基于API调用序列的安卓恶意软件检测方法与流程
本发明属于计算机
技术领域:
,更进一步涉及互联网网络
技术领域:
中的一种基于应用程序编程接口api(applicationinterface)调用序列的安卓恶意软件检测方法。本发明可利用安卓应用软件的应用软件编程接口api调用序列,来判断安卓应用软件是否为恶意软件,用于对安卓应用软件的安全分析。
背景技术:
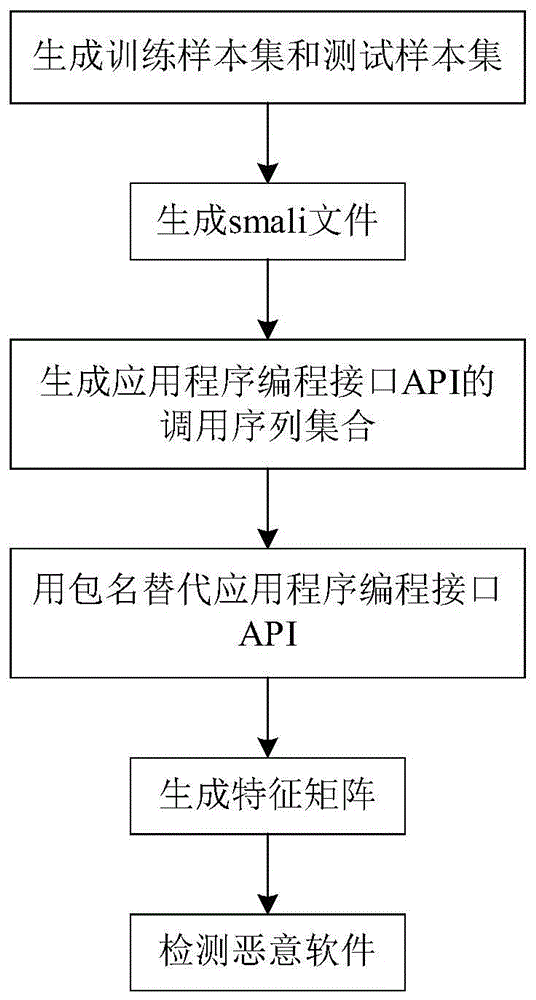
:安卓恶意软件静态检测的研究源于移动终端应用安全的研究工作,其特点是利用安卓应用软件文件中权限信息和应用程序编程接口api信息,分析权限的变化和应用程序编程接口api之间的调用关系,进行分类特征的提取并通过机器学习来对恶意软件的识别。目前,已有的安卓恶意软件静态检测的方法基本是从权限和应用程序编程接口api两方面进行展开的,而这种方法存在以下不足:第一,由于api数量多,包含安卓官方提供的api、第三方组织提供的api和自定义api,导致依赖api特征的分类算法计算量较大;第二,随着安卓安全技术的不断提高,安卓应用软件均通过代码混淆技术来防止安卓应用软件被反编译,这样就导致对混淆后的安卓应用软件分析变得困难;第三,目前现有的安卓恶意软件静态检测方法无法适应api版本的更替,会随着api版本的更改,导致检测效率降低。邵舒迪,虞慧群,范贵生在其发表的论文“基于权限和api特征结合的android恶意软件检测方法”(计算机科学,2017,44(4),135-139)中提出一种基于权限和api特征结合的安卓恶意软件检测方法。该方法主要是提取被混淆后的安卓应用软件中的权限和高危的20种api集合作为特征,然后将权限特征和api特征相结合,形成新的api-权限特征集合,最后结合分类算法来区分恶意软件。该方法存在的不足之处是,在被混淆后的安卓应用软件中,对于采用20种高危api会被混淆后的名字替代,从而该方法会漏掉这一关键特征,导致检测效率低。chens,xuem,tangz在其发表的论文“stormdroid:astreaminglizedmachinelearning-basedsystemfordetectingandroidmalware”(ccs会议论文,2016)中提出一种基于机器学习的安卓恶意软件检测方法。该方法从良性样本集合和恶意样本集合中提取了多项特征数据,包括通过静态检测方法获取的权限、不同api版本中的api调用信息和通过动态检测方法获取的日志文件作为总体特征。该方法存在的不足之处是,该方法的检测模型的质量依赖于样本集合中样本所属api版本,并且该方法计算量较大,使得恶意软件识别过程开销增大,识别率低。博雅网信(北京)科技有限公司在其申请的专利文献“一种基于权限组合的安卓恶意软件检测方法”(专利申请号201610064024.2,公开号cn105740709a)中公开了一种基于权限组合的安卓恶意软件检测方法。该方法对安卓应用软件中的权限信息进行权限分类组合并获得权限组合的评分,根据权限组合的评分获得评分临界值,将实际待检测安卓软件的评分与临界值进行比较,判断待检测安卓软件是否为恶意软件。该方法存在的不足之处是,该检测方法容易出现误差,比如由于缺乏经验的开发者可能事先申请了某些权限,但其在编程中却没有用到被该权限作用的函数,因此准确率和遗漏问题很严重。技术实现要素:本发明的目的是针对上述现有技术的不足,提出一种基于api调用序列的安卓恶意软件检测方法,以实现安卓应用软件中恶意软件的识别。实现本发明目的的思路是:首先收集多个已知的安卓恶意应用软件和已知的安卓正常应用软件,组成训练样本集;再利用反编译工具对训练样本集中的每个安卓应用软件进行反编译,提取smali文件;其次分析smali文件,获取多个应用程序编程接口api调用序列,组成应用程序编程接口api调用序列集合;再利用基础包名、混淆包名和自定义包名来替代应用程序编程接口api;接着计算调用序列集合中每个api调用序列中应用程序编程接口api两两组合概率,所有的组合概率组成特征矩阵;再将训练样本集中的所有特征矩阵输入到随机森林分类器中训练;最后将待检测样本经过相同步骤后提取特征矩阵,再将特征矩阵输入到训练好的随机森林分类器中进行恶意软件检测。