一种基于生成对抗学习的多维度田间杂草识别方法与流程
本发明属于人工智能技术领域,涉及一种基于生成对抗学习的多维度田间杂草识别的方法。
背景技术:
杂草的存在对田间作物的产量构成了威胁,而传统的无差别化学除草方法给环境和食品安全带来了隐患,因此,如何能够精准靶向的区分杂草成为精准化除草的关键技术。
基于计算机视觉的目标识别方法,因其无损、快速、自动化等特点已经成为目标识别的首选方法,然而当该类方法应用于田间杂草领域,通常会遇到两大难题:1)数据标签不足,相较于传统视觉场景,现存标注的田间杂草的数据集较少,对其进行标注需要耗费大量的人力物力财力。milioto,a.,lottes,p.,&stachniss,c..(2017).real-timeblob-wisesugarbeetsvsweedsclassificationformonitoringfieldsusingconvolutionalneuralnetworks使用仿射变换、尺度变换和随机裁剪等几何变换方法对图片数据进行扩充,然而该类方法一方面因其变换后的数据过于类似对算法性能提升有限,另一方面,扩充后的图片数据大小相同,对后续的分割模型限制较大,影响最终的识别结果。2)识别模型性能不佳,相较于传统视觉场景,杂草与作物在颜色纹理上相似度较高,perez-ortiz,m.,pen~a,j.m.,gutierrez,p.a.,torres-sa′nchez,j.,herva′s-mart′1nez,c.andlo′pez-granados,f.,2016.selectingpatternsandfeaturesforbetween-andwithin-crop-rowweedmappingusinguav-imagery.expertsystemswithapplications47,pp.85–94.通过像素向量的统计信息区分杂草和作物,但因统计信息需要手动设置,在不同的数据集上表现各有差异。milioto,a.,lottes,p.,&stachniss,c..(2017).real-timeblob-wisesugarbeetsvsweedsclassificationformonitoringfieldsusingconvolutionalneuralnetworks.通过构建cnn对田间作物进行识别,然而cnn要求图片数据大小相同,适用范围过窄。
技术实现要素:
本发明的目的在于提供一种基于生成对抗学习的多维度田间杂草识别的方法,以克服现有技术的不足。
为达到上述目的,本发明采用如下技术方案:
一种基于生成对抗学习的多维度田间杂草识别方法,采用半监督学习策略训练总体网络,使用生成对抗学习寻找无标签数据的置信区域,通过自我学习得到最终的田间杂草识结果。
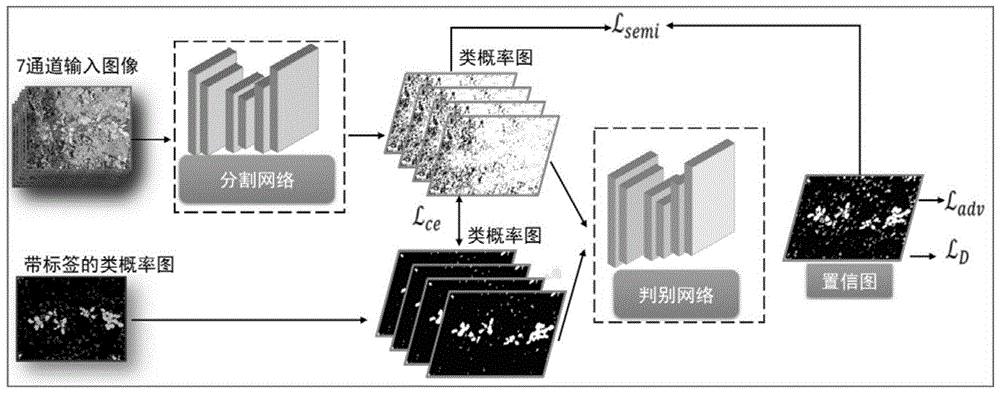
进一步的,总体网络包括分割网络和判别网络,分割网络为任意的深度分割网络,以多通道的图像作为分割网络的输入,分割网络输出为类概率图;判别网络输入为分割网络输出的类概率图,类概率图包括带标签的类概率图和分割网络输出的类概率图,判别网络输出为空间概率图。
进一步的,采用带标签数据和无标签数据输入对总体网络进行训练,使用带标签数据对总体网络进行训练时,分割网络的目标为最小化真实标签图的标准交叉熵和对抗的联合损失,判别网络的目标是最小化空间概率图的交叉熵;在使用无标签数据对网络进行训练时,分割网络的目标为最小化真实标签图的标准交叉熵、对抗网络和半监督损失组成的联合损失,完成对总体网络的训练。
进一步的,半监督损失的计算依托于置信图,置信图即使用无标签数据产生的空间概率图,用于反映预测结果与真实数据分布的相似度。
进一步的,具体包括以下步骤:
假设输入图像xn的图像大小为h×w×l,其中h,w分别为图像的高与宽,l为输入图像的通道;分割网络为s(·),其输出为大小h×w×c的类概率图s(xn),其中c为类别个数;判别网络为d(·),其输出大小h×w×1的二类置信图d(pn),其中pn是大小为h×w×c的类概率图,类概率图为真实的标签yn或分割网络的输出s(xn)。
