现单据类型的自动归类,属性字段的自动提取,提高分类的准确度。
其次,医疗单据本身由于打印精度限制等因素,单据本身往往容易出现错位、错行、表面污渍等,另外医院还会根据管理要求叠加医院印章、交费告知等信息,噪音信息量较大,需要对单据进行预处理,包括去噪、倾斜校正和倾斜校正等操作,然后通过lstm神经网络对单据提取主要特征信息,提高识别精度。
为实现上述目的,本发明所提供的技术方案为:一种基于lstm神经网络的医疗单据识别方法,包括以下步骤:
1)单据图像预处理,将图像信号转化成数字信号;
2)分割字符,将单据图像归一化;
3)提取字符特征,生成特征向量;
4)单据识别与分类。
在步骤1)中,单据图像预处理,将图像信号转化成数字信号,具体如下:
在采集和获取图像的过程中,由于环境的干扰会产生噪声,影响单据分类的准确性,针对单据存在较多椒盐噪声的特点,采用中值滤波的方法对图像进行滤波。在图像扫描时,图像可能会出现一定的倾斜,增加了后续分类操作的难度,因此需要做倾斜校正。采用基于方向投影的倾斜检测算法,用不同倾角的扫描线对图像进行扫描,计算出扫描线方向的最大投影;在所有的方向最大投影中再寻找最大值,取得该最大方向投影的扫描线方向即为单据图像的倾角方向。识别区域定位和字符识别之前的预处理可以根据需要进行二值化操作,为了能够更好地适应书写质量差或背景情况复杂的图像,本文采用自适应阈值法对图像进行二值化操作:把大于某个临界灰度值的像素灰度设为灰度极大值,把小于这个像素灰度设为灰度极小值。自适应阈值t(x,y)在每个像素点都不同,通过计算像素点周围b*b(b由参数指定)区域加权平均,对区域所有像素进行平均加权,获取临界灰度值,最终得到二值化图像,将图像信号转化成了数字信号。
在步骤2)中,分割字符,将单据图像归一化,具体如下:
在步骤1)中,已经获得单据的二值图像,根据二值化图像进行字符分割。首先,对多字符目标进行水平投影,根据y轴投影值可将多字符目标分割成不同的行;再对同一行字符做垂直投影,根据x轴投影值,可将其分割成多列;根据行、列值,可分割出单个字符。以垂直投影为例,具体做法是:以一条垂直线从左到右扫描一行字符,根据该垂直线在某位置是否遇到黑像素决定这一位置是否有字符。最后将分割的字符图像归一化为24*24的单一字符图像。
在步骤3)中,提取字符特征,生成特征向量,具体如下:
采用粗网格特征提取方法,把独立的单个二值化字符纵横分割成由n个网格组成的形式,取每个网格中字符像素(设为白色像素)占总字符像素的比例,将所有比例值排成一列就形成n维特征向量。本发明把归一化后的字符图像,纵向上分为20份,横向上分为12份,故20×12=240个1或0构成的列矩阵就作为字符的输入特征,这样对于每一个输入样本就要240个特征,即可确定输入层的节点数为240。
在步骤4)中,单据识别与分类,具体如下:
首先定义一个lstm模型,需要传入的参数是输入数据的维数为20,输入维数为240,层数为2,输出节点数即分类数目为10(根据具体情况设定),隐藏节点数通过以下两个经验公式来确定,并根据实际情况做出调整;
其中,m为隐层节点数,n为输入层节点数,l为输出层节点数,α为1~10之间的常数;
lstm神经网络分为输入层、隐含层和输出层。输入层负责接收信息,并传递给隐含层;隐含层负责信息变换,最后一个隐含层负责传递信息到输出层;输出层向外界输出信息处理结果。lstm神经网络的学习过程包括正向传递和误差反向传播两个过程。数据经正向传递从输入层开始,经隐含层逐层计算,传到输出层,若输出层的实际输出和期望输出不符,则计算输出层的误差值,然后反向传播误差,也就是将输出误差以某种形式通过隐含层反传回输入层,并将误差分摊给各层所有神经元,从而获得各层神经元的误差,此误差作为修正该神经元参数的依据,最终识别出单据中的药品名称、金额等信息;
最后外接一个softmax分类器,取输出的最后一个部分传入分类器求出分类概率,最终得出单据的分类。