实现本发明目的的具体步骤如下:(1)生成训练样本集和测试样本集:(1a)从应用软件库中提取已知的1600个安卓恶意应用软件和已知的2400个安卓正常应用软件,组成训练样本集;(1b)将700个待检测的安卓应用软件,组成测试样本集;(2)生成smali文件;(2a)利用安卓反编译工具,对训练样本集中每个安卓应用软件进行反编译,得到每个安卓应用软件对应的smali文件;(3)生成应用程序编程接口api的调用序列集合:(3a)利用深度优先遍历算法dfs,生成每个smali文件中所有应用程序编程接口api组成的调用序列;(3b)将所有smali文件的调用序列存入到调用序列集合中;(4)用包名替代应用程序编程接口api:(4a)从调用序列集合中任意选择一个未选过的调用序列;(4b)从调用序列中任意选择一个未选过的应用程序编程接口api;(4c)判断基础包名集合中是否有所选的应用程序编程接口api的包名,若有,则用该基础包名替代应用程序编程接口api后存入到调用序列集合中,执行步骤(4b),否则,执行步骤(4d);(4d)对符合反域名命名规则的包名,以字符串“insensitive-defined”替代应用程序编程接口api后存入到调用序列集合中,其余的用字符串“obfuscated”替代应用程序编程接口api后存入到调用序列集合中;(4e)判断是否选完调用序列中的所有应用程序编程接口api,若是,执行步骤(4f),否则,执行步骤(4b);(4f)判断是否选择完调用序列集合中的所有调用序列,若是,执行步骤(5),否则,执行步骤(4a);(5)生成特征矩阵:(5a)构建一个n行m列的特征矩阵,其中n表示调用序列的总数,m表示在基础包名、混淆包名和自定义包名中两两组合的总数;(5b)从调用序列集合中任意选择一个未选过的调用序列;(5c)按照下式,计算所选的调用序列中两两组合中的应用程序编程接口api的包名的组合概率,将组合概率存入特征矩阵中:其中,pkij表示所选的第k个调用序列中两两组合中的第i个应用程序编程接口api的包名,与第j个应用程序编程接口api的包名的组合概率,cij表示所选的第k个调用序列中两两组合中的第i个应用程序编程接口api的包名,与第j个应用程序接口api的包名的组合个数,∑表示求和操作,t表示所选的调用序列中应用程序编程接口api的总数;(5d)判断是否选择完调用序列集合中的所有调用序列,若是,执行步骤(6),否则,执行步骤(5b);(6)检测恶意软件:(6a)将训练样本集中的安卓恶意应用软件的特征矩阵和安卓正常应用软件的特征矩阵,输入到随机森林分类器randomforest中,对随机森林分类器训练;(6b)将测试样本集中的待检测的安卓应用软件进行反编译,分别生成smali文件、应用程序编程接口api的调用序列集合、以包名表示的应用程序编程接口api、特征矩阵;(6c)将待检测的安卓应用软件的特征矩阵,输入到训练好的随机森林分类器randomforest中,对每个测试样本进行分类,输出所属类别的预测值;(6d)将预测值为1的待检测的安卓应用软件判定为恶意应用软件,预测值为0的待检测的安卓应用软件判定为正常应用软件。本发明与现有技术相比有以下优点:第一,本发明利用基础包名、混淆包名和自定义包名来替代不同api版本的应用程序编程接口api,极大减少了应用程序编程接口api种类,克服了现有技术中使用的应用程序编程接口api种类过多、计算量较大和提取的特征无法适应应用程序编程接口api版本的更替,导致恶意软件识别过程开销增大、识别率低的问题,使本发明具有计算复杂度低、提高恶意软件识别检测效率的优点。第二,本发明通过反域名命名规则识别应用程序编程接口api自定义包名和混淆包名,克服了现有技术中无法识别混淆后的应用程序编程接口api包名,导致检测准确度低的缺点,使本发明具有能有效识别应用程序编程接口api包名的优点。附图说明图1为本发明的流程图。