一种基于特征迁移和自适应学习的人民调解案例分类系统及方法与流程
本发明涉及数据处理分类
技术领域:
,尤其涉及一种基于特征迁移和自适应学习的人民调解案例分类系统及方法。
背景技术:
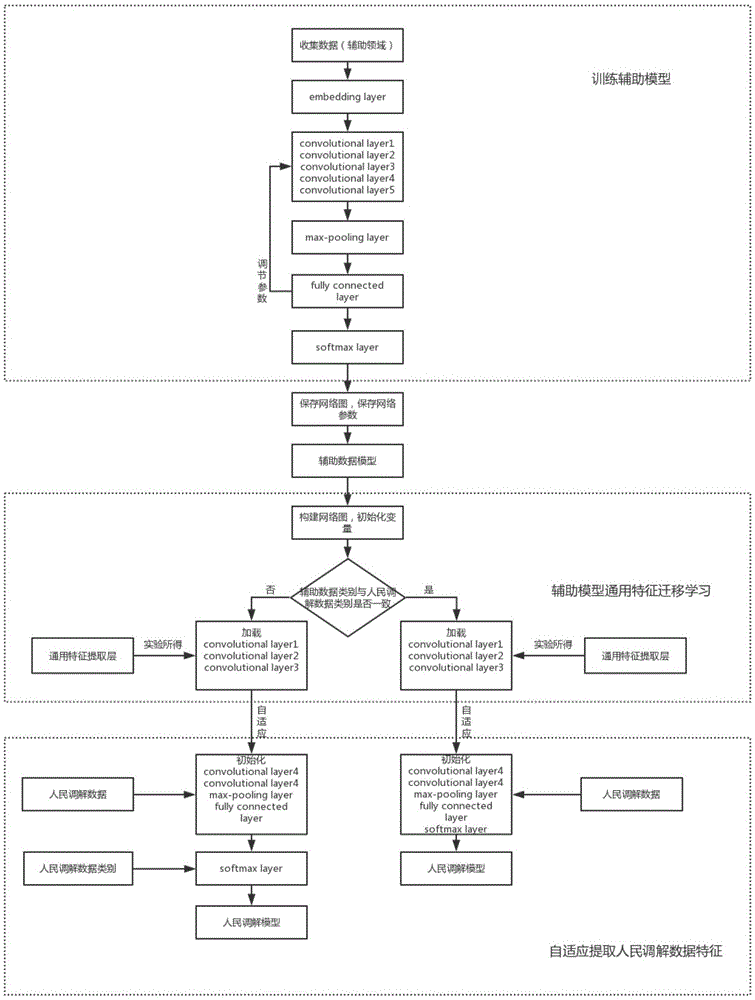
:目前,我国每年调解纠纷900多万件,现有的纠纷类型却只有20多类,随着经济社会的发展,案件的数量增加和案件的类型呈现出多样化,如何快速的将案件进行准确的分类并及时增添新的案件类型,提高调解工作的效率,是人民调解工作面临的严峻问题。当前人民调解案件类型存在以下不足:1、已存的案件类型数目少,无法涵盖所有纠纷;2、不能及时将新增的纠纷类型与已存的纠纷类型区分开;3、现存的纠纷类型下子目未细化,不能准确体现出纠纷要点。人民调解案件类型细分种类繁多,文本分类技术可以帮助人们准确地从海量数据中提取类型特征实现自动分类功能。现有的人民调解数据主要以短文本为主,短文本存在稀疏性、实时性、海量性和不规范性等特点。短文本的这些特点使文本分类面临以下难点:1、短文本特征词少,用传统的基于词条的向量空间模型表示,会造成向量空间的稀疏,另外词频、词共现频率等信息不能得到充分利用,会丢失掉词语间潜在的语义关联关系;2、短文本的不规范性,使文本中出现不规则特征词和分词词典无法识别的未登录词,导致传统文本预处理和文本表示方法不够准确;3、短文本数据的规模巨大,在分类算法的选择上往往更倾向于非惰性的学习方法,惰性的学习方法会造成过高的时间复杂度。随着短文本数据的大量产生,人们针对短文本的分类技术做了大量探索和实践。但在人民调解领域(专业性强的短文本)中该技术的应用仍属空白。专利申请号cn201710686945.7提出了一种组合类降维算法和加权欠采样svm算法相结合的短文本分类方法,解决了文本分类中高纬度稀疏性和类别不平衡的问题,但在多分类准确度上效果不佳。专利申请号cn201510271672.0公开了一种基于卷积神经网络的短文本分类方法,通过预训练的词表示向量对短文本进行语义扩展,利用卷积神经网络提取定长的语义特征向量,使其语义特征向量化表示得到进一步增强,并最终使其分类任务的性能得以改善。但该方法在垂直领域,很难根据外部辅助数据对语料进行扩充。技术实现要素:本发明为克服上述的不足之处,目的在于提供一种基于特征迁移和自适应学习的人民调解案例分类系统及方法,本发明系统包括数据采集模块、特征提取模块、特征迁移模块、网络训练模块,系统结构简单,应用范围广;本发明方法包括构造字符向量表,辅助数据向量化处理,人民调解数据向量化处理,将向量化后的辅助数据输入到神经网络中,提取辅助数据特征,将提取的辅助数据通用特征迁移到新的神经网络中,向量化后的人民调解数据输入到此神经网络中,训练分类模型。本发明方法可以有效的对所有文本进行转换,不会忽略低频词,维度下降明显,训练速度快,便于后续的在线迭代优化;同时解决了人民调解领域与辅助领域之间的差异性,满足了特定领域的个性化需求。本发明是通过以下技术方案达到上述目的:一种基于特征迁移和自适应学习的人民调解案例分类系统,包括:数据采集模块、特征提取模块、特征迁移模块、网络训练模块;所述的数据采集模块用于采集人民调解数据与辅助数据,并对采集得到的人民调解数据与辅助数据进行数据清洗、去重预处理操作,形成辅助数据集和人民调解数据集;特征提取模块,采用卷积神经网络提取辅助数据特征和人民调解数据特征,并对特征进行卷积运算获取人民调解数据特定的特征;特征迁移模块用于将辅助数据通用特征迁移到新的神经网络中,将其应用在人民调解案例分类中;网络训练模块用于对卷积神经网络的训练,获得最终的训练模型。