一种基于消息队列的MongoDB数据实时同步方法及系统与流程
本发明涉及计算机信息技术领域,具体涉及一种基于消息队列的mongodb数据实时同步方法及系统。
背景技术:
随着信息时代的到来,数据量急剧增加,包括各种结构化的数据和非结构化的数据,面对大规模的数据量和复杂的数据类型,传统的数据存储和数据检索方式都已经不能满足需求,而mongodb和elasticsearch(简称es)的出现有效地解决了大数据模式下的数据存储和数据检索的问题。
mongodb作为nosql的一个主流数据库,它基于文档进行存储,与传统的关系型数据库不同,它不需要预定义数据模式。mongodb副本集从节点通过操作日志异步复制主节点的数据,这个操作日志就是mongodb的oplog。oplog是一个特殊的数据集合,用来存储mongodb的所有操作日志,它在mongodb启动之前就被预先设置好了存储容量,且不能轻易修改,其存储方式类似于环形缓存器,当其存储空间不足时,新插入的数据会按时间顺序覆盖旧的数据。oplog的数据存储格式如下所示:
其中,“ts”表示本次操作发生的时间戳,“op”表示本次的操作类型,“ns”表示本次操作针对的集合名称,“o”表示操作的具体内容。
虽然mongodb可以很好地被应用于大数据的存储,但是其在检索和查询方面存在一些弊端,如无法适用于分词查询等,并且查询速度较慢,无法做到实时检索,而elasticsearch作为一个企业级的全文搜索引擎,可以很好地解决这一问题。
elasticsearch使用lucene作为开发的核心,通过提供restfulapi接口,可以实现各种复杂的查询,并且查询速度较快。但是elasticsearch不适合直接用作数据存储,因为使用elasticsearch存储数据时有数据模式的要求,当数据模式一旦设定好之后,就不能轻易修改,因此一般不采用elasticsearch直接用作存储数据。
在实际的应用中,采用mongodb存储数据,elasticsearch检索数据时,就存在两者之间的数据同步问题。目前业界使用较多的是mongo-connector这一开源工具,该工具基于python开发,并作为第三方包进行使用。该工具通过跟读mongodb下的oplog,进而创建一个从mongodb到elasticsearch的数据通道,最终实现两者之间的数据同步。
上述同步工具有其不足之处,主要表现在以下两个方面:
(1)同步速度慢:mongo-connector同步数据时,受数据类型、数据复杂程度等多方面的影响,导致向目标系统elasticsearch同步数据时速度比较慢。如在该部署环境中,使用一个索引的情况下,同步的数据单条约2.2kb大小且多层嵌套,其同步速率仅为480条/秒,而mongodb的写入速度约为700条/秒,可见同步的速率远不及mongodb的写入速度。
(2)数据丢失:mongo-connector同步工具通过定时读取mongodb的oplog,解析日志内容,实现mongodb数据的实时同步。然而,由于mongodb在启动时需要预先设置oplog的数据存储容量,当日志规模超过oplog预先设置的容量时,日志数据会根据时间顺序覆盖oplog中已经存在的数据。因此,当mongo-connector的同步速度小于mongodb的日志刷新速度时,特别是大规模数据短时间内写入或者更新,就会造成同步数据的丢失,甚至会导致同步系统崩溃。在解决上述问题时,目前大多是采用修改oplogsize的方法。修改oplogsize可以缓解上述问题,但是不能从根本上解决问题,因为当oplogsize设置的特别大,不仅仅会造成磁盘空间的浪费,同时由于oplog不使用索引,所以初始查询代价特别大,从而降低同步的速率,无法做到数据的实时同步,因此给数据同步带来了很大不便。
技术实现要素:
本发明的目的是提出一种基于消息队列的mongodb数据实时同步方法及系统,旨在实现从mongodb到目标系统elasticsearch的实时数据同步,并解决原来的同步工具在数据同步过程中同步速率慢和由于mongodb快速写入情况而引发的同步数据丢失的问题,保证了从mongodb到elasticsearch的快速、准确、可靠的数据同步。
为实现上述目的,本发明采用如下技术方案:
一种基于消息队列的mongodb数据实时同步方法,步骤包括:
创建mongodb与kafka之间的长连接;
跟读mongodb的日志文件oplog,对读取到的需要同步的bson数据进行初步解析,并根据oplog数据中的“ns”字段,将mongodb的集合名映射成设定的elasticsearch的索引名;