1)、采集输入图片数据,将输入图片数据进行降噪处理,得到处理后的图片数据;将处理后的图片数据划分为训练集ttrain和测试集ttest,其中ttrain包括带标签数据集ttrain-label和无标签数据集ttrain-no-label;
2)、采用式(a)对训练集ttrain图片数据进行计算,得到ig,ir,ib,inir,iexg,iexr,icive,indi七个通道特征,得到大小为h×w×l(l=7)的输入图像xn;
iexg=2ig-ir-ib
iexr=1.4ir-ig
icive=0.881ig-0.441ir-0.385ib-18.8745
其中ig,ir,ib,inir,iexg,iexr,icive,indi分别为图像的g通道矩阵,r通道矩阵,b通道矩阵,近红外矩阵,过绿因子矩阵,过红因子矩阵,植被提取颜色指数矩阵和归一化指数矩阵。
3)、将得到的输入图像xn输入到总体网络进行联合训练,当联合训练迭代次数大于最大迭代次数loopmax时,训练停止并保存训练模型mseg-adv;
4)、将测试集ttest通过步骤1)步骤2)进行处理得到测试输入数据
进一步的,联合训练过程:首先,保持判别网络不变,使用随机梯度优化分割网络的目标函数;然后保持分割网络不变,使用随机梯度优化判别网络的目标函数;重复交替对判别网络和分割网络进行迭代训练,完成对总体网络的联合训练。
进一步的,对于总体网络的训练,包括判别网络的训练和分割网络的训练:
对于判别网络的训练,其优化目标为最小化如式(b)所示的损失ld:
其中yn=0,是指该数据来自分割网络,yn=1,是指该数据来自真实标签;分割网络的输入为c通道的类概率图;对于真实标签yn,使用one-hot编码方式构建概率图pn,其中
对于分割网络的训练,其优化目标(c)为:
lseg=lce+λadvladv+λsemilsemi(i)
其中lce,ladv和lsemi分别空间多类交叉熵损失,对抗损失和半监督损失;λadv和λsemi分别为权重的参数;
对于ttrain-label,分割网络得到的预测结果为pn=s(xn),交叉熵通过公式(d)得到:
ladv通过公式(e)得到:
对于对抗损失,通过最优化分割网络得到的分割结果作为判别网络的输入;
对于ttrain-no-label,使用半监督学习策略进行网络训练,给定输入数据,判别网络产生置信图d(pn)(h,w,1)。
进一步的,对置信图采用二值化后得到可信的区域,该置信区域作为带标签数据对整个网络进行监督自学习:
其中i(·)为指示函数,
与现有技术相比,本发明具有以下有益的技术效果:
本发明一种基于生成对抗学习的多维度田间杂草识别方法,采用半监督学习策略训练总体网络,使用生成对抗学习寻找无标签数据的置信区域,通过自我学习得到最终的田间杂草识结果,使用置信图对网络进行自学习,采用半监督学习策略,可以突破带标签数据不足的限制;本发明使用分割网络替代传统的传统网络,可接受不同大小的输入特征,灵活性强。
进一步的,采用带标签数据和无标签数据输入对总体网络进行训练,在使用带标签数据对网络进行训练时,分割网络的目标为最小化真实标签图的标准交叉熵和对抗的联合损失,判别网络的目标是最小化空间概率图的交叉熵,利用标签数据作为判别网络的输入;在使用无标签数据对网络进行训练时,分割网络的目标为最小化真实标签图的标准交叉熵、对抗网络和半监督损失组成的联合损失,用无监督数据产生的空间概率图作为半监督损失的计算,可以有效的反映出预测结果与真实数据分布的相似度。
进一步的,对输入图片数据进行降噪处理分为训练集和测试集,利用训练集中的带标签数据和无标签数据对总体网络进行联合训练,通过判别网络和分割网络进行重复交替迭代训练,从而提高总体网络的训练精度。
附图说明
图1是本发明的总体网络架构图。
具体实施方式