一种基于特征迁移和自适应学习的人民调解案例分类方法,包括如下步骤:(1)收集人民调解数据与辅助数据,并对人民调解数据和辅助数据进行预处理得到辅助数据集a、人民调解数据集b;(2)构造字符向量表,对辅助数据进行向量化处理,将向量化后的辅助数据输入到卷积神经网络中,提取辅助数据特征;同时对卷积神经网络重新训练获得辅助领域模型,并将辅助领域模型的网络结构图保存为.meta文件,网络参数保存为.checkpoint文件;(3)利用迁移学习技术将提取的辅助数据特征迁移到新的神经网络中;其中,该新神经网络为基于辅助领域模型的网络图重建的神经网络,并在该新神经网络中决定自适应层;(4)对人民调解数据进行向量化处理,将向量化后的人民调解数据输入到步骤(3)得到的卷积神经网络中,提取人民调解数据特定的特征,并训练分类器模型,得到并保存最终的人民调解分类模型;采用该人民调解分类模型对人民调解案例进行分类。作为优选,所述步骤(1)具体如下:(1.1)收集辅助数据:收集与领域相关的长文本数据作为辅助领域数据;(1.2)收集人民调解数据:收集近年的人民调解数据,根据专家经验将人民调解数据打上小类标签;(1.3)数据清洗:将收集的辅助数据进行清洗,删除文本中的干扰字符,删除过短的数据;将收集的人民调解数据进行清洗,删除质量差和过短的数据,删除文本中的干扰字符;(1.4)数据去重:基于清洗后的数据,采用余弦夹角算法、欧式距离、jaccard相似度、最长公共子串、编辑距离方法中的任意一种或多种方法删除重复和相似数据;(1.5)将清洗和去重后的数据存入到数据仓库中,获得辅助数据集a、人民调解数据集b。作为优选,所述步骤(2)具体如下:(2.1)构造字符向量表:将辅助数据集a和人民调解数据集b的文本切分成单个字符,每个字符赋予一个id;对字符集构造字符向量表;(2.2)文本嵌入:假设一个文本的字符序列为[s1,s2,s3,…,sn],sn为文本中第n个字符,则根据字符序列和字符向量表构造文本向量为[e1,e2,e3,…,en],其中en对应的是sn的id;利用wordembedding函数给每个字符分配一个固定长度为m的向量表示,辅助数据集a文本嵌入后最终输出文本向量空间i∈r|l|×|n*m|,m为字符向量长度,l为辅助数据集a的总数;(2.3)将输出的文本向量空间i输入到卷积计算层中,其中卷积计算层(共k层);第一层卷积层:利用滤波器对文本矩阵做卷积计算,若滤波器大小为h×m,其中h为卷积核窗口中的字符数量,则卷积操作后输出特征ti为:ti=f(w·si:i+h-1+b)其中b∈r为偏差项,w∈rh×m为卷积核的权重矩阵,f是卷积核函数;该滤波器应用于一个文本{s1:h,s2:h+1,…,sn-h+1}得到特征t为:t=[t1,t2,t3,t4,…,tn-h+1]其中t∈rn-h+1;同理得第k层卷积得到的特征为t'=[t′1,t'2,…,t'n-kh+k];通过max-pooling池化层对特征进行下采样,保留最重要的特征则全连接层的特征向量v为:其中k为卷积核的个数;通过softmax层进行归一化;(2.4)基于辅助数据集a对卷积神经网络重新训练获得辅助领域模型,并将辅助领域模型的网络结构图保存为.meta文件,网络参数保存为.checkpoint文件。作为优选,所述步骤(2.4)在训练过程中,基于交叉熵训练目标函数,即采用的训练目标函数是最小化目标概率分布和实际概率分布的交叉熵,其中训练目标函数j(θ)的定义式为:其中,l是训练样本数目,α是正则化因子,是样本xi的正确类别;基于所述的训练目标函数,通过梯度下降算法计算样本的误差,并使用反馈传播的方式更新网络结构的超参数的集合θ,更新公式为:其中,λ是学习率。