将该bson数据转码成可以缓存到kafka的序列化数据,并缓存到kafka上的与elasticsearch索引名同名的topic中;
为每一个topic创建一条从kafka到elasticsearch的长连接;
从kafka的topic中读取之前缓存好的数据,并转码还原成bson数据,再进一步解析;
解析每一条数据的操作类型,并为之调取对应的操作方法;
最后把数据解析成elasticsearch可以识别的数据结构,并缓存在本地;
本地缓存的数据达到设定的阈值时,批量提交到elasticsearch中。
进一步地,如果kafka上不存在topic,则自动创建topic。
进一步地,操作类型包括“i”、“d”、“u”、“c”,对应的操作方法包括“insert”、“delete”、“update”、“cmd”。
一种基于消息队列的mongodb数据实时同步系统,包括:
一连接创建模块,用于解析配置文件中的各项参数并初始化,指定要同步的数据集合的名称和所匹配的索引的名称,同时创建mongodb与kafka之间的长连接,形成mongodb的数据集合到kafka的topic的多条数据通道;
一数据读取模块,用于跟读mongodb中的oplog,对读取到需要同步的bson数据进行初步解析,转码成可以缓存到kafka中的序列化数据;
一命名解析模块,用于把从mongodb中读取到的oplog数据中的“ns”字段的集合名解析替换成与之匹配的elasticsearch中的索引名;
一数据缓存模块,用于将序列化数据发送到kafka中进行缓存,数据读取时,再将从kafka中读取的序列化数据转码成bson数据,并进一步解析,根据解析之后的数据的操作类型,调取对应的操作方法;
一数据同步模块,用于提供对应于数据操作类型的操作方法,并根据数据缓存模块所调用的操作方法,将数据解析成elasticsearch可以识别的数据结构,并缓存在本地,最后批量同步到elasticsearch中。
进一步地,数据读取模块将从mongodb中读取的oplog数据由bson类型转码成序列化的数据,便于之后在kafka中进行存储。
进一步地,当kafka中的topic不存在时,数据缓存模块可以自动创建topic。
进一步地,从kafka向elasticsearch同步数据时,数据同步模块会为每一个topic创建一个同步线程,多线程可以并行操作。
进一步地,命名解析模块支持正则解析。
进一步地,操作类型包括“i”、“d”、“u”、“c”。
进一步地,数据同步模块提供了“insert”、“delete”、“update”、“cmd”的操作方法,用于对elasticsearch进行数据插入操作、数据删除操作、数据更新操作和命令行操作。
本发明采用缓存机制,对从mongodb到elasticsearch的数据进行同步,取得以下效果:
(1)解决数据丢失的问题:本发明通过增加缓存机制kafka,有效地解决了数据丢失的问题,经测试结果表明,即使oplog的大小只有10m,也不会造成数据的丢失。
(2)解决数据同步速率慢的问题:本发明采用了多线程并行操作的方式,从kafka向elasticsearch同步数据时,本系统会自动检测目前所有的topic,并为每一个topic创建一个线程,多个线程并行工作,从而提高了数据同步的速率,如在两个索引时,原同步工具仅为480条/秒,但是本程序的同步速率约为720条/秒,因此多topic的使用有效地对数据同步速率进行了提升。
(3)保证数据同步具有实时性:本发明增加了缓存机制,因此oplog可以初始设置的很小,当创建新的索引时,同步工具从头遍历oplog所需的时间就很短,数据同步的时延就很小,因此保证了数据同步的实时性。
附图说明
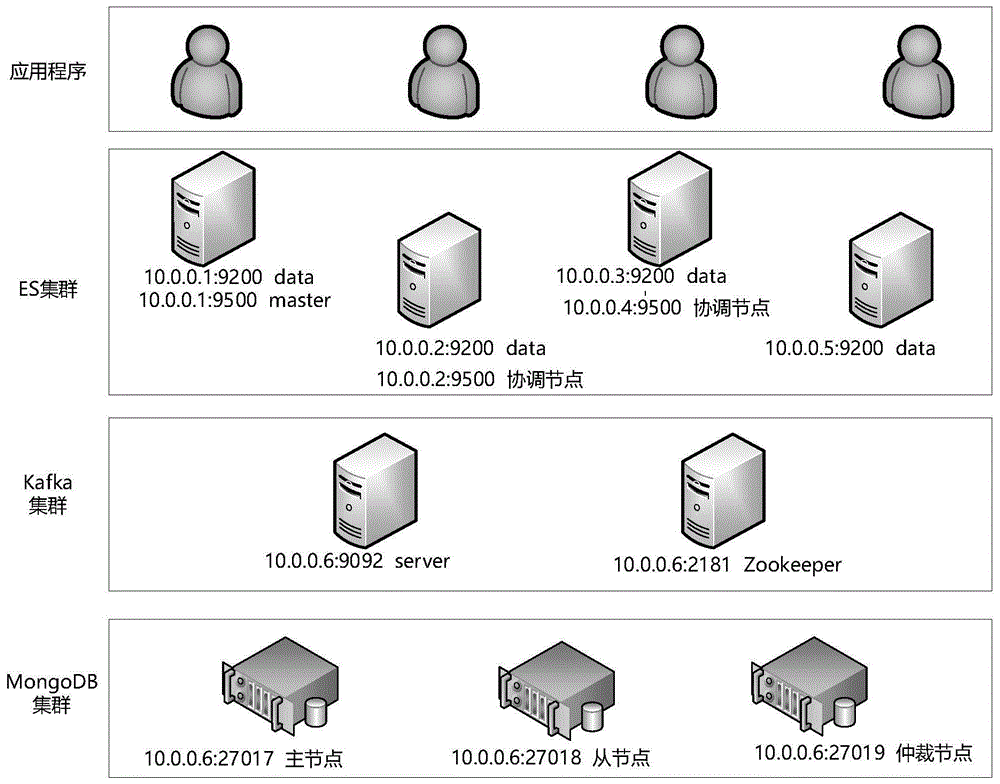
图1是一种基于消息队列的mongodb数据实时同步系统的部署示意图。
图2是一种基于消息队列的mongodb数据实时同步系统框架图。
图3是一种基于消息队列的mongodb数据实时同步方法流程图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
本实施例提供一种基于消息队列的mongodb数据实时同步系统,属于一种带有缓存机制的数据同步工具,用于解决在大数据量时由于oplog容量小而导致的数据丢失的问题,进而实现从mongodb到elasticsearch的可靠的数据同步。在本发明中,数据流由原来的从mongodb直接同步到elasticsearch,变成了从mongodb先缓存到kafka中,然后再从kafka同步到elasticsearch中,如图1所示。