如图1所示,本发明提供一种基于生成对抗学习的多维度田间杂草识别方法,采用半监督学习策略,使用生成对抗学习寻找无标签数据的置信区域,通过自我学习得到最终的田间杂草识结果。
本发明设计的总体网络共包括两个网络:分割网络和判别网络;分割网络可以为任意的深度分割网络,如图1所示,本发明以多通道的图像作为分割网络的输入,输出为类概率图;判别网络输入为上述的类概率图,类概率图既可以为带标签的类概率图,又可以为分割网络输出的类概率图,判别网络输出为空间概率图,空间概率图中的像素值代表该像素是来自真实标签(p=1)或来自分割网络(p=0);
半监督学习策略指的是同时采用带标签数据和无标签数据输入对总体网络进行监督学习的方法,在训练阶段,使用半监督策略对总体网络进行训练,输入数据同时包含带标签数据和无标签数据,在使用带标签数据对总体网络进行训练时,分割网络的目标为最小化真实标签图的标准交叉熵和对抗的联合损失,判别网络的目标是最小化空间概率图的交叉熵,因为判别网络需要使用带标签进行计算,所以其输入只能来源于带标签数据;在使用无标签数据对网络进行训练时,分割网络的目标为最小化真实标签图的标准交叉熵、对抗网络和半监督损失组成的联合损失;半监督损失的计算依托于置信图,置信图特指使用无标签数据产生的空间概率图,可以有效的反映出预测结果与真实数据分布的相似度。带标签数据指标准处理图片对照组,用于对总体网络训练;无标签数据指原始图片,作为测试总体网络对照图片;真实标签指分割后的参照图,能够反映凸显分布的真实数据。
本发明所采用的技术方案是:为了清晰的表达,特对技术方案中涉及的相关变量进行说明。
假设输入图像xn的图像大小为h×w×l,其中h,w分别为图像的高与宽,l为输入图像的通道;分割网络为s(·),其输出为大小h×w×c的类概率图s(xn),其中c为类别个数;判别网络为d(·),其输出大小h×w×1的二类置信图d(pn),其中pn是大小为h×w×c的类概率图,类概率图为真实的标签yn或分割网络的输出s(xn)。
1)、采集输入图片数据,将输入图片数据进行降噪处理,得到处理后的图片数据;将处理后的图片数据划分为训练集ttrain和测试集ttest,其中ttrain包括带标签数据集ttrain-label和无标签数据集ttrain-no-label;
2)、采用式(a)对训练集ttrain图片数据进行计算,得到ig,ir,ib,inir,iexg,iexr,icive,indi七个通道特征,得到大小为h×w×l(l=7)的输入图像xn;
iexg=2ig-ir-ib
iexr=1.4ir-ig
icive=0.881ig-0.441ir-0.385ib-18.8745
其中ig,ir,ib,inir,iexg,iexr,icive,indi分别为图像的g通道矩阵,r通道矩阵,b通道矩阵,近红外矩阵,过绿因子矩阵,过红因子矩阵,植被提取颜色指数矩阵和归一化指数矩阵。
3)、将得到的输入图像xn输入到总体网络进行联合训练,当联合训练迭代次数大于最大迭代次数loopmax时,训练停止并保存训练模型mseg-adv;loopmax大于2万次;具体的,联合训练过程:首先,保持判别网络不变,使用随机梯度优化分割网络的目标函数;然后保持分割网络不变,使用随机梯度优化判别网络的目标函数;重复交替对判别网络和分割网络进行迭代训练,完成对总体网络的联合训练;
4)、将测试集ttest通过步骤1)步骤2)进行处理得到测试输入数据
所述的步骤3)中,
对于总体网络的训练,包括判别网络的训练和分割网络的训练:
对于判别网络的训练,其优化目标为最小化如式(b)所示的损失ld:
其中yn=0,是指该数据来自分割网络,yn=1,是指该数据来自真实标签;分割网络的输入为c通道的类概率图;对于真实标签yn,使用one-hot编码方式构建概率图pn,其中
对于分割网络的训练,其优化目标(c)为lseg:
lseg=lce+λadvladv+λsemilsemi(o)