作为优选,所述训练得到辅助领域模型的方法为:(i)将辅助数据集a划分为p等份,依次抽取若干等份数据作为训练集,剩下的若干等份数据作为验证集,进行交叉验证,将平均值作为辅助数据集a的准确度,准确度最高的一次训练模型保存下来,作为模型m1;(ii)利用混淆矩阵,错分矩阵记录模型m1预测辅助数据集a类别混淆的数据和每个类别错分的次数,分析后若发现存在数据质量问题则进一步进行半人工清洗数据,清洗后作为数据集d;其中混淆矩阵的每一列代表预测值,每一行代表的是实际的类别;(iii)数据集d根据卷积神经网络重新训练,输出分类结果较好的辅助领域模型。作为优选,所述步骤(3)利用迁移学习技术迁移辅助数据特征的具体步骤如下:(3.1)构造网络图:根据保存的.meta文件重建神经网络,网络层分别为嵌入层embedding,卷积层(共k层),池化层gmp,全连接层fc1、fc2,sofmax层;(3.2)决定自适应层:人民调解数据在辅助领域模型网络层逐层固定的状态下进行迁移学习,依次获得k+3个模型精确度,第一次精确度下降时,神经网络开始人民调解数据自适应学习,故此神经网络的前q层为辅助领域模型的通用特征提取层;(3.3)特征迁移:根据保存的.checkpoint文件初始化参数,将辅助领域模型通用特征层(前q层)迁移到步骤(3.1)重建输出的神经网络中。作为优选,所述在特征迁移过程中,判断辅助数据数据集a与人民调解数据集b的类别数量是否一致:如果两者类别数量一致,则根据保存的.checkpoint文件将模型参数初始化;如果两者类别数量不一致,则根据保存的.checkpoint文件,更新softmax参数,并将模型参数初始化。作为优选,所述步骤(4)具体如下:(4.1)根据字符向量表对人民调解数据集b进行向量化处理,将向量化后的人民调解数据输入到步骤(3)输出的神经网络中,前q层提取了人民调解数据与辅助数据共有特征对共有特征卷积计算得到人民调解数据特征t,初始化q到k+3-q层神经网络权重,提取人民调解数据特定的特征,训练分类器模型;(4.2)反复迭代循环训练网络至损失值不再减小为止,得到并保存最终的人民调解分类模型;,可作为下次迁移学习的辅助领域模型;最后,采用该人民调解分类模型对人民调解案例进行分类。作为优选,所述辅助数据,是指裁判文书数据。本发明的有益效果在于:(1)本发明采用字符级卷积神经网络文本分类方法,能有效的对所有文本进行转换,不会忽略低频词,维度下降明显,训练速度快,便于后续的在线迭代优化;(2)本发明采用迁移学习方法可以将辅助领域数据的通用特征迁移到人民调解数据特征上,解决了短文本特征提取困难的问题,同时提高模型的泛化能力;(3)本发明采用深层卷积神经网络,进行自适应的学习,解决了人民调解领域与辅助领域之间的差异性,满足特定领域的个性化需求;(4)本发明实现的技术方案针对人民调解领域具有一定的灵活性,人民调解纠纷是不断演变的,对于后续出现的新纠纷,本发明能够快速的迁移和应用。附图说明图1是本发明方法的流程示意图;图2是本发明实施例的字符向量表示意图;图3是本发明实施例中给每个字符分配固定长度为m=128的向量表示的结果示意图;图4是本发明采用的的混淆矩阵示例图;图5是本发明迁移学习的的框架流程图。具体实施方式下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:实施例:一种基于特征迁移和自适应学习的人民调解案例分类系统,包括:数据采集模块、特征提取模块、特征迁移模块、网络训练模块;所述的数据采集模块用于采集人民调解数据与辅助数据,并对采集得到的人民调解数据与辅助数据进行数据清洗、去重预处理操作,形成辅助数据集和人民调解数据集;特征提取模块,采用卷积神经网络提取辅助数据特征和人民调解数据特征,并对特征进行卷积运算获取人民调解数据特定的特征;特征迁移模块用于将辅助数据通用特征迁移到新的神经网络中,将其应用在人民调解案例分类中;网络训练模块用于对卷积神经网络的训练,获得最终的训练模型。