本系统包括五个模块:连接创建模块、数据读取模块、数据缓存模块、数据同步模块和命名解析模块,如图2所示,各模块实现的功能如下:
连接创建模块用于解析配置文件中的各项参数并初始化,同时还要创建mongodb与kafka之间的长连接。
数据读取模块用于初始化游标,并对从mongodb中读取的oplog进行初步的过滤和解析,最后将需要同步的oplog数据进行转码,从mongodb中的bson类型转码成string类型,形成可以缓存到kafka中的序列化数据。
数据缓存模块的作用有两个:一是把已经序列化的数据发送到kafka中进行缓存;二是把读取kafka中已经缓存好的数据,将读取到的数据转码,还原为bson格式并再次进行解析,根据解析之后的数据中的操作类型,从数据同步模块中调取对应的方法,如操作类型为“i”,则调取对应的“insert”的方法。
数据同步模块主要包括了对数据的“insert”、“delete”、“update”以及“cmd”操作方法,当这些方法被数据缓存模块调用以后,就会将该条oplog数据解析成elasticsearch可以识别的数据模式,缓存在本地,最后以批量的方式同步到目标系统elasticsearch中。
命名解析模块用于把从mongodb中读取到的oplog中的集合名称解析替换成elasticsearch中的索引名,并且该模块还支持正则解析。
结合上述系统的各模块,实现的方法流程如图3所示,具体说明如下:
(1)在系统启动以后通过连接创建模块,创建一个从mongodb到kafka的长连接,等待数据同步,与此同时,该模块还会解析配置文件或命令行的各种参数设置,获取本次数据同步的数据集合名和与之对应的索引名,以及同步的批量大小等。
(2)之后系统便开始调用数据读取模块,跟读mongodb中的oplog,对读取到的数据进行过滤和解析;过滤时,如果该条数据中的如“ns”字段的集合名不在本次同步的范围内,则直接跳过,如果是需要同步的数据,就调用命名解析模块,把该条数据中的“ns”字段的集合名解析替换为索引名。由于从mongodb中读取到的数据是bson类型,因此还需要把它转码成可以缓存到kafka的序列化数据。
(3)当数据转码完成以后,就会调用数据缓存模块,把转码后的数据批量发送到kafka中进行缓存,根据“ns”字段的索引名称,数据会被发送到与索引同名的topic中,如果topic不存在,还可以自动创建。
(4)对于已经缓存在kafka中的数据,数据缓存模块会把topic中的数据读取出来,并为每个topic创建一个从kafka到elasticsearch的长连接,作为数据同步的线程。由于读取出来的数据是序列化的数据,所以需要再次转码成bson类型,根据转码后的数据中“op”字段的操作类型,在数据同步模块中调取合适的方法,如“i”调用“insert”方法、“u”调用“update”方法等,这些方法会把数据进一步解析,形成elasticsearch可以识别的数据格式,放到本地缓存中;
(5)当本地缓存的数据达到设定的阈值时,以批量的形式把数据发送到elasticsearch,所述阈值可以人为根据实际需要(如缓存空间大小等)设定,容易理解。
在配置文件中会指定本次要同步的数据集合和索引的名称,以及其他各类参数。同步程序启动之后,会根据配置文件中的数据集合和索引,创建一条从mongodb的数据集合到kafka的topic再到elasticsearch的索引的数据通道,特别地,当有多个索引时,会采用多线程并行操作的方式以提高同步速率。
本发明把从mongodb中读取到的数据先缓存到消息队列kafka中,再把kafka的数据同步到elasticsearch中,通过增加缓存机制kafka,改进了原来由于oplog小而数据规模大时而导致的数据丢失问题,保证了数据同步的可靠性。
mongodb的数据集合称与kafka的topic之间的映射,特别的,当从mongodb映射到kafka时,如果topic不存在,还可以自动创建topic,提高了系统的灵活性。从mongodb向kafka中缓存数据时,本发明采用了批量发送的方法,且批量的大小可以根据需求自行设置,提高了数据缓存的速率。
kafka的topic与目标系统elasticsearch的索引之间也会进行映射,一个topic对应一个索引。从kafka向elasticsearch同步数据时,会为每一个topic都创建一个线程,通过使用多线程并行操作,提升数据同步的速率,因此通过topic的使用,使得系统有良好的横向扩展性。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!