其中lce,ladv和lsemi分别空间多类交叉熵损失,对抗损失和半监督损失;λadv和λsemi分别为权重的参数;
对于ttrain-label,分割网络得到的预测结果为pn=s(xn),交叉熵通过公式(d)得到lce:
ladv通过公式(e)得到ladv:
对于对抗损失,通过最优化分割网络得到的分割结果作为判别网络的输入;
对于ttrain-no-label,本发明使用半监督学习策略进行网络训练,给定输入数据,判别网络产生置信图d(pn)(h,w,1),其意义是指预测的识别结果与真实标签分布的相似结果;本发明对置信图采用二值化后得到可信的区域,该置信区域可作为“带标签数据”对整个网络进行监督自学习:
其中i(·)为指示函数,
本发明使用置信图对网络进行自学习,采用半监督学习策略,能突破带标签数据不足的限制;使用分割网络替代传统的传统网络,可接受不同大小的输入特征,灵活性强。
下面结合附图和具体实施方式对本发明进行详细说明。
第一部分:
说明本发明方法完整的步骤
数据说明:
本实例采用公开的数据集bonirobdataset作为实验数据,该数据集由bosch公司开发的deepfieldrobotic在柏林附近的甜菜园采集而来,该数据集共包括10万张甜菜园的图像(包括nir+rgb),本实例选取其中900张图像(其中283张为带标签的图像,剩余617张图像为无标签数据)作为数据集,数据集之中包括的田间对象共有3类,包括土壤、杂草及甜菜;
数据预处理:
为了去除噪音,本实例使用了小波变化中的‘db1’小波基将波长信号分解到6层,仅仅保留6层的高频信号,并使用该高频信号对原信号进行重构,有效的去除了基底噪音对图像的影响;接着,处理后的图像随机划分为ttrain-label(200张)和无标签数据集ttrain-no-label(417张),ttest(83张);
网络训练:
本实例所使用的网络包括分割网络和判别网络,分割网络采用由chenlc,zhuy,papandreoug,etal.encoder-decoderwithatrousseparableconvolutionforsemanticimagesegmentation[j].2018提出的带有xception65的deeplabv3+,分割网络中的默认参数参见chenlc,zhuy,papandreoug,etal.encoder-decoderwithatrousseparableconvolutionforsemanticimagesegmentation[j].2018;判别网络包括5个卷积层(核大小4×4,通道数为{64,128,512,1},步长为2);除过最后一层,剩余的4个卷积层末尾均使用参数为0.2的leaky-relu,为了将网络转化为全卷积网络,本实例在最后一层通过上采样使输出和输入大小相等,此外,因批正则化的操作会降低网络的不稳定性,本实例将不采用批正则化层。
训练分割网络时,本实例使用带有nesterov加速器的随机梯度下降方法对目标函数进行优化,其中动量(momentum=0.9),权重衰减(weightdecay=10-4),初始化学习率为2.5×10-4,并随着幂为0.9进行多项式衰减。训练判别网络时,本实例使用adam方法对目标进行优化,初始化学习率为10-4,并随着幂为0.9进行多项式衰减,动量(momentum=0.9)。对整个网络进行训练时,本实例设定
数据预测:
本实例使用83张ttest田间图片对上述训练模型,采用步骤4)对模型性能进行预测,如式(g)所示,iou(intersectionoverunion)是图像分割领域常见的评价指标,iou越接近1,模型效果越好,本实例平均83张图像的iou,得出结果为94.5%。
利用本发明中叙述的方法对采集到田间作物的区域进行识别,能够确定田间不同对象的分布区域。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!