如图1所示,一种基于特征迁移和自适应学习的人民调解案例分类方法,包括如下步骤:(1)人民调解数据和辅助数据预处理:(1.1)收集辅助数据:收集与领域相关的数据(长文本)作为辅助领域数据;本实施例采集了近10万条的裁判文书数据作为辅助数据,其中裁判文书类型为20类。(1.2)收集人民调解数据:本实施例采集了近3年人民调解案件6万余条,根据专家经验将人民调解案件打上小类标签,小类标签共计88类。(1.3)数据清洗:将收集的辅助领域数据进行清洗,删除文本中的干扰字符,删除过短的数据;将收集的人民调解数据进行清洗,删除质量差和过短的数据,删除文本中的干扰字符。本实施例利用正则表达式删除裁判文书数据中时间、日期、数字、特殊符号(\n,*)等干扰字符,删除裁判文书数据中内容小于30字符的数据;利用专家判断删除人民调解案件类型不明确的数据,利用正则表达式删除人民调解数据中时间、日期、身份证号、地址、联系电话、银行卡号等干扰字符,删除人民调解数据中内容小于15字符的数据。(1.4)数据去重:根据步骤(1.3)清洗后的数据,可用余弦夹角算法、欧式距离、jaccard相似度、最长公共子串、编辑距离等方法删除重复和相似的数据,本实施例采用jaccard相似度算法删除裁判文书中相似系数大于0.8的数据,以及人民调解案件中相似系数大于0.9的数据。(1.5)将清洗和去重后的数据存入到数据仓库中,获得裁判文书数据集a与人民调解数据集b。(2)利用卷积神经网络提取辅助领域特征:(2.1)构造字符向量表:将裁判文书数据集a和人民调解数据集b的句子切分成单个字符,字符去重复,一行一个字符保存在vocab.txt文件,行号就是每个字符的id;在本实施例中,c=5000为数据中所用的字符集(包括不在字符向量表里的未知字符<pad>填充),构造一个字符向量表如图2所示:(2.2)文本嵌入:在本实施例中,将每条数据固定长度设为300,大于300的数据会被截断,小于300的数据填充统一的字符<pad>。假设一个文本的字符序列为[s1,s2,s3,…,sn](0≤n≤300),sn为文本中第n个字符,则根据字符序列和字符向量表构造文本向量为[e1,e2,e3,…,en],其中en对应的是sn的id,利用wordembedding矩阵给每个字符分配一个固定长度为m=128的向量表示,如图3所示,则文本向量空间为s∈r300×128。以此类推,对于裁判文书数据集a文本嵌入最终输出文本向量空间i∈r|l|×|300*128|,l为裁判文书数据集a的总数。(2.3)本发明所使用的网络结构如下表1所示:名称embeddingfilterkernelsizehidden_dimoutsizeembedding128[300×128]conv12563×128128[298×1×256]conv22563×128128[296×1×256]conv32563×128128[294×1×256]conv42563×128128[292×1×256]conv52563×128128[290×1×256]maxpool[256×1]dropout[256×1]fc[20×1]或[88×1]softmax[20×1]或[88×1]表1根据步骤(2.2)输出的文本向量空间i通过卷积计算层(共k层)进行卷积计算,第一层卷