一种千万级存量数据的处理、日志收集及导入数据库的方法与流程
本发明涉及一种千万级存量数据的处理、日志收集及导入数据库的方法,属于海量数据处理技术领域。
背景技术:
系统之间在对接数据的时候,数据之间的格式,数据字段,长度命名各不同。需要关联起来,就必须通过脚本导入的方式,将数据导入到对接系统当中;在这过程中,往往数据量很大,就需要从逻辑判断,性能分析、导入效率等方面,考虑方案的可行性。
目前在进行海量数据导入时,存在许多不足之处:(1)在进行千万级存量数据导入过程中,当出现导入错误时,进程会终断,需要分析错误原因并从新开始导入,重复性工作量大,导入效率低;(2)在导入过程中,会遇到网络请求堵塞问题,导致进程终断;(3)服务器的性能低,临时数据日志占用内存大,影响导入效率;(4)导入数据执行效率低等问题。
技术实现要素:
本发明要解决的技术问题是提供本一种千万级存量数据的处理、日志收集及导入数据库的方法,可以克服现有技术的不足。
为解决上述技术问题,本发明是通过以下技术方案实现的:一种千万级存量数据的处理、日志收集及导入数据库的方法,包括:
s1、导出千万级存量原始数据,并将千万级存量原始数据分割为多个小文件,使其批量导入数据库内;在导入时通过逻辑程序收集错误日志,使其还原成原始数据格式,从新进行导入操作;
s2、导入数据中断时,通过脚本程序自动分析数据导入中断原因,待查到原因之后,脚本启动继续导入数据;
s3、通过cmsmanageservice.php接口记录临时数据日志,并通过新屏蔽接口将记录数据导入数据库内;导入时通过逻辑程序收集错误日志,使其还原成原始数据格式,并从新进行导入操作。
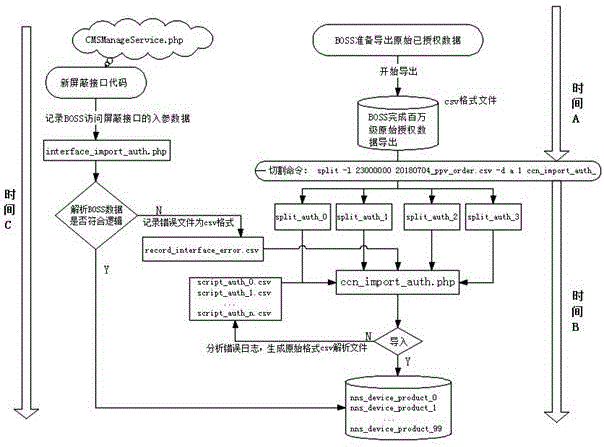
前述步骤s1中,从服务器上的boss系统导出千万级csv格式文件,并且在服务器上设置切割命:split-l2300000020180704_ppv_order.csv-da1ccn_import_auth_,将boss系统导出来的千万级数据切割成多个小文件,批量导入。
将前述boss系统导出来的千万级数据切割成4个以上小文件。
前述步骤s1中,在服务器上设置ccn_import_auth.php脚本程序和逻辑程序,将切割成的多个小文件通过ccn_import_auth.php脚本程序分析后,再通过逻辑程序进行逻辑判断,如果运行正确,则将数据导入到mysql数据库中;如若发生逻辑错误,将收集、分析错误日志,并还原错误的原始数据行,生成script_auth_0.csv,script_auth_1.csv…script_auth_n.csv文件,重新进入ccn_import_auth.php脚本程序分析,再次进入逻辑程序进行逻辑判断,直到不产生错误日志为止。
前述步骤s2中,通过ccn_import_auth.php脚本程序分析数据导入中断原因,待查到原因之后,脚本启动,继续将数据导入mysql数据库。
前述步骤s3中,在服务器上设置cmsmanageservice.php接口,通过cmsmanageservice.php接口记录临时数据日志。
将前述记录的临时数据日志的原始数据通过php语言yield生成器读取大文件,再通过动态args传入参数,最后通过unset销毁变量命令在反复导入的过程中释放所占大量内存。
在前述服务器上设置interface_import_auth.php脚本程序,记录的临时数据日志通过新屏蔽接口导出,经interface_import_auth.php脚本程序分析后,进入步骤s1中的逻辑程序进行逻辑判断,重复步骤s1的导入操作。
与现有技术比较,本发明公开了一种千万级存量数据的处理、日志收集及导入数据库的方法,其包括导出千万级存量原始数据,并将千万级存量原始数据分割为多个小文件,使其批量导入数据库内,导入时通过逻辑程序收集错误日志,使其还原成原始数据格式,从新进行导入操作;数据导入中断时,通过脚本程序自动分析导入中断原因,待查到原因之后,脚本启动继续导入数据;通过cmsmanageservice.php接口记录临时数据日志,并通过新屏蔽接口将其导入数据库,导入时通过逻辑程序收集错误日志,使其还原成原始数据格式,并从新进行导入操作。
本发明可以实现快速将千万级存量数据导入数据库,其具有以下优点:
(1)将千万级存量原始数据分割为多个小文件,使其批量导入数据库内,方便管理,并且避免数据库表锁,提高效率。