具体实施方式下面结合附图1对发明的具体步骤描述如下。步骤1,生成训练样本集和测试样本集。从应用软件库中提取已知的1600个安卓恶意应用软件和已知的2400个安卓正常应用软件,组成训练样本集。将700个待检测的安卓应用软件,组成测试样本集。步骤2,生成smali文件。利用安卓反编译工具,对训练样本集中每个安卓应用软件进行反编译,得到每个安卓应用软件对应的smali文件。步骤3,生成应用程序编程接口api的调用序列集合。利用深度优先遍历算法dfs,生成每个smali文件中所有应用程序编程接口api组成的调用序列。所述的深度优先遍历算法dfs的具体步骤如下。第1步,创建一个空集。第2步,将smali文件中所有的应用程序编程接口api信息,存入到应用程序编程接口api集合中。第3步,从应用程序编程接口api集合中选择一个未选择的应用程序编程接口api信息。第4步,判断所选应用程序编程接口api信息中是否包含关键字invoke,若包含,则执行第五步,否则,执行第六步。第5步,将包含关键字invoke的应用程序编程接口api与关键字invoke所调用的应用程序编程接口api都存入到空集中。第6步,将应用程序编程接口api存入到空集。第7步,重复第3步,直到选择完应用程序编程接口api集合中的所有应用程序编程接口api信息。将所有smali文件的调用序列存入到调用序列集合中。步骤4,采用包名替代以字符串表示的应用程序编程接口api。(4.1)从调用序列集合中任意选择一个未选过的调用序列。(4.2)从调用序列中任意选择一个未选过的应用程序编程接口api。(4.3)判断基础包名集合中是否有所选的应用程序编程接口api的包名,若有,则用该基础包名替代应用程序编程接口api后存入到调用序列集合中,执行本步骤的(4.2),否则,执行本步骤的(4.4)。所述的基础包名集合中包括的基础包名有9个,分别为android、com.google、java、javax、org.xml、org.apache、junit、org.json和org.w3c.dom。(4.4)对符合反域名命名规则的包名,以字符串“insensitive-defined”替代应用程序编程接口api后存入到调用序列集合中,其他的用字符串“obfuscated”替代应用程序编程接口api后存入到调用序列集合中。(4.5)判断是否选完调用序列中的所有应用程序编程接口api,若是,执行本步骤的(4.6),否则,执行本步骤的(4.2)。(4.6)判断是否选择完调用序列集合中的所有调用序列,若是,执行本步骤的(5),否则,执行本步骤的(4.1)。步骤5,生成特征矩阵。(5.1)构建一个n行m列的特征矩阵,其中n表示调用序列的总数,m表示在基础包名、混淆包名和自定义包名中两两组合的总数。(5.2)从调用序列集合中任意选择一个未选过的调用序列。(5.3)按照下式,计算所选的调用序列中两两组合中的应用程序编程接口api的包名的组合概率,将组合概率存入特征矩阵中。其中,pkij表示所选的第k个调用序列中两两组合中的第i个应用程序编程接口api的包名,与第j个应用程序编程接口api的包名的组合概率,cij表示所选的第k个调用序列中两两组合中的第i个应用程序编程接口api的包名,与第j个应用程序接口api的包名的组合个数,∑表示求和操作,t表示所选的调用序列中应用程序编程接口api的总数。(5.4)判断是否选择完调用序列集合中的所有调用序列,若是,执行本步骤的(6),否则,执行本步骤的(5.2)。步骤6,检测恶意软件。将训练样本集中的安卓恶意应用软件的特征矩阵和安卓正常应用软件的特征矩阵输入到随机森林分类器randomforest中,对随机森林分类器训练。将测试样本集中的待检测的安卓应用软件进行反编译,分别生成smali文件、应用程序编程接口api的调用序列集合、以包名表示的应用程序编程接口api和特征矩阵。将待检测的安卓应用软件的特征矩阵,输入到训练好的随机森林分类器randomforest中,对每个测试样本进行分类,输出所属类别的预测值。