积层:利用滤波器对文本矩阵做卷积计算,若滤波器大小为h×m,其中h为卷积核窗口中的字符数量,则卷积操作后输出特征ti为:ti=f(w·si:i+h-1+b)其中b∈r为偏差项,w∈rh×m为卷积核的权重矩阵,f是卷积核函数;该滤波器应用于一个文本{s1:h,s2:h+1,…,sn-h+1}得到特征t为:t=[t1,t2,t3,t4,…,tn-h+1]其中t∈rn-h+1;同理得第k层卷积层得到的特征通过max-pooling池化层对特征进行下采样,保留最重要的特征则全连接层的特征向量v为:其中k为卷积核的个数;通过softmax层进行归一化,softmax函数形式如下:其中,xi是所述输入短文本,zj是第j个类别,θ是所述卷积神经网络中需要估计的超参数集合,z是训练样本预定义的类别集合,∮j(xi,θ)是所述网络结构对样本xi在类别zj上的评分,即通过多类逻辑斯特回归分类器将所述评分映射为关于所有预定义类别的概率分布向量,该概率向量的维度与所述预定义的类别集合大小一致。本实施例经过多轮测试,当卷积层数为五层、卷积核窗口中的字符数量h=3时效果最佳,生成特征t'为:t'=[t′1,t'2,…,t'290]其中,t'∈r290;使用max-pooling池化层从每个向量中取出最大值,最大值代表着最重要的信号,这种pooling方式可以解决可变长度的句子输入问题,最终池化层的输出为卷积计算层中的最大值。为了防止梯度消失,本实施例在全连接第一层引入relu激活函数,经过测试,relu得到的sgd的收敛速度会比sigmoid/tanh快很多,它的数学表达式如下所示:f(x)=1(x<0)(ax)+1(x>=0)(x)其中a是一个很小的常数。这样既修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失;同时为了防止模型过拟合,本实施例引入dropout技术,经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,0.5的时候dropout随机生成的网络结构最多。在全连接第二层使用softmax进行归一化,显示裁判文书在20类上的概率分布。(2.4)基于辅助数据集a对卷积神经网络重新训练获得辅助领域模型,并将辅助领域模型的网络结构图保存为.meta文件,网络参数保存为.checkpoint文件。在循环迭代训练过程中,本实施例采用的训练目标函数是最小化目标概率分布和实际概率分布的交叉熵,训练目标函数j(θ)的定义式为:其中,l是训练样本数目,α是正则化因子,是样本xi的正确类别。基于所述训练目标函数,通过梯度下降算法计算批量样本的误差,并使用反馈传播(backpropagation,bp)的方式更新所述网络结构的超参数的集合θ,具体的更新公式为:其中,λ是学习率,本实施例中经过测试当α=0.3,λ=1×e-3时效果最佳。(2.5)将裁判文书数据集a划分10等份,依次抽取9等份数据作为训练集,1等份数据作为验证集,进行交叉验证,将平均值作为裁判文书数据集a的准确度,准确度最高的一次训练模型保存下来,作为模型m1。(2.6)利用混淆矩阵(矩阵的每一列代表预测值,每一行代表的是实际的类别),错分矩阵记录模型m1预测裁判文书数据集a类别混淆的数据和每个类别错分的次数,分析后发现存在数据质量问题(如:裁判文书类别标注错误,裁判文书类别不明确),进一步进行半人工清洗数据作为裁判文书数据集d,混淆矩阵如图4所示。(2.7)数据集d根据卷积神经网络重新训练,输出分类结果较好(准确度大于90%)的裁判文书模型,此模型作为辅助领域模型m2。