(2)在千万级存量数据导入时,增加了数据分析脚本程序和逻辑程序,对传入参数做校验、逻辑判断,是否符合导入条件,如果符合,直接导入数据库;不符合,将错误日志还原成为原始数据格式重新进行分析导入,其不用再次导入初始的存量数,只需分析完详细的错误日志,再将还原的错误数据继续用脚本导入即可,可避免重复性工作,提高导入效率。
(3)解决了网络请求堵塞时数据导入终断的问题,通过增加的数据分析脚本程序,可以分析中断原因,并实现自动启动继续将数据导入数据库。
(4)缓解了临时数据日志占用内存的压力,通过cmsmanageservice.php接口记录临时数据日志,并通过php语言yield生成器读取大文件特性,动态args传入参数,unset销毁变量命令,释放数据反复导入的过程中所占大量内存。
附图说明
图1为本发明的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述:
如图1所示,一种千万级存量数据的处理、日志收集及导入数据库的方法,包括:
s1、导出千万级存量原始数据,并将千万级存量原始数据分割为多个小文件,使其批量导入数据库内;在导入时通过逻辑程序收集错误日志,使其还原成原始数据格式,从新进行导入操作;
s2、导入数据中断时,通过脚本程序自动分析数据导入中止原因,待查到原因之后,脚本启动继续导入数据;
s3、通过cmsmanageservice.php接口记录临时数据日志,通过新的屏蔽接口将记录数据导入数据库内,并且导入时通过逻辑程序收集错误日志,使其还原成原始数据格式,从新进行导入操作。
见图1,在服务器上设有boss系统,boss系统用于导出千万级csv格式文件。
时间a段,对服务器的原始数据进行鉴权、校验,使其成为授权原始数据。
从服务器上的boss系统导出千万级csv格式文件,并且在服务器上设置切割命:split-l2300000020180704_ppv_order.csv-da1ccn_import_auth_,将boss系统导出来的千万级数据切割成多个小文件,优选为4个以上小文件,以方便分批量导入和管理。
时间a->时间b段,对传入参数做逻辑判断,是否符合导入条件,如果不符合,需要将错误日志记录成详细的日志,同时还原不符合逻辑的数据,只需分析完详细的错误日志,再将还原的错误数据,还原成为原始数据格式,继续用脚本导入即可,当所有的数据导完之后,就不用再次导入初始的存量数,避免重复性工作。具体地,在服务器上设置逻辑程序,上述切割成的多个小文件通过ccn_import_auth.php脚本程序分析后,再通过逻辑程序进行逻辑判断,如果运行正确,则将数据导入到mysql数据库中;如若发生逻辑错误,将收集、分析错误日志,并还原错误的原始数据行,生成script_auth_0.csv,script_auth_1.csv…script_auth_n.csv文件,重新进入ccn_import_auth.php脚本程序分析,再次进入逻辑程序进行逻辑判断,直到不产生错误日志为止。
对于遇到网络请求堵塞的情况,为避免数据导入终断,通过ccn_import_auth.php脚本程序进行分析之后停下来,待查到原因之后,脚本启动,可继续将数据导入mysql数据库。
时间c段,在服务器上设有cmsmanageservice.php接口,用于记录海量临时数据日志。
通过cmsmanageservice.php接口对临时数据日志的数据进行可行性分析并记录;将记录的原始数据通过php语言yield生成器读取大文件,再通过动态args传入参数,最后通过unset销毁变量命令在反复导入的过程中释放所占大量内存。
采用新屏蔽接口将记录的数据经interface_import_auth.php脚本程序分析后,导入时间a->时间b段的逻辑程序进行逻辑判断,同上所述,将符合逻辑的数据经过筛选,由以上ccn_import_auth.php程序插入到mysql数据库中,不符合的则生成错误日志,并还原成原始数据格式,循环生成record_interface_error.csv文件,再次进入ccn_import_auth.php脚本程序、逻辑程序后,重复上述导入操作,直到不产生错误日志结束导入,其可以及时处理临时数据日志,可以防止因临时数据日志占用大量内存而影响导入效率。
- 还没有人留言评论。精彩留言会获得点赞!