本发明与现有技术相比,具有如下优点与有益效果:
1、本发明创造性地采用lstm神经网络对图像进行识别和分类,识别速度快,容错能力强,识别率高,可以有效避免字符断裂、粗细不均带来的不良影响。
2、本发明采用lstm神经网络,迭代次数少,训练准确率高,识别率高,分类结果好。
3、本发明采用新的倾斜校正算法,既减少了扫描次数又提高了扫描速度。
4、本发明的网络结构简单,识别和分类过程同时进行,减少计算量,计算高效,从而达到实时性。
附图说明
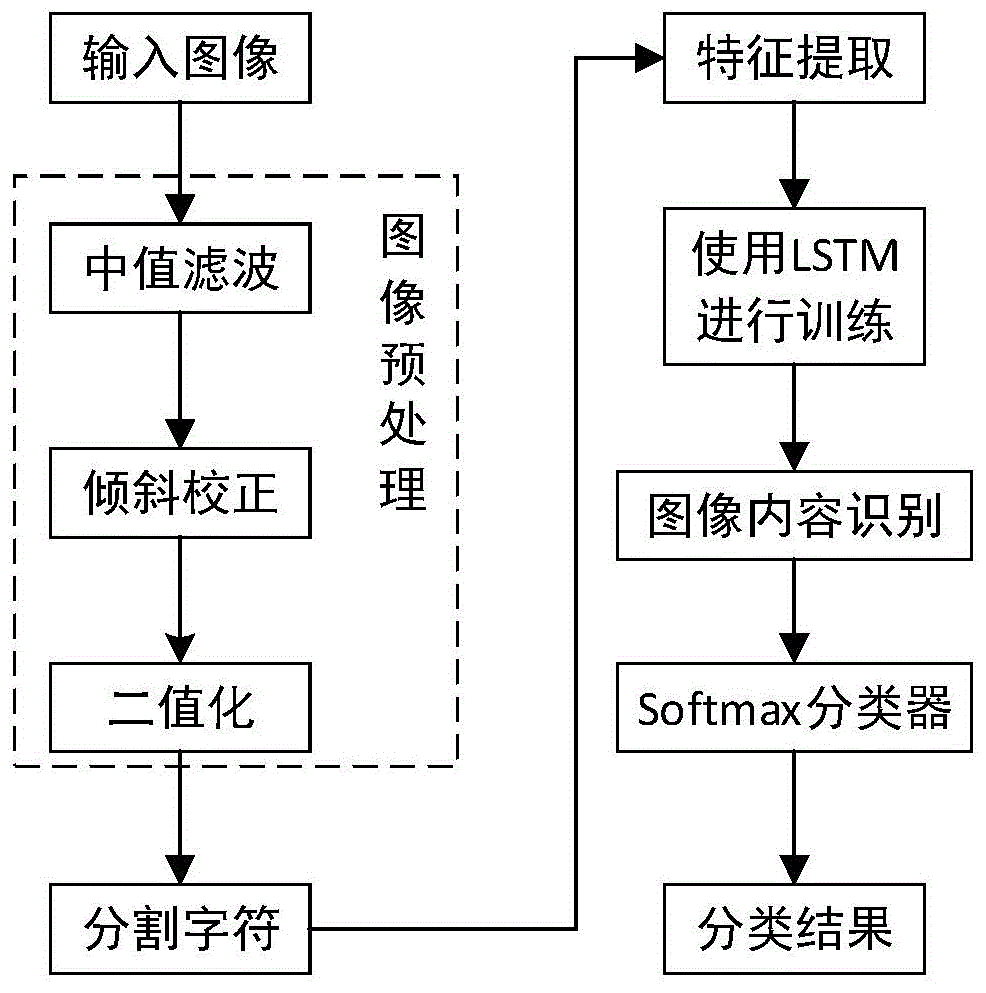
图1是保险理赔单据识别流程图。
图2是单据识别分类网络结构图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
本实施案例所提供的基于lstm神经网络的医疗单据识别方法,输入一张医院收费单据进行识别。单据图像识别的完整流程如图1所示。在预处理图像文件时,使用算法将图像信号转化成数字信号;接下来,分割图像字符,将图像归一化成统一大小;然后,提取图像特征生成特征向量;再使用lstm神经网络识别图像内容;最后,采用softmax分类器将单据进行分类。其具体包括以下步骤:
1)图像预处理:首先,对输入的单据图像进行中值滤波,滤除椒盐噪声。如果所要进行识别的图像倾斜度比较大,先用一个较大的扫描线角度步长进行扫描,求出最大的方向投影并记下对应的扫描线角度,然后把以该角度为中心的一个邻域作为精求倾斜角时的检测范围,检测出了图像的倾角后,即可实现对图像的倾斜校正。最后,通过自适应阈值法将图像转化成灰度图像,将图像信号转化成数字信号,便于后续的特征提取。
2)分割字符,将单据图像归一化。首先,对多字符目标进行水平投影,根据y轴投影值可将多字符目标分割成不同的行;再对同一行字符做垂直投影,根据x轴投影值,可将其分割成多列;根据行、列值,可分割出单个字符。以垂直投影为例,具体做法是:以一条垂直线从左到右扫描一行字符,根据该垂直线在某位置是否遇到黑像素决定这一位置是否有字符。最后将分割的字符图像归一化为24*24的单一字符图像。
3)提取字符特征,生成特征向量。把归一化后的字符图像,纵向上分为20份,横向上分为12份,故20×12=240个1或0构成的列矩阵就作为字符的输入特征,这样对于每一个输入样本就要240个特征,即可确定输入层的节点数为240。
4)单据识别与分类网络结构如图2所示,识别与分类的过程如下:
定义一个lstm模型,需要传入的参数是输入数据的维数为20,输入维数为240,层数为2,输出节点数即分类数目为10,隐藏节点数通过以下两个经验公式来确定,并根据实际情况做出调整:
其中,m为隐层节点数,n为输入层节点数,l为输出层节点数,α为1~10之间的常数。
lstm神经网络分为输入层、隐含层和输出层;输入层负责接收信息,并传递给隐含层;隐含层负责信息变换,最后一个隐含层负责传递信息到输出层;输出层负责向外界输出信息处理结果。
首先,将240维特征作为输入,输入到lstm网络的输入层,并传递给隐藏层,隐藏层获取特征中的信息,并交换信息,最后一个隐含层将信息传递到输出层,通过逐层计算,若输出层的实际输出和期望输出不符,则计算输出层的误差值,然后反向传播误差,也就是将输出误差以某种形式通过隐含层反传回输入层,并将误差分摊给各层所有神经元,从而获得各层神经元的误差,此误差作为修正该神经元参数的依据,最终当误差达到最小的时候,即获得识别结果,识别出单据中的药品名称、金额等信息。
最后,将lstm网络的输出特征融合,输入到softmax分类器,根据预先设定好的分类数,求出每种分类的分类概率,概率越高,说明该单据属于该分类,最终得出分类结果。
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!