将预测值为1的待检测的安卓应用软件判定为恶意应用软件,预测值为0的待检测的安卓应用软件判定为正常应用软件。下面结合仿真实验对本发明的效果做进一步的描述。1、仿真条件:本发明仿真实验的硬件测试平台是:cpu为intel(r)core(tm)i7-7800x,主频为2.7ghz,内存8gb,gpu为nvidiatitanxp;软件平台是:windows10操作系统;编程语言:python2.7.132.仿真内容与结果分析:本发明的仿真实验所使用的安卓正常应用软件是从2018年各大应用市场下载api版本在16~27之间的安卓正常应用软件,总共3000个。其中,前1500个api版本均在24~27之间,这些版本是目前市场上多数使用的api版本。后1500个api版本均在16~23之间,这些版本是比较老的api版本,但依旧占据小部分市场。同时,上述安卓正常应用软件集都是通过杀毒软件的过滤筛除后得到的。本发明仿真实验中的安卓恶意应用软件集来自于virusshare.com网站中提供的2000个恶意软件。同时,为了更好的训练分类器和获取更好的分类结果,本次仿真实验中训练样本集与测试样本集的比例为8:2。表1给出了本次仿真实验数据的具体划分情况。表1实验训练样本集与测试样本集划分一览表api版本16~23api版本24~27训练样本集28002800测试样本集700700利用本发明的方法,提取训练样本集中每个样本的特征矩阵,输入到随机森林分类器中进行训练。同样,利用本发明的方法,提取测试样本集中每个样本的特征矩阵,输入到训练好的随机森林分类器中进行恶意软件检测。在仿真实验中,不同api版本的测试样本集的待检测样本的检测结果如表2所示。表2不同api版本的测试样本集的检测结果一览表api版本16~23api版本24~27正常样例的总数300300恶意样例的总数400400正常样例被正确分类的个数277276恶意样例被正常分类的个数376375恶意样例被错误划分为正常样例的个数2425正常样例的总数300300为了评价本发明方法的有效性,仿真实验对所有的待测样本的检测结果使用六个评价指标来进行评估,分别为tpr、fpr、accuracy、precision和recall。按照下式,计算正常样例被正确分类的比率:其中,tpr表示正常样例被正确分类的比率,tp表示正常样例被正确分类的个数,p表示正常样例的总数。按照下式,计算恶意样例被错误分类的比率:其中fpr表示恶意样例被错误分类的比率,fp表示恶意样例被错误划分为正常样例的个数,n表示恶意样例的总数。按照下式,计算准确率:其中accuracy表示准确率,tn表示恶意样例被正常分类的个数。按照下式,计算正常样本正常分类的个数占所有被正常分类总样本个数的比率:其中precision表示正常样本正常分类的个数占所有被正常分类总样本个数的比率。按照下式,计算正常样本被正常分类的个数占总正常样本的个数的比率:其中recall表示正常样本被正常分类的个数占总正常样本的个数的比率。按照下式,计算平均precision和recall指标后的综合评测标准:其中f-measure表示平均precision和recall指标后的综合评测标准。使用上述的六个评价指标,对不同api版本的测试样本集中所有的待测样本的检测结果进行详细评估。评估结果如表3所示。表3不同api版本的测试样本集在randomforest指标一览表api版本16~23api版本24~27tpr(%)92.392fpr(%)66.2accuracy(%)93.192.9precision(%)93.893.6.recall(%)92.392f-measure(%)93.192.8从表3中可见,应用程序编程接口api版本在16~23的f-measure和在24~27的f-measure都是93%。应用程序编程接口api版本在16~23和24~27的tpr、fpr的差距都控制在0.2%,表明本发明的方法能有效的区分恶意样本且不受api版本的影响。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1