(2.8)将模型m2的网络图保存为my_model.meta,网络参数保存为my_model.checkpoint。(3)利用迁移学习技术,将辅助数据通用特征应用在人民调解案例分类中,流程如图5所示:(3.1)构造网络图:根据保存的my_model.meta文件,重建神经网络(与裁判文书数据神经网络结构相同),网络层分别为嵌入层embedding,卷积层conv1、conv2、conv3、conv4、conv5,池化层gmp,全连接层fc1、fc2,sofmax层。(3.2)决定自适应层:人民调解数据在辅助模型网络层逐层固定的状态下,进行迁移学习,依次获得8个模型精确度,第一次精确度下降时,网络开始了人民调解数据自适应学习,故此网络的前q层为辅助模型的通用特征提取层。在本实施例中,对模型m2的conv1,conv2,conv3,conv4,conv5,gmp,fc1,fc2逐层进行微调实验,得出前三层模型m2学习到的是通用的特征,随着网络层次的加深,后面的网络更偏重于裁判文书领域的特征,即本实施例将模型m2参数conv1,conv2,conv3迁移到此神经网络中,conv4,conv5,gmp,fc1,fc2,softmax初始化不加载。(3.3)判断裁判文书数据集a与人民调解数据集b的类别数量是否一致:如果两者类别数量一致,则执行步骤(3.4);如果两者类别数量不一致,则执行步骤(3.5)。(3,4)根据步骤(2.4)保存的.checkpoint文件将模型参数初始化,将模型m2参数conv1,conv2,conv3迁移到此神经网络中,conv4,conv5,gmp,fc1,fc2,softmax初始化不加载。(3.5)根据步骤(2.4)保存的.checkpoint文件,更新softmax参数,模型参数初始化,将模型m2参数conv1,conv2,conv3迁移到此神经网络中,conv4,conv5,gmp,fc1,fc2,softmax初始化不加载。(4)利用卷积神经网络特征提取的能力进行自适应学习:(4.1)根据步骤(2.1)、步骤(2.2)输出的字符向量表对人民调解数据集b进行向量化处理,将向量化后的人民调解数据输入到步骤(3)输出的神经网络中,前三层提取了人民调解数据与裁判文书数据共有特征将共有特征经过2层卷积层(conv4、conv5)进行卷积计算,得到人民调解数据特征t,特征t经过max-pooling池化层提取显著特征,通过全连接层获取最终的人民调解数据特定的特征,训练分类器模型。(4.2)反复迭代循环训练网络至损失值不再减小为止,保存人民调解分类模型,作为下次迁移学习的辅助领域模型。由于本实施例裁判文书类型数量与人民调解类型数量不一致,故更新softmax参数(人民调解细分类型数class=88),恢复模型m2中前三层卷积核的权重矩阵,根据步骤(2.1)、步骤(2.2)输出的字符向量表对人民调解数据集b进行向量化处理,将向量化后的人民调解数据输入到此卷积神经网络中,提取人民调解数据的特征,训练分类模型,保存人民调解分类模型m3;采用该人民调解分类模型对人民调解案例进行分类。在人民调解信息化推广应用的过程中,会存在以下两种情况:1、人民调解的数据会越来越多,同时短时间内,纠纷类型不会发生变化;此时将模型m3的通用特征提取层迁移到新人民调解数据中,提高分类的准确度。2、人民调解信息化应用越趋成熟,人民调解的数据会越来越多,同时可能会出现新的纠纷类型;此时将模型m3的通用特征提取层迁移到新人民调解数据中,更新softmax参数(新人民调解类型数量),避免从头开始训练。以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1